

Five patterns to follow for data streaming architecture unlike relational databa...
source link: https://www.devbridge.com/articles/five-patterns-for-data-streaming-architecture-unlike-relational/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Five patterns to follow for data streaming architecture unlike relational databases
Vytautas Paulauskas
08.09.21
Data streaming architecture vs. traditional relational databases
As the technology sector advances, data is taking on more shapes and sizes than before. The first boundary for an enterprise to cross is stepping away from a relational database-centric software architecture towards data streaming. Data streaming, conceptually being just an ordered queue of unstructured records, provides a foundation for timely and scalable solutions to cope with increased demands for data collection, storage, and analysis. Data producers or writers are the subcomponents of an application that creates records (e.g., financial data, IoT sensor readings, e-commerce orders, fleet routing, pricing data, etc.) Data consumers or readers are the components that ingest queued records to provide immediate alerts/dashboards or produce enriched data sets to be used for a specific purpose.
These concepts, being unfamiliar to traditional database administrators and back-end developers, are further perplexed by new technical terms such as eventual consistency or windowed aggregation. Yet, the market for data streaming and analysis continues to expand year after year, along with the demand for technical professions who have mastered its technology. A recent interactive report published by CompTIA underscores the need, noting that demand for jobs in emerging infrastructure, emerging hardware, artificial intelligence, data, and next-gen cybersecurity has surged by 190% over the past five years. Similarly, Open Data Science published its job skills research which identified data engineering as the fastest-growing tech occupation in 2020. Among the usual suspects employing data-related positions (e.g., Amazon, Facebook, Apple, Tesla), ODSC listed Walmart, JPMorgan Chase, and CVS, reassuring that various sectors are converting how they think, design, develop, and operate data.
With the increased demand for data streaming services, this article explores the five most common architectural patterns unique to data streams compared to more traditional database systems.
1. Traditional database modeling vs. stream & record modeling
When a technical team faces traditional database modeling tasks, they will choose either a star or a snowflake data model for a data reporting solution, a relational or hierarchical data model for data entry applications, or a model derived from object/entity relations have defined for the application. Once a core model is selected, the team will start designing each database table by defining columns, data types, primary keys, relations between tables, and other constraints, if needed.
The core concept states that you need an individual data stream (sometimes referred to as a topic) for a particular data set in the data streaming world. Data streams do not have data conformity rules such as foreign keys or unique columns. It is up to the application layer that is producing data to ensure data is correct.
To better explain these concepts, let's look at an IoT-sensor-enabled application collecting data via various sensors from machinery used in agriculture (e.g., accelerometer, GPS, maintenance logs, humidity, air temperature, etc.) Depending on the hardware design, some may be emitted every N seconds, while others batched. The hardware will prescribe that some readings are merged into a single JSON record, while others (maintenance and operational logs) exist as plain text entries. Engineers building the data streaming solution need to account for variances and develop topic names, data types, expected volumes of data, and data samples. Recognizing that data flow and formats vary, engineers will need to design processing and data persistence components capable of merging different data formats and latencies of data coming through the system.
It is crucial to think ahead about the nature of data. For example, consider whether or not the data can be produced and consumed in parallel. On the one hand, there's an IoT or log collector solution where multiple devices emit data to be consumed concurrently on one side of the spectrum. However, when designing a data streaming solution that stores updates to master data (e.g., organizations, products, general ledger), the data does not change frequently and can be processed sequentially.
After choosing between parallel vs. sequential, the team needs to design which data field becomes the record key. A data stream solution for IoT sensor events may not need a record key, resulting in parallel data distribution via a round-robin algorithm. On the contrary, the data stream for warehouse records may use a product ID record key to ensure CRUD operations for a particular product remain sequential in a designated partition and for reading sequentially.
The team needs to determine the data type of the record key and value. Teams typically choose JSON format for value and a text string or a number for the key. Occasionally, teams use custom code to create binary representation for key or value. While doing so, they need to ensure codepages for text and endianness for number data matches on all custom implementations.
2. ACID vs. eventual consistency
In a traditional database world, software developers and DBAs are familiar with the ACID (Atomicity, Consistency, Isolation, Durability) concept and know the limitations of a particular application built and maintained. For example, they know that MySQL is more lax in terms of consistency and durability than Microsoft SQL or PostgreSQL. In other instances, they have strict requirements on isolation on their Oracle-based application, and to overcome anticipated performance hiccups needed to design a read-only replica DB for ad-hoc reporting.
A data streaming platform, such as Apache Kafka, AWS Kinesis, Microsoft Azure Event Hub, or a similar product will not be ACID-compliant. This is the sacrifice these platforms are intentionally making for better performance and fault tolerance. As data is distributed between multiple nodes, data stream developers work within constraints of eventual consistency. As opposed to strict consistency imposed by the ACID model, eventual consistency means that data changes take time to propagate from a producer to a streaming platform and a consumer. The time it takes for data to become available may vary even for identical batches of data. However, a distributed streaming platform ensures that eventually, all pieces will get in sync when accounted, anticipated, and prepared for in advance.
The output from the stream modeling exercise, where a team comes up with answers to parallel processing, data key uniqueness, types of data, security, latency, and other questions, will help set a good foundation for reliable, predictable data flow and processing.
Conduct small experiments with stream setup by fine-tuning replication factor, writer's (i.e., data producer's), and readers' (i.e., data consumer's) acknowledgment on data operation and checking if the outcome fits the application needs. It is easier to tune or recreate data streams at an early stage than rework them after a solution is live. Ensure that all applications that write or read from the data stream have retry routines, monitoring, logging, and asynchronous operations support.
3. Varied levels of SQL knowledge (advanced vs. basic)
Technical staff from a traditional relational database development will have a vast SQL (Structured Query Language) background. SQL, up to a certain standard, is supported in all major DB Management Systems (DBMS). Furthermore, every major vendor will have a superset SQL dialect specific to the platform (e.g., T-SQL on Microsoft SQL Server, PL/SQL on Oracle, PL/pgSQL on PostgreSQL).
Several data stream processing platforms are also supporting SQL. However, data stream developers need to understand that SQL support is usually pretty limited. It should be seen only as an alternative to expressing data filtering, transformation, aggregation operations via programmatic code. Lenses SQL by Lenses.io, Striim SQL by Striim, and ksqlDB by Confluent Inc, similar to DBMS vendors, offer limited, vendor-specific SQL support.
Still, a development team transitioning from traditional database development to stream applications will benefit from having SQL knowledge. They will be able to write simple SELECT statements with familiar WHERE, COUNT, HAVING constructs, and enrich them with vendor-specific syntax shown in the example below:
INSERT INTO orders_country_grouped
SELECT STREAM
o.country,
o.status,
SUM(od.quantityOrdered * od.price) AS total
FROM `order_details` AS od
INNER JOIN `orders` AS o
ON o._key = od._key
GROUP BY SLIDING(5,m), o.country
Knowing SQL is beneficial as the whole team understands the code, team members can rapidly prototype data projections. If results are sufficient, connect data stream outputs directly to applications via APIs/push notifications or pipe data back to traditional relational databases.
4. Release & rollback strategy vs. incremental & fault-tolerant deployments
Applications with relational databases use development and release workflows that have not changed for decades.
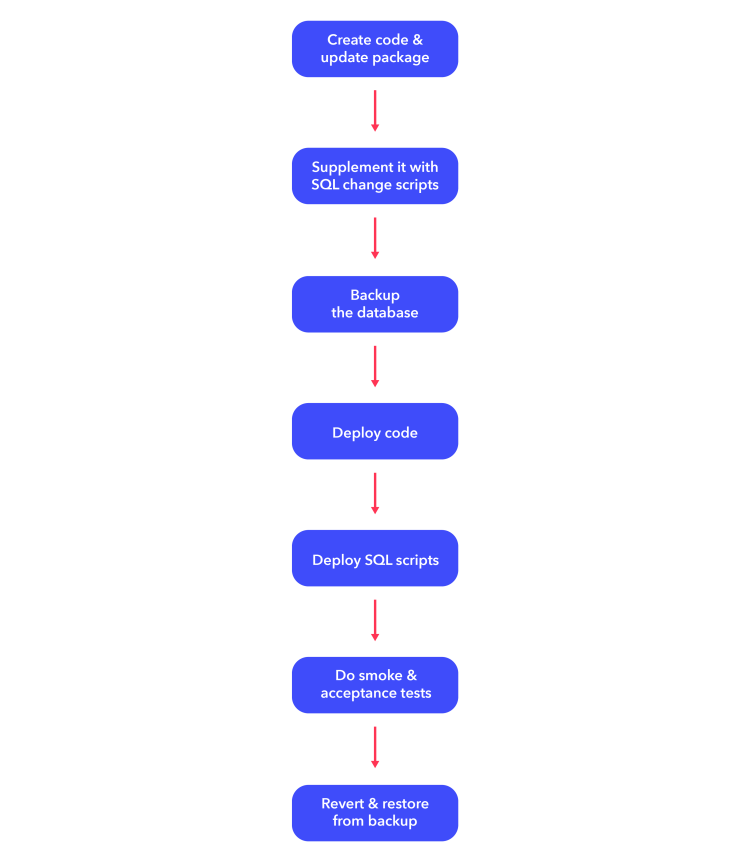
The approach works well and, unless the database is massive in size, is easy to recover from an unexpected failure.
With data streaming applications, a developer needs to be mindful that a stream will never contain all the data. It will include either the "last X days" worth of data or the latest record version (determined by the record key) if the record compaction feature is enabled. Having a limited set of data on a stream and organizing it in a queue-like data structure are cornerstones for achieving high volume and low latency on these types of systems. At the same time, it means that the development workflow needs to change to accommodate this philosophy shift.
Teams need to design data producers and consumers to be backward compatible and forward compatible.
A backward compatible approach is when an updated application can successfully read data created at an earlier point in time (either historical data or data created by another app still on an earlier data model).
A forward compatible approach is when an updated application can write data using a new model and still be read successfully by another application that has not yet been updated.
A recommended best practice is to update data consumers first with data producers changed on the subsequent deployment or vice versa. Never deploy all system updates at once. These components should go through thorough testing before being deployed. Luckily, data stream platforms have convenient tools (e.g., Kafka MirrorMaker) to offload some production data to the isolated environment for testing purposes.
Data stream developers should be aware that their applications need to be fault-tolerant. Temporary issues such as transient network issues or platform built-in capabilities such as data compaction or consumer rebalancing should not disrupt data application – it should retry data processing and come to a halt only if these issues persist. Built-in monitoring capabilities of data platforms can also help identify critical areas and types of failures when the support team must be alerted.
5. Limited use of a database vs. multiple use cases
Traditional, database-centric applications are usually limited to Create-Read-Update-Delete (CRUD) operations, being a backing store for transactional data or becoming an analytical warehouse for reporting data.
By comparison, data streaming platforms can be applied for multiple use cases depending on data origin and expected outcomes after data is processed.
1:1 producer-consumer system: In this scenario, a message forms after a business event occurs (e.g., a new order is created) and pushes to a data stream. A predefined application receives the message and updates stock / validates payment for fraud / sends emails etc.
Data collection and distribution platform: Data that originates from the source of truth database or API is stored in a data stream, which has a data compaction feature enabled. Contrary to the first use case, no finite set of data consumers are known at the time of design. Instead, various internal applications that already exist or plan to be developed in the future hook up to the data stream to build read replicas of data stored on the stream.
Internet of Things data aggregator: IoT devices typically have limited hardware capabilities. Thus, they cannot send vast amounts of data directly to data platforms such as Apache Kafka, Azure Event Hub, or Amazon Kinesis. IoT devices support lightweight MQTT protocol, which can forward sensor data via cloud provider (e.g., Azure or Amazon Web Services) IoT hubs. As most IoT sensor events are independent of each other, these events can be processed via data stream processing frameworks.
Log management solution: Although distributed logging and monitoring platforms such as NewRelic, Azure AppInsights, and AWS CloudWatch offer a modern way to manage operational logs in one place, many traditional applications still log data locally. Kafka Connect provides an excellent ecosystem to ingest logs from text files, Apache web server logs, or Linux syslog. The team can also explore Elastic Beats or similar log shipping solutions that are simpler to set up and have less flexibility than Kafka Connect.
In conclusion
Many businesses reliant on traditional database and application back-end recipes to build data-heavy applications would benefit from moving some data to a data stream. Research shows that pharmaceutical, technology, financial, consulting, and other sectors are looking to hire data engineers, data scientists, and emerging infrastructure engineers and are investing in modern data, cloud, and business intelligence platforms. Enterprises recognize the benefits and, as such, are investing in both maintaining and evolving the solutions.
While the technical team may be unfamiliar with some data streaming concepts, the approach to implementing solutions ranging from IoT data collection to build a new generation of data masters remains the same. Effort spent modeling data streams by deciding on key, value, data types, security, retention period, and other aspects will pay off in subsequent stages of implementation. Teams should familiarize themselves with the concept of eventual consistency, conduct experiments, and fine-tune for data reliability vs. speed of processing, depending on the nature of the data. SQL knowledge that the team has built over many years is transferrable as various data stream and processing platforms provide support for SQL syntax. As familiar database restore and rollback actions are not recommended while deploying data stream application components, teams should get accustomed to smaller, more frequent deployments which maintain data compatibility between component version upgrades.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK