

Making Public Information Secret
source link: https://rjlipton.wpcomstaging.com/2016/05/20/making-public-information-secret/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Making Public Information Secret
A way to recover and enforce privacy
Scott McNealy, when he was the CEO of Sun Microsystems, famously said nearly 15 years ago, “You have zero privacy anyway. Get over it.”
Today I want to talk about how to enforce privacy by changing what we mean by “privacy.”
We seem to see an unending series of breaks into databases. There is of course a huge amount of theory literature and methods for protecting privacy. Yet people are still broken into and lose their information. We wish to explore whether this can be fixed. We believe the key to the answer is to change the question:
Can we protect data that has been illegally obtained?
This sounds hopeless—how can we make data that has been broken into secure? The answer is that we need to look deeper into what it means to steal private data.
After The Horse Leaves The Barn
The expression “the horse has left the barn” means:
Closing/shutting the stable door after the horse has bolted, or trying to stop something bad happening when it has already happened and the situation cannot be changed.
Indeed, our source gives as its main example: “Improving security after a major theft would seem to be a bit like closing the stable door after the horse has bolted.”
Photo by artist John Lund via Blend Images, all rights reserved.
This strikes us as the nub of privacy. Once information is released on the Internet, whether by accident or by a break-in, there seems to be little that one can do. However, we believe that there may be hope to protect the information anyway. Somehow we believe we can shut the barn door after the horse has left, and get the horse back.
Suppose that some company makes a series of decisions. Can we detect if those decisions depend on information that they should not be using. Let’s call this Post-Privacy Detection.
Post-Privacy Detection
Consider a database that stores values 



Now say a decider is an entity 

The point here is that we can detect if 

Definition 1 Let a database contain values of the form
, and let
be a Boolean function. Say that the
part is effectively private for the decision
provided there is another function
so that
where
. A decider
respects
![\displaystyle \mathsf{Prob}[f(v,a)=g(v)] \ge 1-\epsilon,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BProb%7D%5Bf%28v%2Ca%29%3Dg%28v%29%5D+%5Cge+1-%5Cepsilon%2C+&bg=e8e8e8&fg=000000&s=0&c=20201002)
We can prove a simple lemma showing that this definition implies that
Lemma 2 If the database is secure for
such that
.
Proof: Suppose for contradiction such an 


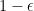



Pulling in the Long Reins
To be socially effective, our detection concept should exert influence on deciders to behave in a manner that overtly does not depend on the unauthorized information. This applies to repeatable decisions whose results can be sampled. The sampling would use protocols that effect transparency while likewise protecting the data.
Thus our theoretical notion would require social suasion for its effectiveness. This includes requiring deciders to provide infrastructure by which their decisions can be securely sampled. It might not require them to publish their 

What we can say now, however, is that there do exist ways we can rein in the bad effects of lost privacy. The horses may have bolted, but we can still exert some long-range control over the herd.
Open Problems
Is this idea effective? What things like it have been proposed?
Like this:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK