

学1个月爬虫就月赚6000?别被骗了,老师傅告诉你爬虫的真实情况!
source link: https://blog.csdn.net/zhiguigu/article/details/119183756
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

学1个月爬虫就月赚6000?别被骗了,老师傅告诉你爬虫的真实情况!
这是我前几天看到的一个真实事件,也是我写这篇文章的缘由:
前几天有粉丝跟我反馈说,某机构的人跟他说学爬虫1个月就能接单,让这小伙子去报名那个机构的爬虫课程,学完之后1个月就能把6000多的学费赚回来。可能是因为我和粉丝的交流比较多,所以小伙子找到了我,问我这个事情的真伪,我不禁咋舌…
学1个月爬虫就能去接单赚6000多块钱?现在的会爬虫的人数不胜数,新手学1个月就能达到月赚6000的水平了?
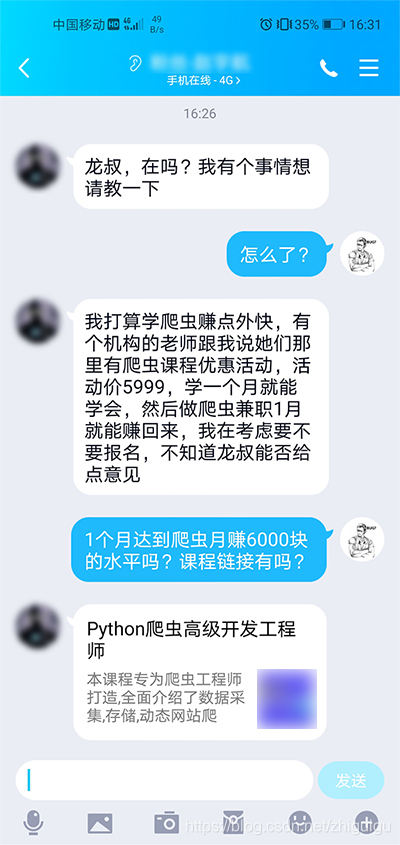
秉着客观的态度,就算不信我也没有去下结论,而是去看了一下他们的课程体系,结果不出我所料,课程大部分都在讲Python入门知识(函数等)、requests和XPath等内容,这不都是一些初级爬虫的知识吗?能月赚6000?怎么不教年轻人去街上抢钱呢?
赚外快的事情我也干了很多年,爬虫自然不在话下,那么今天我来说说5个深入一点的爬虫问题,让你清楚爬虫的真实情况:
1.现在的爬虫接单真能1个月赚6000的快外?
2.初级爬虫只能接一些小单,怎样才算初级爬虫水平?
3.中级爬虫是职业爬虫工程师上岗水平,需要具备什么?
4.高级爬虫可以说是爬虫大神,需要掌握哪些技术?
5.爬虫更高水平要学什么?巅峰爬虫是什么样子?
一、爬虫能否一个月赚6000的外快?
答案肯定是能的,但这取决于你的爬虫技术水平。
如果你只是一个初级爬虫你只能靠运气接单,你拿得出手的一些爬虫作品可能入不了大单金主的法眼,有时候接个技术难度高一点的,整出来效果都需要花费好几天,大多数初级爬虫的人接单都不会超过200块钱,大多数都是几十块钱的单子,月挣6000需要接多少单?我就算你一单的价格平均在100块钱,那你也是需要60单!
做过兼职的人都知道,1个月60单私活几乎是不可能的,除非你有特殊的渠道。
再者,抛开初级爬虫连产品经理都会之外,现在还有那么多第三方网站提供较强大的爬虫功能,不会爬虫的人花点小钱也能解决,比如某爪鱼、某裔采集器,不管是时间还是成本上都比找花钱请一个爬虫新手强。
新手学1个月爬虫就能月入6000块钱的事情,我敢打包票这只是为了促成你报班,这种手段在良莠不齐的互联网教育行业屡见不鲜,我直接给出我的结论:不值这个钱、学完你也做不到1月能靠爬虫赚6000,这水平就是给你1年也赚不了几个钱。
但如果你的技术达到了中级爬虫或更高的水平,那就是靠实力和运气来挣钱了。从技术层面上来讲,接大点的单是没有问题的,一单的价格也是在300~几千不等,如果是均价600元一单来算,一个月做个四五单赚几千块钱是没问题的,拼一点或者技术好一点的可能赚得更多,前提是你得有这个技术,打脸充胖子是会翻船的。
挣6000块钱是有可能的,几千块钱的单子以前我也做过。
至于去哪接单已是老生常谈了,这里我就不多说了,自己去百度吧,百度什么都有,我们继续下面的话题,来看看爬虫的初级、中级、高级和巅峰水平是什么样子!
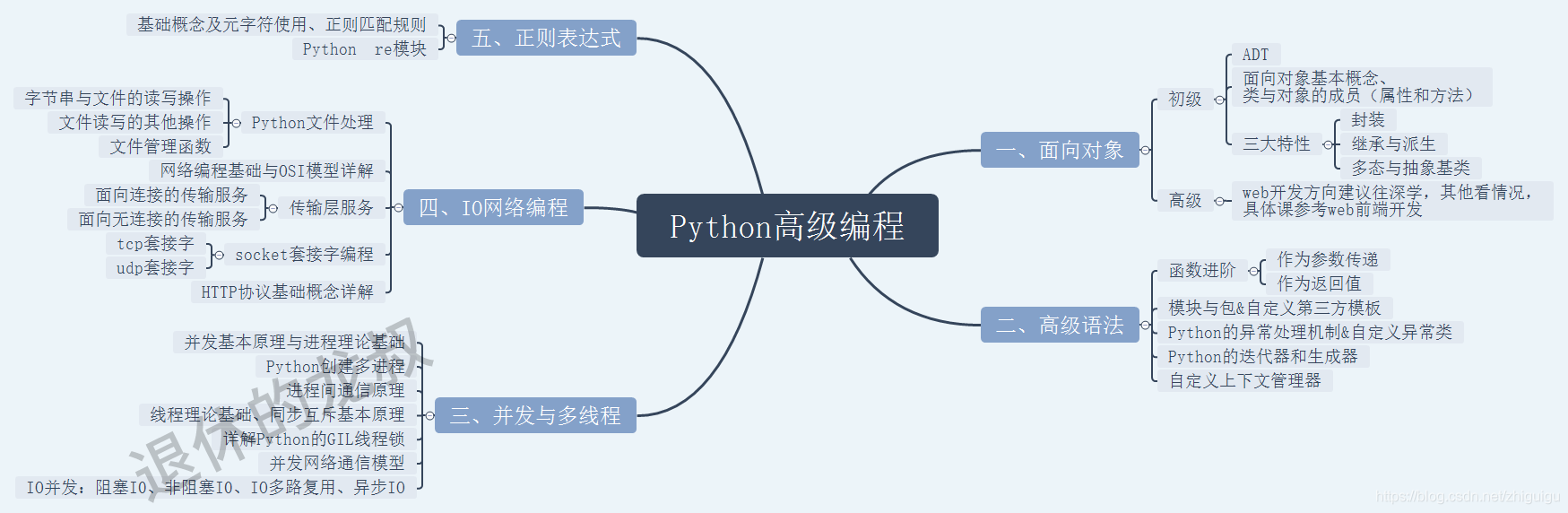
二、初级爬虫
根据我这些年来对爬虫的了解,初级爬虫的水平大概是这个样子的:
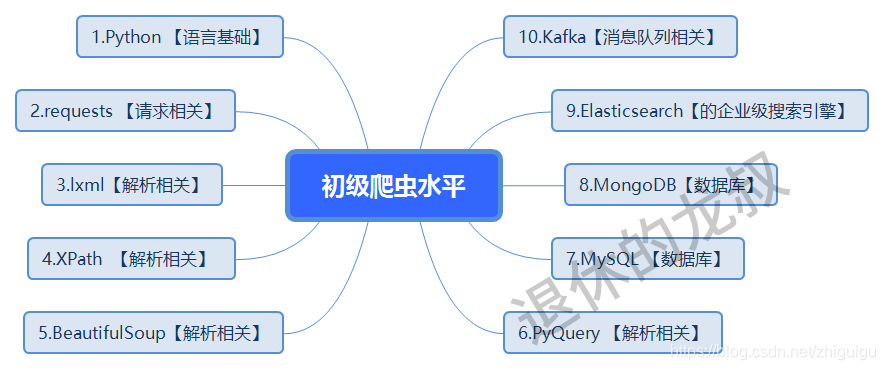
(最近盗图盗文的人比较,图片为了防止无良的CV大法就加了水印,需要源文件的可以私聊我。)
这个水平能干什么?就是爬虫一些基本的网站,涉及一点反爬就GG。
比如说我们去爬1个某个网站的文章,这个网站没有带反爬机制,那么用 requests 等库就够了,用 XPath、BeautifulSoup、PyQuery 或者正则表达式解析一下网页的源码,再加个文本写入存下来就完事了。
其中的难度并不大,无非是几个方法调用和循环加储存,如果存储方面稍微扩展一下的话,可以对接上 MySQL、MongoDB、Elasticsearch、Kafka 等等来保存数据,实现持久化存储。以后查询或者操作会更方便。
这就是初级爬虫的水平,能爬,但距离“可见即可爬”还道长路远,接单可想而知也会较吃力,虽然它很基础,但这又是你学爬虫的必经之路。
那么我们回顾一下前面那个小伙子的事情,上面这些东西对于新手来说1个月能学完吗?我觉得难度不小,我不说别的,就说Python入门这一块,就包含了不少的东西。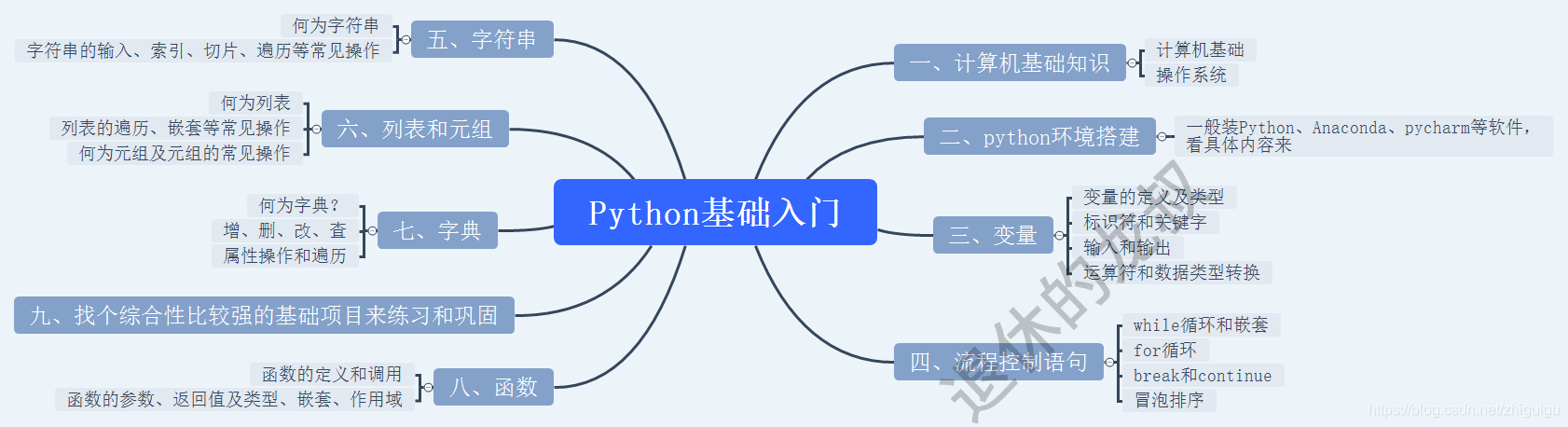
1天4个小时学习,没有基础的话,在Python入门这一块你可能就要花2周时间才能学完且稳固,剩下的两周,你能学完并掌握初级爬虫剩下的知识吗?
技术这条道路上很忌讳急功近利。我知道你可以从头到晚看完并理解一本书就只需要几天时间,但看完了你能用起来吗?看是看完了,但看了什么记不起来了,你需要反复练习,同样的,你1个月是能跟着学完没有问题,但你能不能站得稳还是个问题。
更何况,有些机构的课程都是挑肥拣瘦。
三、中级爬虫
中级爬虫的水平可以算是职业爬虫师的基本水平,除了初级爬虫的知识点之外,还应该掌握以下一些知识点:

1.爬取方式
当你的requests 不顶用的时候(爬下来的和网页显示的不一样),你就应该想到数据来源可能是 Ajax,你去分析网站的时候就得懂JavaScript ;如果想绕过分析 Ajax 和一些 JavaScript 逻辑的过程来爬取数据,我们就得用 Puppeteer、Pyppeteer、Selenium、Splash 等来模拟浏览器的方式来爬取。
2.爬取速度
除了爬取方式,还有爬取速度,这时候你就得有多进程、多线程、协程的知识储备了。
3.爬APP
如果你只会网页爬虫,那你还算不上中级爬虫的水平,你还得会爬APP,APP也占据着半壁江山。
这个时候你就得会Charles、Fiddler抓包了,抓到之后拿来模拟就行;如果接口被加密了,可以用 mitmproxy 直接监听接口数据或者走 Hook,比如上 Xposed 也可以拿到。
爬APP时还有一点比较重要,就是自动化爬取。如果是自己手动戳来实现爬虫的话,给再多钱也没用,这就不是个人干的活…比较好的解决方案就是adb工具和Appium ,你说该不该学?

四、高级爬虫
高级爬虫师不管是在职场还是兼职方面,都有着很大的优势,高级爬虫水平应该掌握以下几个方面的技术:
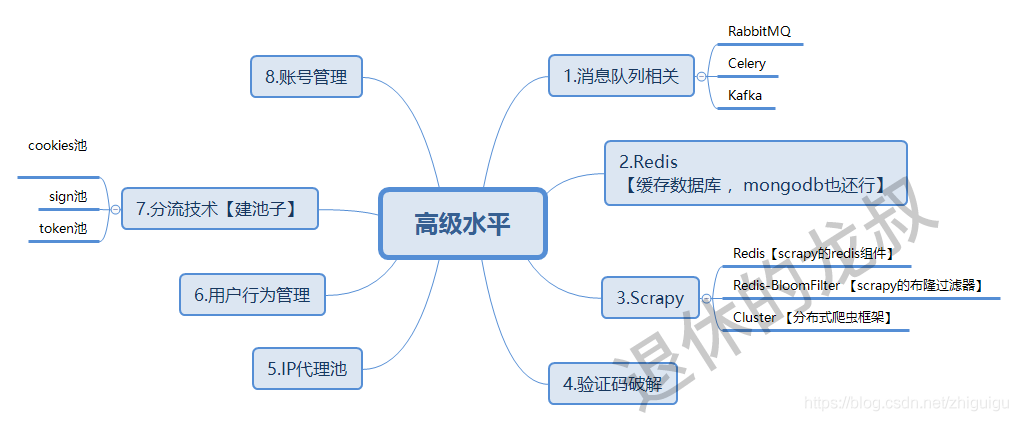
1.企业级爬虫
但凡是接触过大规模的爬虫的人都会有所体会到,多线程、多进程和协程虽然能够加快爬取速度,但说白了还是个单机的爬虫,比起更高级的分布式爬虫要逊色很多,分布式爬虫才算得上企业级爬虫。
分布式爬虫的重心就在于资源共享,那么我们很有必要去掌握的东西就是RabbitMQ、Celery、Kafka,用来这些基础的队列或者组件来实现分布式;其次就是我们大名鼎鼎的Scrapy爬虫框架,也是目前用的最多的爬虫框架,对于Scrapy的Redis、Redis-BloomFilter、Cluster 的理解和掌握是必不可少的。
掌握这些东西之后,你的爬虫才能达到企业级的高效率爬虫。

2.应对反爬的技术
高级爬虫水平应该考虑的另一个重心就是反爬。
网页反爬机制的常见操作就是验证码,什么滑块验证啊、实物勾选啊、加减法啊等等的,招式层出不穷,这个时候你就得知道如何去应付这些常见的验证码了。
还有反爬中常见的IP检测,搞不好就会封你的号,所以应对手法也是必须得有的,不管你是用免费代理还是付费代理来换代理IP,都是可以的。
以及应对反爬时的分流技术避免账号被封,分流技术就得建池子,Cookies 池、Token 池、Sign 池,都可以,有了池子之后,你被封的概率也会降低,你也不想爬个公众号结果WX被封了吧?

五、更高水平的爬虫(爬虫的巅峰)
更高水平的爬虫,以下4点是必会的内容:

1.JS逆向
为什么要学JS逆向爬取? 在反爬和反反爬的对抗中,用Selenium 等方式来爬也是可以,但效率还是低了,毕竟它模拟的是网页渲染的整个过程,而真实的数据可能仅仅就藏在一个小接口里,所以JS逆向则是更高级别的爬取技术,尤其是在大型网站的数据爬取,例如某多多和某宝,如果你能用JS逆向去爬下来,无疑是技术高超的证明之一,但JS逆向也不是谁都能修炼成的,确实烧头发。
APP的逆向就更不用说,网页可以逆向,APP也能逆向,那你配得上“牛逼”二字。
2.智能化爬虫
何为智能化爬虫? 举个例子,一般情况下,写一个爬取小说网站的爬虫,要根据不同的网站编写不同的提取规则,才能提取出想要的内容。而如果使用智能化解析的话,不论是哪个网站,你只需要把网页的url传递给它,就可以通过算法智能识别出标题、内容、更新时间等信息,而不需要重复编写提取规则。
智能化爬虫简而言之就是爬虫与机器学习技术相结合,使得爬虫更加智能化,不然的话,要爬1万个网站,难道我们要写1万个爬虫脚本?

3.爬虫与运维
爬虫什么时候与运维搭上关系了?它们俩一直都有着密不可分的关系,只是你的爬虫需求或者水平没有达到,所以不会考虑到它们。
爬虫与运维的关系主要体现在部署和分发、数据的存储和监控这几个方面。
比如说如何把1个爬虫快速部署到100台主机运行起来?比如怎样监控一些爬虫的占用内存和 CPU 状况?比如爬虫如何设置报警机制来保证爬虫项目的安全?
Kubernetes 、Prometheus 、Grafana是爬虫在运维方面用的比较多的技术,在做大点的爬虫项目时我也是经常拿它们来保驾护航。
4.爬虫的巅峰
什么是巅峰?可能永远都没有巅峰…只要一天没有拥有强者的发型(全秃),我就不敢说我看到了巅峰…
我隐约感到,爬虫做到了极致,既能干全栈,又能做数据分析,说不好还是算法大师,没准在人工智能还能有所建树,这难到就是爬虫的巅峰吗?
今日的分享就到这里,愿你我都能成为金字塔顶端的男人!
文章推荐:

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK