

基于决策树的特征重要性评估
source link: https://www.biaodianfu.com/feature-importance.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

在日常的建模过程中常常需要特征进行筛选,选择与模型相关度最高的特征,避免过拟合。通常使用的最多的方法是决策树中的feature_importance。
scikit-learn决策树
scikit-learn决策树类中的feature_importances_属性返回的是特征的重要性,feature_importances_越高代表特征越重要。feature_importances_属性,返回的重要性是按照决策树中被用来分割后带来的增益(gain)总和进行返回。
示例代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import ExtraTreesClassifier
wine = load_wine()
X_train, X_test, y_train, y_test = train_test_split(wine.data, wine.target, test_size=0.3)
# dtc = DecisionTreeClassifier()
# dtc.fit(X_train, y_train)
# importances = dtc.feature_importances_
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
importances = rfc.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(X_train.shape[1]):
print("%2d) %-*s %f" % (f + 1, 30, wine['feature_names'][f], importances[indices[f]]))
plt.title('Feature Importance')
plt.bar(range(X_train.shape[1]), importances[indices], color='lightblue', align='center')
plt.xticks(range(X_train.shape[1]), wine['feature_names'], rotation=90)
plt.xlim([-1, X_train.shape[1]])
plt.tight_layout()
plt.show()
1) alcohol 0.171172 2) malic_acid 0.157900 3) ash 0.147470 4) alcalinity_of_ash 0.130593 5) magnesium 0.103220 6) total_phenols 0.090347 7) flavanoids 0.049028 8) nonflavanoid_phenols 0.043786 9) proanthocyanins 0.026869 10) color_intensity 0.026426 11) hue 0.025300 12) od280/od315_of_diluted_wines 0.015860 13) proline 0.012030
在skleran中不管是分类还是回归,主要是决策树类型的算法都可以使用上述方法。
XGBoost
XGBoost同样是基于决策树的算法。XGboost同样的存在feature_importances_属性。与scikit-learn中决策树不同的是feature_importances_输出的重要性与模型超参数设置的importance_type相关。importance_type可选值:
- weight:该特征被选为分裂特征的次数。
- gain:该特征的带来平均增益(有多棵树)。在tree中用到时的gain之和/在tree中用到的次数计数。gain = total_gain / weight
- cover:该特征对每棵树的覆盖率。
- total_gain:在所有树中,某特征在每次分裂节点时带来的总增益
- total_cover:在所有树中,某特征在每次分裂节点时处理(覆盖)的所有样例的数量。
另外XGBoost提供了一个内置的plot_importance()方法可按重要性绘制特征。
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from xgboost import plot_importance
from xgboost import XGBClassifier
wine = load_wine()
X_train, X_test, y_train, y_test = train_test_split(wine.data, wine.target, test_size=0.3)
cls = XGBClassifier(importance_type='gain')
cls.fit(X_train, y_train)
cls.get_booster().feature_names = wine['feature_names']
importances = zip(wine['feature_names'], cls.feature_importances_)
for f in importances:
print(f)
plt.barh(wine['feature_names'], cls.feature_importances_)
plt.show()
plot_importance(cls, importance_type='gain')
plt.show()
LightGBM
LightGBM同样是决策树算法。LightGBM同样提供feature_importances_属性,使用feature_importances_之前需要设置模型超参数importance_type。与xgboost不同的是这里只有2个选项:
- split就是特征在所有决策树中被用来分割的总次数。(默认)
- gain就是特征在所有决策树种被用来分割后带来的增益(gain)总和
另外LightGBM提供feature_importance()方法,效果同feature_importances_。lightgbm也提供plot_importance()方法直接绘图。
代码示例:
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import lightgbm as lgb
import seaborn as sns
import pandas as pd
wine = load_wine()
X_train, X_test, y_train, y_test = train_test_split(wine.data, wine.target, test_size=0.3)
cls = lgb.LGBMClassifier(importance_type='gain')
cls.fit(X_train, y_train)
# importances = zip(wine['feature_names'], cls.feature_importances_)
# for f in importances:
# print(f)
importances = zip(wine['feature_names'], cls.booster_.feature_importance(importance_type='gain'))
for f in importances:
print(f)
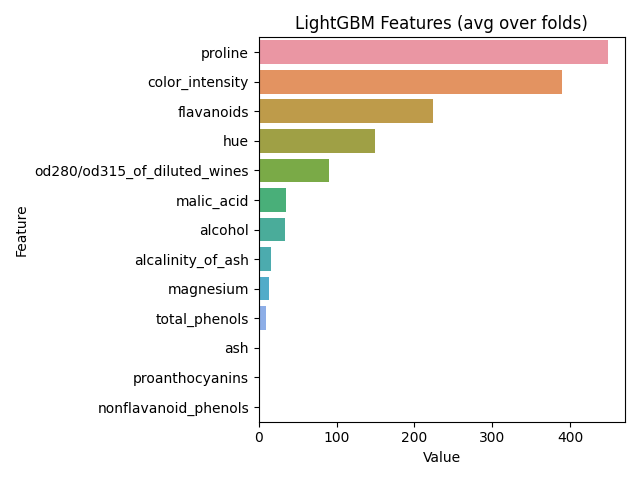
feature_imp = pd.DataFrame(sorted(zip(cls.feature_importances_, wine['feature_names'])), columns=['Value', 'Feature'])
plt.figure(figsize=(20, 10))
sns.barplot(x="Value", y="Feature", data=feature_imp.sort_values(by="Value", ascending=False))
plt.title('LightGBM Features (avg over folds)')
plt.tight_layout()
plt.show()
lgb.plot_importance(cls.booster_, importance_type='gain')
plt.show()
Recommend
-
75
决策树模型
-
63
决策树 (decision tree)
-
40
-
41
-
9
缘起 在解决回归和分类问题的时候,一般会使用Random Forest、GBDT、XGBoost、LightGBM等算法,这类算法因为性能好,被业界广泛采用。突然想到树类型的算法都需要明白一个基本问题,树是如何选择特征和分裂点...
-
6
用 XGBoost 在 Python 中进行特征重要性分析和特征选择
-
1
Mr.Feng BlogNLP、深度学习、机器学习、Python、Go如何评估LSTM每个时间步的重要性?如何评估LSTM每个时间步的重要性?这是一个很久很久以前做的实验,鉴于做了一...
-
2
全面评估北京当前流行株BF.7的病毒学特征,疫苗及单抗防治效果
-
4
机器学习算法(五):基于企鹅数据集的决策树分类预测 1 逻决策树的介绍和应用 1.1 决策树的介绍 决策树是一种常见的分类模型,在...
-
6
2023-06-12
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK