

如何做分库分表,常见方案汇总
source link: https://my.oschina.net/jiagoujingjin/blog/5154817
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

我是架构精进之路,大厂架构师,CSDN博客专家,点击上方“关注”,坚持每天为你分享技术干货,私信我回复“01”,送你一份程序员成长进阶大礼包。
一、为啥要分库分表
不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务服务来看就是,可用数据库连接少甚至无连接可用,那导致的问题就可以想象了吧:并发量、吞吐量、崩溃等等情况。
我们来按不同问题来区分看待:
1、IO瓶颈
第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度,建议解决方案:分库和垂直分表。
第二种:网络IO瓶颈,请求的数据太多,网络带宽不够,建议解决方案:分库。
2、CPU瓶颈
第一种:SQL问题,如SQL中包含join,group by,order by,非索引字段条件查询等,增加CPU运算的操作,建议解决方案:SQL优化,建立合适的索引,将SQL计算转移到业务Service层。
第二种:单表数据量太大,查询时扫描的行太多,SQL效率低,CPU率先出现瓶颈,建议解决方案:水平分表。
二、分库分表常见方案
1、水平分库
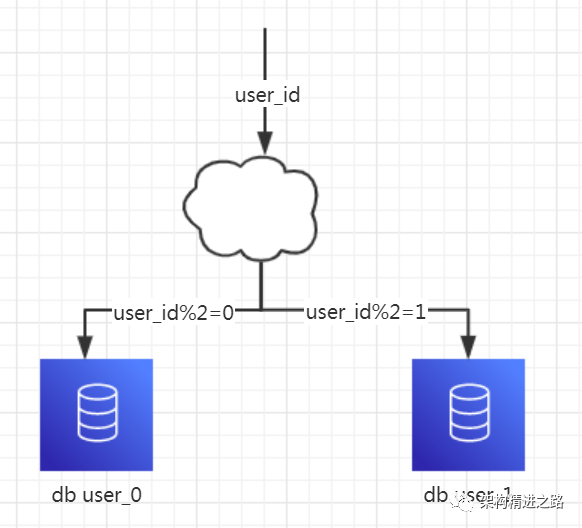
1、概念: 以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
2、结果:
-
每个库的结构都一样
-
每个库中的数据不一样,没有交集
-
所有库的数据并集是全量数据
3、场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库的情况下。
4、分析:库多了,io和cpu的压力自然可以成倍缓解
2、水平分表
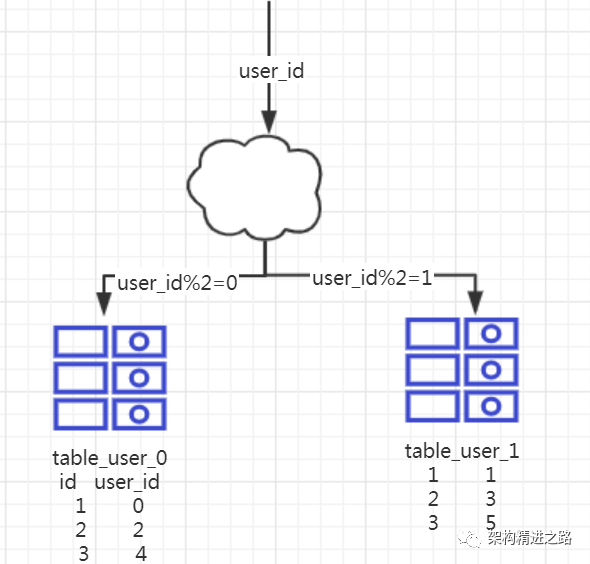
1、概念: 以字段为依据,按照一定策略(hash、range等),讲一个表中的数据拆分到多个表中。
2、结果:
-
每个表的结构都一样
-
每个表的数据不一样,没有交集,所有表的并集是全量数据。
3、场景:系统绝对并发量没有上来,只是单表的数据量太多,影响了SQL效率,加重了CPU负担,以至于成为瓶颈,可以考虑水平分表。
4、分析:单表的数据量少了,单次执行SQL执行效率高了,自然减轻了CPU的负担。
3、垂直分库
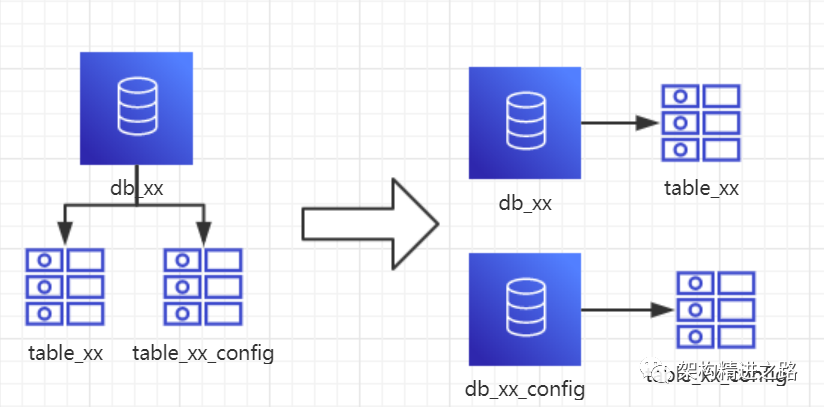
1、概念: 以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
2、结果:
-
每个库的结构都不一样
-
每个库的数据也不一样,没有交集
-
所有库的并集是全量数据
3、场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块的情况下。
4、分析:到这一步,基本上就可以服务化了。
例如:随着业务的发展,一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化。再者,随着业务的发展孵化出了一套业务模式,这时可以将相关的表拆到单独的库中,甚至可以服务化。
4、垂直分表
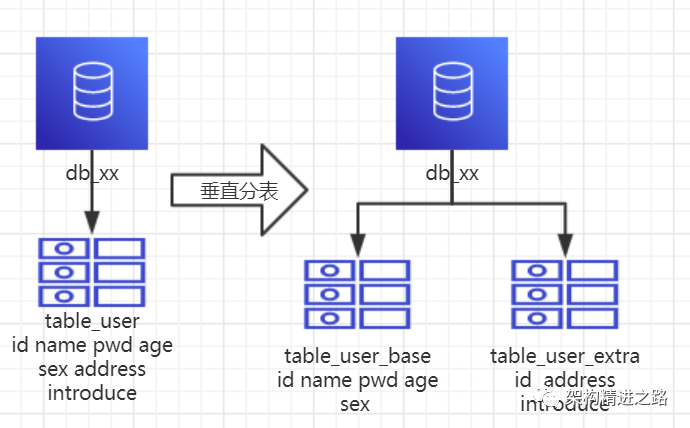
1、概念: 以字段为依据,按照字段的活跃性,将表中字段拆到不同的表中(主表和扩展表)。
2、结果:
-
每个表的结构不一样。
-
每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据。
-
所有表的并集是全量数据。
3、场景:系统绝对并发量并没有上来,表的记录并不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大,以至于数据库缓存的数据行减少,查询时回去读磁盘数据产生大量随机读IO,产生IO瓶颈。
4、分析:可以用列表页和详情页来帮助理解。垂直分表的拆分原则是将热点数据(可能经常会查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表,这样更多的热点数据就能被缓存下来,进而减少了随机读IO。拆了之后,要想获取全部数据就需要关联两个表来取数据。
但记住千万别用join,因为Join不仅会增加CPU负担并且会将两个表耦合在一起(必须在一个数据库实例上)。关联数据应该在service层进行,分别获取主表和扩展表的数据,然后用关联字段关联得到全部数据。
三、总结
分库分表,首先得知道瓶颈在哪里,然后才能合理地拆分(分库还是分表?水平还是垂直?分几个?如何分?)。
分库分表能有效缓解单机和单表带来的性能瓶颈和压力,突破网络IO、硬件资源、连接数的瓶颈,同时也带来一些问题,切记不可为了分库分表而拆分。
🎉 福利:关注公众号回复关键字:MySQL,即可免费获取《高性能MySQL 第3版》一套
·················· END ··················
关注公众号,免费领学习资料
十年研发路,大厂架构师,CSDN博客专家
专注架构技术学习及分享,职业与认知升级
坚持分享接地气儿的干货,期待与你一起成长

「架构精进之路」专注架构研究,技术分享
点“赞”和“在看”哦
本文分享自微信公众号 - 架构精进之路(jiagou_jingjin)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK