

How to Aggregate Categorical Replies via Crowdsourcing (Demo from ICML 2021)
source link: https://hackernoon.com/how-to-aggregate-categorical-replies-via-crowdsourcing-demo-from-icml-2021-8u4j37hz
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

@dustalovDmitry Ustalov
Ph.D. in Natural Language Processing | Crowdsourcing
Hello everyone, today I’ll show you how to perform results aggregation in crowdsourcing. We will aggregate categorical responses with the help of two classical algorithms – Majority Vote and Dawid-Skene.
I’ll be using Crowd-Kit, an open-source computational quality control library that offers efficient implementations of various quality control methods, including aggregation, uncertainty, agreements, and more. But feel free to use any of the alternatives: spark-crowd (which uses Scala instead of Python), CEKA (Java instead of Python), or Truth Inference (which uses Python but provides only categorical and numeric responses and doesn’t have an all-in-one API). Crowd-Kit is designed to work with Python data science libraries like NumPy, SciPy, and Pandas, while providing a very familiar programming experience with well-known concepts and APIs. It’s also platform agnostic. As soon as you provide the data as a table of performers, tasks, and responses, the library will deliver high-quality output regardless of the platform you use.
In my demonstration, we will aggregate some responses provided by crowd performers. For the project, they had to indicate whether the link to a target website was correct or not. Given that we asked multiple performers to annotate each URL, we needed to choose the correct response, considering performers’ skills and task difficulties. This was why we need aggregation. It’s a vast research topic, and there are many methods available for performing this task, most of which are based on probabilistic graphical models. Implementing them efficiently is another challenging task.
My demo will use Google Colab, but any other Python programming environment would work fine. First, we need to install the Crowd-Kit library from the Python Package Index. We’ll also need annotated data. We’ll be using Toloka Aggregation Relevance datasets with two categories: relevant and not relevant. These datasets contain anonymized data that is safe to work with. I’ll use the Crowd-Kit dataset downloader to download them from the Internet as Pandas data frames. Again, feel free to use a different source of annotated data; open datasets are, naturally, fair play as well. Now we’re ready to go.
%%capture
!pip install crowd-kitfrom crowdkit.datasets import load_datasetdf, df_gt = load_dataset('relevance-2')So the data has been downloaded, and before we move forward, let’s have a look at the dataset.
df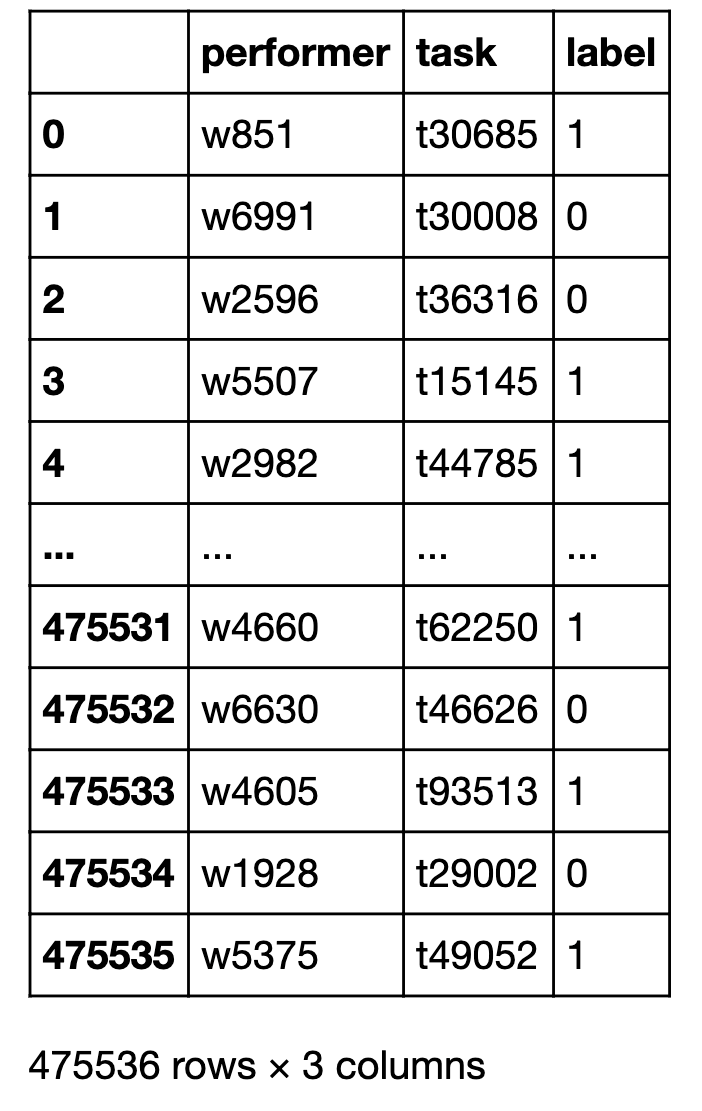
The Pandas data frame with the crowdsourced data
df_gttask
t30006 0
t33578 0
t22462 1
t52093 0
t26935 0
..
t57345 1
t81052 1
t7189 1
t80463 0
t93643 0
Name: label, Length: 10079, dtype: int64The load_dataset function returns a pair of elements. The first element is the Pandas data frame with the crowdsourced data. The second element is the ground truth dataset, whenever possible. The data frame, or df, has three columns: performer, task, and label. The label is set to 0 if the document is rated as non-relevant by the given performer in the given task, otherwise the label will be 1. The ground truth dataset df_gt is a Pandas series that contains the correct responses to the tasks put to the index of this series. Let's proceed to the aggregation using majority vote, a very simple heuristic method.
We import three aggregation classes: Majority Vote, Wawa, and Dawid-Skene.
from crowdkit.aggregation import MajorityVote, Wawa, DawidSkeneThen we create an instance of Majority Vote and call the fit_predict method to perform majority vote aggregation of our data.
agg_mv = MajorityVote().fit_predict(df)
agg_mvtask
t0 1
t1 1
t10 1
t100 0
t1000 0
..
t9995 1
t9996 0
t9997 0
t9998 0
t9999 1
Length: 99319, dtype: int64This simple heuristic works extremely well, especially on small datasets, so it’s always a good idea to try it. Note that the ties are broken randomly to avoid bias towards the first occurring label.
However, the classical majority vote approach does not take into account the skills of the performers. But sometimes it’s useful to weigh every performer's contribution to the final label proportionally to their agreement with the aggregate. This approach is called Wawa, and Crowd-Kit also offers it. Internally, it computes the majority vote and then re-weights the performers’ votes with the fraction of responses matched to that majority vote.
agg_wawa = Wawa().fit_predict(df)
agg_wawatask
t0 1
t1 1
t10 1
t100 0
t1000 0
..
t9995 1
t9996 0
t9997 0
t9998 0
t9999 1
Length: 99319, dtype: int64Now we perform the same operation with Dawid-Skene.
agg_ds = DawidSkene(n_iter=10).fit_predict(df)
agg_dstask
t30685 1
t30008 0
t36316 0
t15145 1
t44785 0
..
t95222 0
t83525 0
t49227 0
t96106 1
t16185 1
Length: 99319, dtype: int64This is another classical aggregation approach in crowdsourcing, which was originally designed in the 70s for probabilistic modeling of medical examinations. The code is virtually the same: we create an instance, set the number of algorithm iterations, call fit_predict, and obtain the aggregated results.
Let’s evaluate the quality of our aggregations. We will use the well-known F1 score from the scikit-learn library.
from sklearn.metrics import f1_scoreIn this dataset, the ground truth labels are available only for the subset of tasks, so we need to use index slicing. This allows us to perform model selection using well-known and reliable tools like Pandas and scikit-learn together with Crowd-Kit.
f1_score(df_gt, agg_mv[df_gt.index])0.7621861152141802f1_score(df_gt, agg_wawa[df_gt.index])0.7610675039246467f1_score(df_gt, agg_ds[df_gt.index])0.7883762200532387In our experiment, the best quality was offered by the Dawid-Skene model. Having selected the model, we want to export all of the aggregated data, which makes sense in downstream applications.
We’ll now use Pandas to save the whole aggregation results to a TSV file, after transforming the series to a data frame just to specify the desired column name.
agg_ds.to_frame('label').to_csv('test.txt')Let’s take a look inside it. The data is here, the responses are here, and the aggregation results are also here.
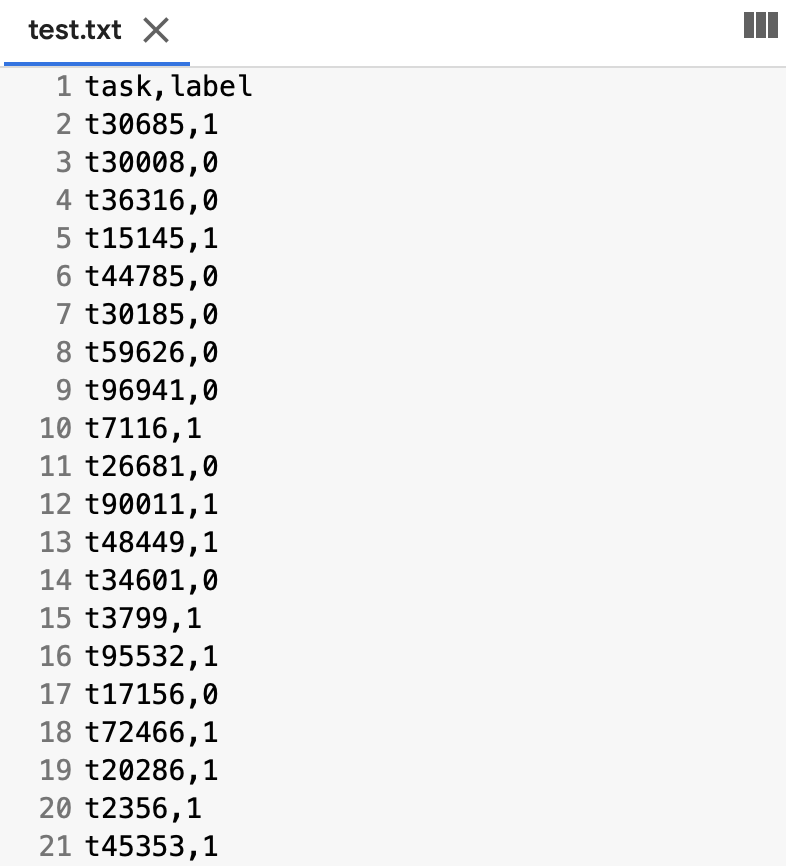
We’ve obtained aggregated data in just a few lines of code.
Great work!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK