

Predicting Chess and Horses
source link: https://rjlipton.wpcomstaging.com/2019/08/15/predicting-chess-and-horses/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Predicting Chess and Horses
Using predictivity both to sharpen and cross-check models
Patrice Miller and Jeff Seder look under the hide of horses. Their company EQB does predictive modeling for horse racing based on biometric data. They are famous for having advised the owner of American Pharoah not to sell because the horse had a powerful heart. In 2015, American Pharoah became the first Triple Crown winner since the also-hearty Secretariat in 1978.
Today I am happy to announce an extended version of my predictive model for chess and discuss how it gains accuracy by looking under the hood of chess positions.
I had thought to credit Charles Babbage and Ada Lovelace for being the first to envision computational predictive modeling, but the evidence connected to her design of betting schemes for horse racing is scant and secondhand accounts differ. It is known that Babbage compiled voluminous data on the medical fitness and diet of animals, including heart function by taking their pulse. We have discussed their computing work here and here.
I will use horse racing as a device for explaining the main new ingredient of my model. It sharpens the prediction of moves—and the results of cheating tests—by using deeper information to “beat the bookie” as Lovelace tried to do. I have described the basic form of my model—and previous efforts to extend it—in several previous posts on this blog. Last month, besides being involved in several media stories involving a grandmaster caught in the act of cheating in France, I was invited to discuss this work by Ben Johnson for his “Perpetual Chess” podcast.
Betting the Favorite
My chess model does the same thing to a chess position—given information about the skill set of the player deciding on a move—that a bookie does to a horse race. It sets odds on each legal move 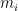
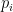

Suppose you don’t care how much money you might win but just want to maximize your chance of being right—of winning something. Unless you have reason to doubt the bookie, you should bet on the favorite. That is what my basic chess model does. Whichever move is given the highest value by the computer at the end of its search is declared the favorite, regardless of the player’s Elo rating or other skill factors.
That the best move—we’ll label it 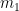
My basic model still makes it the favorite. This doesn’t mean its probability 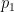


This is borne out in practice. The lowest Elo rating used by the World Chess Federation (FIDE) is 1000. Let’s take ratings between that and 1200 (which used to be the lowest rating) as denoting the novice class. Consider only those positions that have many reasonable choices—say at least ten moves valued within 0.25 (figuratively, a quarter of a pawn) of optimal. My main training set has 6.082 such positions in games between evenly-matched players of this level. Here are the frequencies of their playing the best through the tenth-best move in such many-choice positions:
Rank Pct.
1 17.76% 2 13.22% 3 9.95% 4 7.66% 5 6.25% 6 5.18% 7 4.41% 8 4.55% 9 3.50% 10 3.03% 11+ 24.49%
Both my basic model and the new one, when fitted over the entire training set for this class but then restricted to the many-choices subset, give projections close to these actual values. The basic model, always betting the favorite, is right on under 18% of its projections. Can we do better? That is, can we “beat the bookie” at chess?
Predicting Inferior Moves
It is almost four years since the idea for improving predictions was described on this blog. In place of “weaker players prefer weaker moves,” it advanced a hypothesis that we can state as follows:
Weaker players are more likely to be diverted by shiny objects.
Most in particular, they will fall for moves that look attractive early on, but which are revealed (by the computer) to be inferior after deeper consideration. The computer programs output values for each depth of search, and when these moves’ values are graphed against the depth, they start high but “swing down” at higher depths. Weaker players are more likely to be satisfied by the early flash and not think deeper. The old post has a great example of such a move from the pivotal game in the 2008 world championship match, where Viswanathan Anand set a deep trap that caught the previous world champion, Vladimir Kramnik.
The flip side are moves that look poor at low depths but whose high value emerges at high depths. My basic model, which uses only the final values of moves, gives too high a projection on these cases, and too low a likelihood of falling into traps. I have figured that these two kinds of ‘misses’ offset over a few dozen positions. Moreover, in both kinds of misses, the player is given express benefit of doubt by the projections. It is edgier, after all, to project that a player is more likely to fall into a trap than to find the safest and best move.
The effect of lower-depth values is still too powerful to ignore in identifiable cases. Including them, however, makes the whole model edgier, as I have described here before. Simply put, the lower-depth values are subject to more noise, from which we are trying to extract greater information. It has been like trying to catch lightning—or fusion—in a bottle.
Modest But Effective Success
My new model implements the “swing” feature without adding any more free parameters for fitting. It has new parameters but those are set “by hand” after an initial fitting of the free parameters under the “sliding-scale” regime I described last September, which is followed by a second round of re-fitting. It required heavy clamps on the weighting of lower-depth values and more-intense conditioning of inputs overall. It required a solution to the “firewall at zero” phenomenon that was the exact opposite of what I’d envisioned.
After all this, here is what it delivers in the above case—and quite generally:
It improves the prediction success rate—for the weakest players in the most difficult kind of positions to forecast—from 17.76% to 20.04%.
For the elite class—2600 to 2800—in the same kind of many-choice positions, the new model does even better. Much more data on elite players is available, so I have 49,793 such positions faced by them:
Whereas elite players found the best move in 30.85% of these difficult positions, my new model finds their move in 34.64% of them.
Over all positions, the average prediction gain ranges from about 1 percentage point for the lowest players to over 2% for masters. These gains may not sound like much, but for cheating tests they give prime value. The reasons are twofold:
- The gained predictions are all against their finding the computer’s move, so the act of finding the best move is more exposed.
- The standard deviation is typically 3–5 percentage points depending on the volume of moves. Thus the prediction gain can enhance the measured z-score by upwards of 0.5 or more.
Initial applications in recent cases seem to prove this out more often than not. Of course, the larger purpose is to have a better model of human chess play overall.
Cross-Checks and Caveats
In recent years, several new dimensions of quality and safety with predictive models have emerged. They supplement the two classic ones:
- Avoiding false positives. In particular, over a natural population (such as the mass of honest players), the rate of outlier scores generated by the model must stay within the bounds of natural frequency for the population. Call this “natural safety.”
- Avoiding false negatives. The model should provide enough statistical power to flag unnatural outliers without becoming unsafe.
I vetted my model’s natural safety by processing tens of millions of generated z-scores under resampling after my final design tweaks earlier this month. This was over a link between departmental machines and UB’s Center for Computational Research (CCR) where my data is generated. The previous discussion has all been about greater power. The first new factor updates the idea of calibration:
- Non-bias and fairness. More general than the societal context, which we discussed here, this means avoiding bias along functional lines that the model is not intended to distinguish.
I have a suite of cross-checking measures besides those tests that are expressly fitted to be unbiased estimators. They include checking how my model performs on various different types of positions, such as those with many choices as above, or the opposite: those having one standout move. For example, the model’s best-move projection in the many-choice positions by elite players, using the general settings for 2700 rating, is 31.07%. That’s within 0.28%. Another check is figuratively how much “probability money” my model wagered to get its 34.64% hit rate. The sum of
How well does your model perform on pertinent tests besides those it was expressly trained for?
Beyond fairness, good wide-range calibration alleviates dangers of “mission creep.”
The second newer factor is:
- Adversarial performance. This is apart from “natural safety.” Simply put: how resistant is the model to being deceived? Can it be gamed?
My impressions over the long haul of this work is that the new model’s more-powerful heart inevitably brings greater “springiness.” By dint of its being more sensitive to moves whose high value emerges only after deep search, it is possible to create shorter sequences of such moves that make it jump to conclusions. The z-score vetting turned up a few games that were agreed drawn after some “book” moves—openings known by heart to many professional players—whose entirety the model would flag, except for the standard procedure of identifying and removing book moves from cheating tests. These outliers came from over a hundred thousand games between evenly-matched players, so they still conformed to the natural rate, but one can be concerned about the “unnatural rate.” On the flip side, I believe my more-intensive conditioning of values has made the model more robust against being gamed by cheaters playing a few inferior moves to cover their tracks.
In general, and especially with nonlinear models, the caveat is that amplifying statistical power brings greater susceptibility to adversarial conditions. Trying to “beat the bookie” requires more model introspection. My model retains its explainability and ability to provide audits for its determinations.
Open Problems
What lessons from similar situations with other predictive models can be identified and brought to bear on this one?
Update 8/24: Here is a timely example of the tradeoff between amplifying the prediction accuracy and the overall stability of the model.
{kind=link}
Like this:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK