
1

百度搜索稳定性问题分析(下)
source link: https://my.oschina.net/u/4299156/blog/5139557
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


上周,在 《百度搜索稳定性问题分析的故事(上)》 中,已经介绍了我们是如何通过全面的数据系统建设解决问题追查的死角,没看过的朋友可以重新看下这篇文章。接下来,将分享我们如何进行故障的自动化、智能化分析,提高问题追查的效率。导读:百度搜索系统是百度历史最悠久、规模最大并且对其的使用已经植根在大家日常生活中的系统。坊间有一种有趣的做法:很多人通过打开百度搜索来验证自己的网络是不是通畅的。这种做法说明百度搜索系统在大家心目中是“稳定”的代表,且事实确是如此。百度搜索系统为什么具有如此高的可用性?背后使用了哪些技术?本文立足于大家所熟悉的百度搜索系统本身,为大家介绍其可用性治理中关于“稳定性问题分析”方面使用的精细技术,以历史为线索,介绍稳定性问题分析过程中的困厄之境、破局之道、创新之法。希望给读者带来一些启发,更希望能引起志同道合者的共鸣和探讨。
第4章 再创新:应用价值的再释放
4.1 巨浪——故障分析的“终点”
拒绝的分析是一个定性的过程,根据拒绝query激发的日志信息,就可以定位业务层面的原因,或者定位到引起异常的模块。 这个过程可以抽象为下面几步: (1) 故障(拒绝)信号的感知 (2) 故障单位(query)全量信息(日志)的收集 (3) 根据收集到的信息进行故障单位(query)的归因 (4) 对批量故障单位(query)的原因进行再归类,以及特征挖掘 整个过程需要在秒级完成,时效性要求很高。过程的顺利执行面临下面8个挑战: 挑战1: 如何实现快速的日志检索。在采集到拒绝信号之后,拒绝的分析需要快速拿到日志原文,这些信息如果直接从线上扫描,速度和稳定性上显然达不到要求。 挑战2: 拒绝定位的实时性和准确性之间的矛盾如何解决。日志越完整,拒绝原因的分析结果越准确。但是因为网络延迟等原因,分析模块无法保证马上拿到所有的日志。接收到拒绝信号后就开始分析,可以确保分析的实时性,但是准确性难以保证。而延迟一段时间再分析,可能会拿到更完整的日志,但是会影响拒绝分析的实时性。 挑战3: 如何准确全面地描述故障。生产环境的故障“五花八门”,如果逐个进行表达和管理,维护成本会非常高。需要寻找一种方案,把所有的故障(规则)系统、准确、全面地管理起来。 挑战4: 特征工程如何进行。在拿到日志原文之后,我们需要确定从日志中应该拿哪些信息,如何采集这些信息,并且以程序可以理解的方式将这些特征表达出来,最终和拒绝原因关联起来,即特征的选择、提取、表达和应用。 挑战5: 如何还原query现场。在线系统为了保证可用性,关键模块上都会有重查。在定位拒绝时,需要还原出完整的调度树,这样才能看到由根节点出发到叶子节点各条路径失败的原因,不然可能会得到矛盾的结果。如下图所示,A-1、B-1和B-2节点都发生了重查,当拼接错误时(C模块的实例挂到了错误的B模块节点下),B-1(或B-2)的错误状态和挂在它之下的C模块的日志状态可能是矛盾的,无法得出正确的定位结论。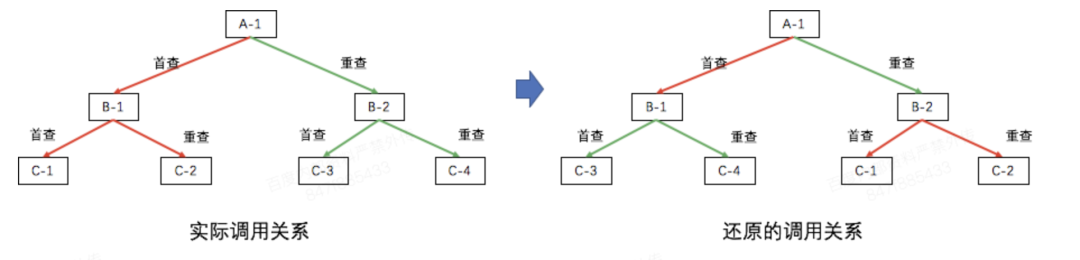 挑战6:
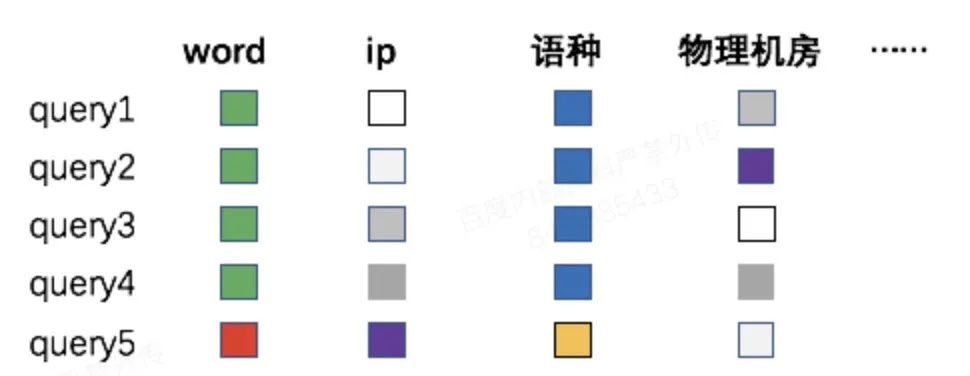
如何对拒绝特征进行深度挖掘。自动定位难以定位到根因,更精确的定位依赖人工参与的继续分析。分析工具需要能从各种拒绝中找到聚集特征并以一定的优先顺序展示给用户,为根因定位或者止损提供更多线索。query中可以提取的信息包括query的查询词(word),发送query的client端ip,query的语种或者处理query的机器所在的物理机房等。比如,当发现系统拒绝都和某个ip的攻击流量有关时,可以对该ip进行封禁止损。
挑战6:
如何对拒绝特征进行深度挖掘。自动定位难以定位到根因,更精确的定位依赖人工参与的继续分析。分析工具需要能从各种拒绝中找到聚集特征并以一定的优先顺序展示给用户,为根因定位或者止损提供更多线索。query中可以提取的信息包括query的查询词(word),发送query的client端ip,query的语种或者处理query的机器所在的物理机房等。比如,当发现系统拒绝都和某个ip的攻击流量有关时,可以对该ip进行封禁止损。
 挑战7:
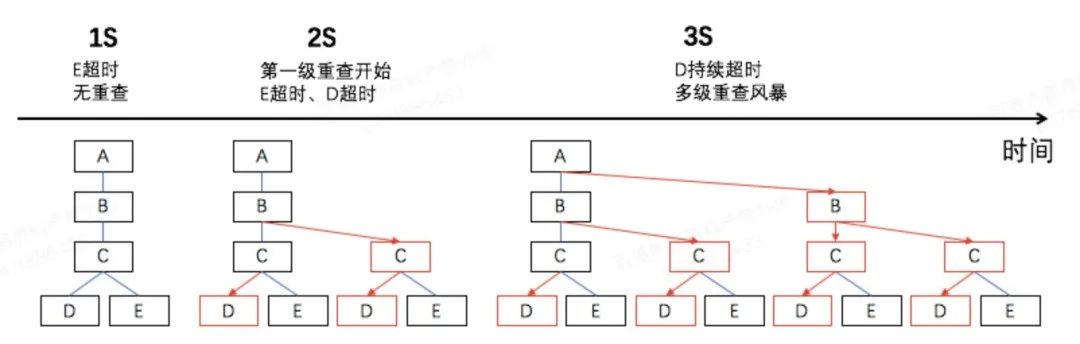
级联故障如何感知。当某个模块故障引起拒绝时,可能会产生级联的次生故障,表现为拒绝直接原因多样化。下图展示了 一种典型的级联故障:E异常后B对C发起了大量重查,首查叠加重查流量彻底把D压垮,最后A对B也开始发起大量重查。拒绝的流量在个个模块都有可能命中限流策略,表现为不同的拒绝原因。因此,在产生故障时,依赖某一个时间点的拒绝统计信息可能会掩盖引起拒绝的根因。
挑战7:
级联故障如何感知。当某个模块故障引起拒绝时,可能会产生级联的次生故障,表现为拒绝直接原因多样化。下图展示了 一种典型的级联故障:E异常后B对C发起了大量重查,首查叠加重查流量彻底把D压垮,最后A对B也开始发起大量重查。拒绝的流量在个个模块都有可能命中限流策略,表现为不同的拒绝原因。因此,在产生故障时,依赖某一个时间点的拒绝统计信息可能会掩盖引起拒绝的根因。
 挑战8:
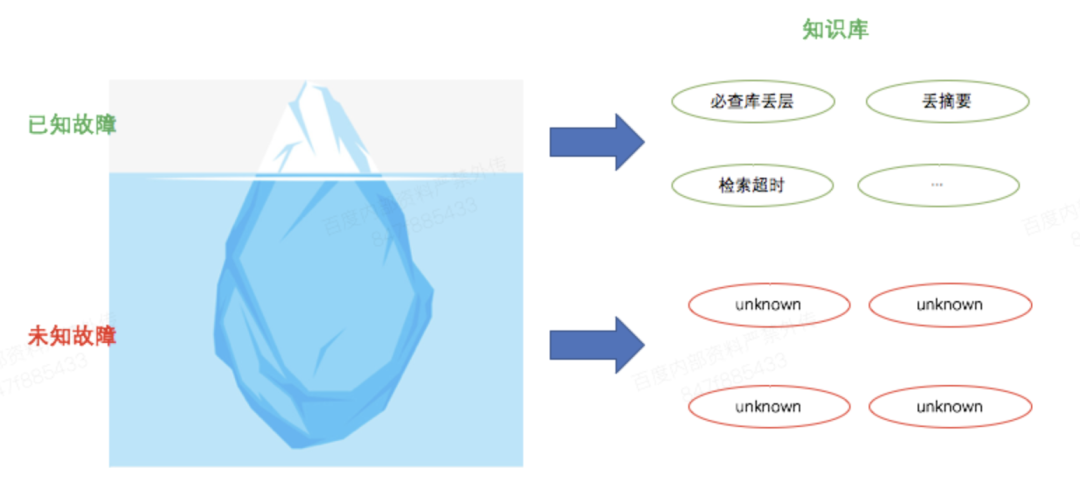
如何定位未知故障。故障是偶发的,我们进行拒绝原因划分的时候所使用的划分集合,无法完整体现系统可能出现的拒绝原因。对于未知故障或者未被纳入到拒绝定位规则中的拒绝,我们需要有手段“制造”故障,发现未知或者未采集到的故障。
挑战8:
如何定位未知故障。故障是偶发的,我们进行拒绝原因划分的时候所使用的划分集合,无法完整体现系统可能出现的拒绝原因。对于未知故障或者未被纳入到拒绝定位规则中的拒绝,我们需要有手段“制造”故障,发现未知或者未采集到的故障。
 下面,将依次介绍我们是如何解决这8个问题的。
下面,将依次介绍我们是如何解决这8个问题的。
4.1.1 索引镜像技术
为了实现日志的快速检索,日志索引由在线采集模块提取后,除了推送本机建立索引之外,还将定位需要的子集主动推送至旁路索引模块,该模块会以日志对应的queryID为key写入内存介质的全量索引存储中。这里的索引支持多列稀疏存储,相同queryID的多条日志location可以追加写入。这样,单条拒绝query的location信息可以已O(1)的时间复杂度拿到,接下来并行地到目标机器上捞取日志,并将其写入持久化的故障日志存储中。最后对这些日志进行特征提取并分析拒绝原因。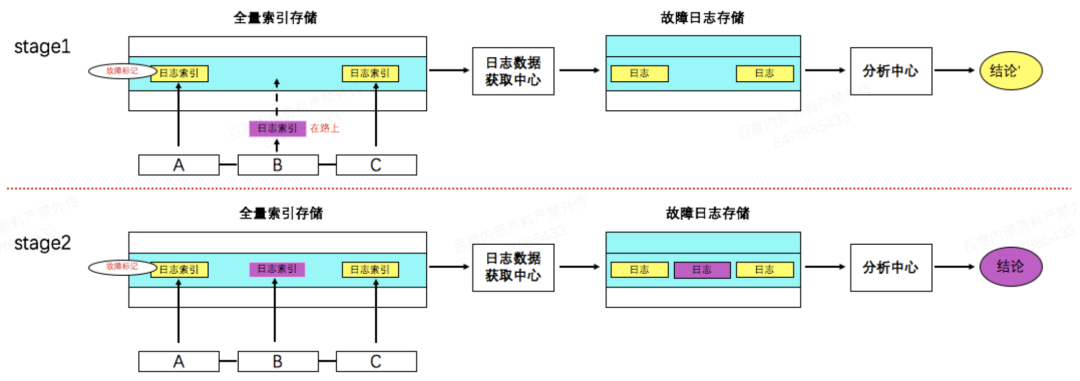
4.1.2 流式分析
为了解决问题2,我们借鉴了流式分析的理念。无论是分析模块收到了拒绝信号还是增量的拒绝日志信号,都触发一次拒绝原因的分析,并更新结论。这里有2个关键点:一是分析自动触发,线上只要发生拒绝,拒绝分析就开始工作。二是增量更新,只要某个拒绝query的日志有更新,就重新触发故障原因分析。对于入口模块,在线采集端会根据其日志中的指定字段判断是否是拒绝,并将这个信号连同索引一起推送到旁路索引模块。旁路索引模块在收到该信号后会立即通知分析中心对这个queryID进行分析,因此分析流程可以在拒绝报警发出之前触发,最大化故障定位止损效率。当旁路索引模块向分析模块触发完一次分析请求后,会将这个queryID记录到全量索引存储的pvlost表中,当后续有非入口模块日志的索引到达时,旁路索引模块拿该索引中的queryID到这个表中查找,即可判断是否是需要触发增量分析。增量分析会合并所有已知日志,并更新分析结论。4.1.3 完备labelset
在入口模块接收到用户query后,该query会经多个模块的处理。每个模块都有读取、解析请求包,请求后端,处理后端返回结果,以及最后的打包发送流程。在这个抽象层级上,请求处理各个步骤的划分是足够明确的,并且都可能出现失败而引起query在该模块的拒绝。所以,我们对这个处理过程中可能失败的原因进行了枚举,构建了单模块故障原因完备模板,将该模版应用到所有的必查模块就构成了故障原因的完备集合。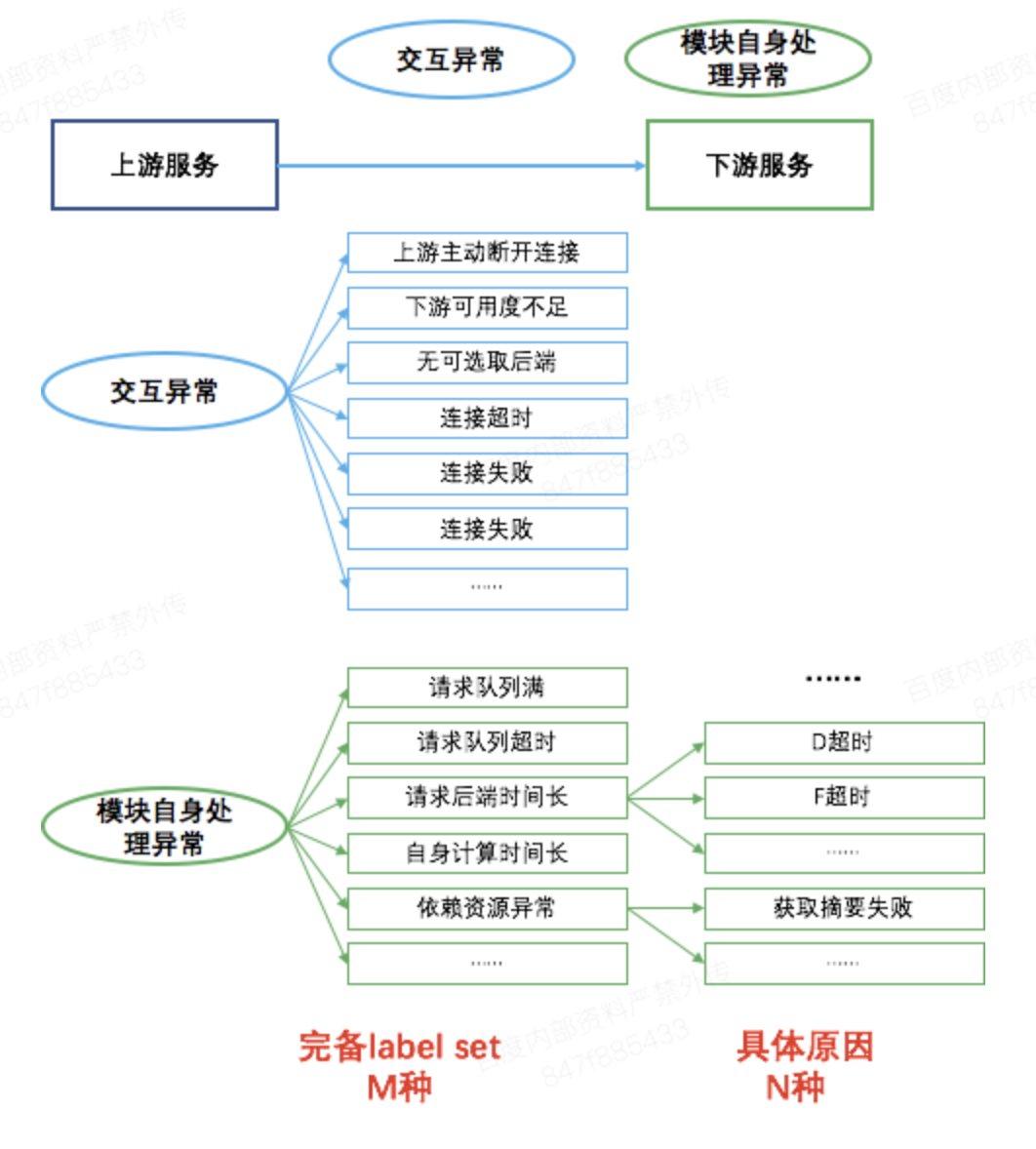
4.1.4 特征工程
在确定了完备labelset(拒绝原因)之后,我们需要在程序中实现自动的特征提取、表达,并和拒绝原因建立映射。不同模块的业务日志差异很大,为了解决特征的提取问题,我们实现规则提取引擎,输入为日志原文和提取规则,输出为采集到的特征。特征的类型主要有2种:指定内容是否存在、值是多少。在提取出特征之后,我们使用一个向量表示各个特征的取值,当向量中某些特征的取值满足指定的条件(等于、在指定范围等)时,就给出对应的拒绝原因。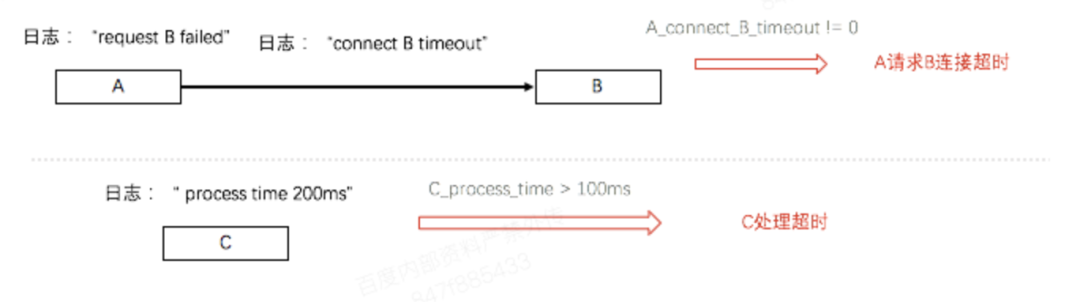
4.1.5 单query现场还原
日志分析模块拿到的日志只是相互独立的节点,进行query现场还原后才能开始分析。从入口模块开始,搜索系统的各个模块会把自己的span_id,以及所调度的多个后端的span_id打印出来,依据这些信息即可还原调度现场。需要注意的是,模块发起的首查和重查是有先后顺序的,通过对一个节点的孩子节点的span_id进行排序,即可还原这种调度上的先后次序。在还原调度树之后,将调度树由根节点到叶子节点路径上的所有异常日志汇总,从中拿到所有的特征并和规则列表进行比对,即可得到该路径(调用链)的拒绝原因。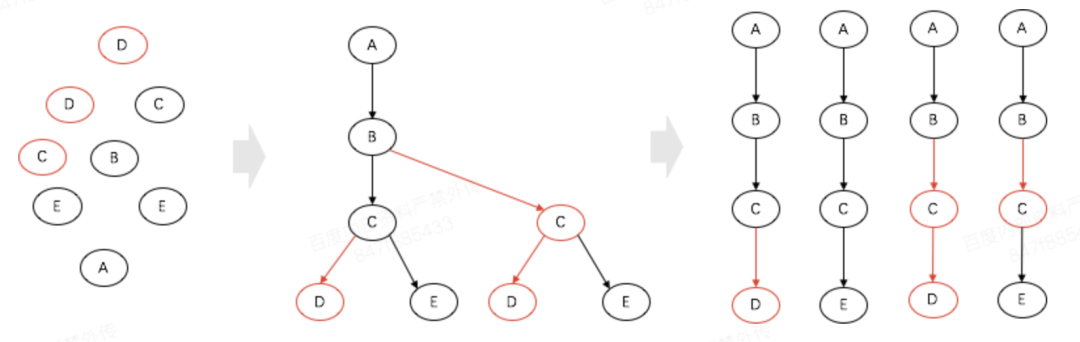
4.1.6 智能rank算法
问题6的难点在于:在一批query所有维度的特征中,找到有明显聚集性的一个(一组)维度。这可以进一步表示为:在不同维度之间进行排序,找到排名最考前的维度,而排序的依据就是该维度内部取值是否有高度的聚集性。为了解决这个问题,我们借用了熵的概念——当拒绝的query在某个维度上取值聚集越强时,它的熵就会越低。在构建排序模型时,我们对不同维度的取值进行了变换,确保不同维度可比,并加入了人工经验确定维度权重。这样就可以在出现拒绝时,按照顺序给出拒绝query在不同维度的聚集性,帮助定位根因或制定止损策略。 4.1.7 时间线分析机制 为了准确感知到拒绝的演化过程,我们实现了timeline机制。收到拒绝报警后,该工具会自动从巨浪获取拒绝信息,按照秒级粒度进行拒绝原因数量统计,并进行二维展示,如下图所示。在该展示结果上,可以看到不同秒级时间各种拒绝的数量,以及不同拒绝原因随时间的变化趋势,帮助我们定位根因。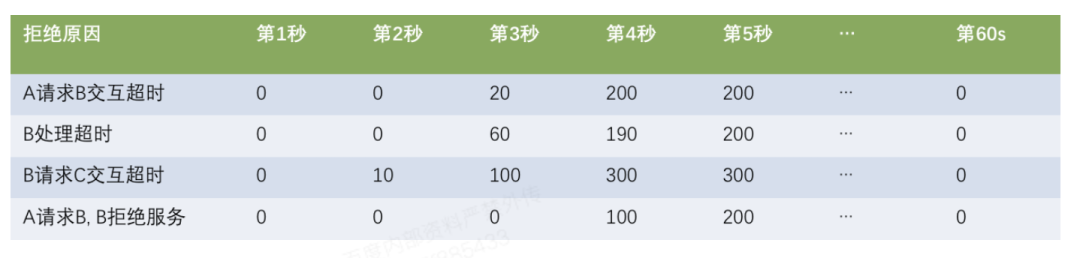
4.1.8 混沌工程技术
问了解决问题8,我们引入了混沌工程的技术。混沌工程提供了向在线服务精确注入各种故障的能力,这样就可以拿到丰富且带标记的样本补充到定位知识库中。这样不仅解决了日志样本问题,还可提升对未知故障的预测能力,从“亡羊补牢”进化到“未雨绸缪”,防患于未然。 这8大技术,很好的解决了前面的8个问题。在定位效果上,准确率可达99%,出现拒绝后,产出模块粒度的拒绝原因可以在秒级完成,分析能力可覆盖大规模拒绝。4.2 长尾批量分析
搜索系统中存在着一些响应时间长尾,为了解决这个问题,我们基于全量tracing和logging数据,实现了一套例行长尾原因分析机制。该机制定时从入口模块拿到响应时间长尾的query,再对每个query调用全量调用链的接口拿到完整的调度树。在分析长尾原因时,从入口模块开始,通过广度优先遍历的方式,逐步向后端模块推进,直到找到最后一个响应时间异常模块,即认为长尾是由该模块引起的。 模块响应时间异常的定义为:该模块的响应时间超过了正常请求的极限响应时间,并且它所调用的模块的响应时间是正常的。在确定异常模块之后,可以进一步从全量调用链中有针对性的拿到该模块的日志,从日志中根据规则找到该模块处理耗时异常的阶段。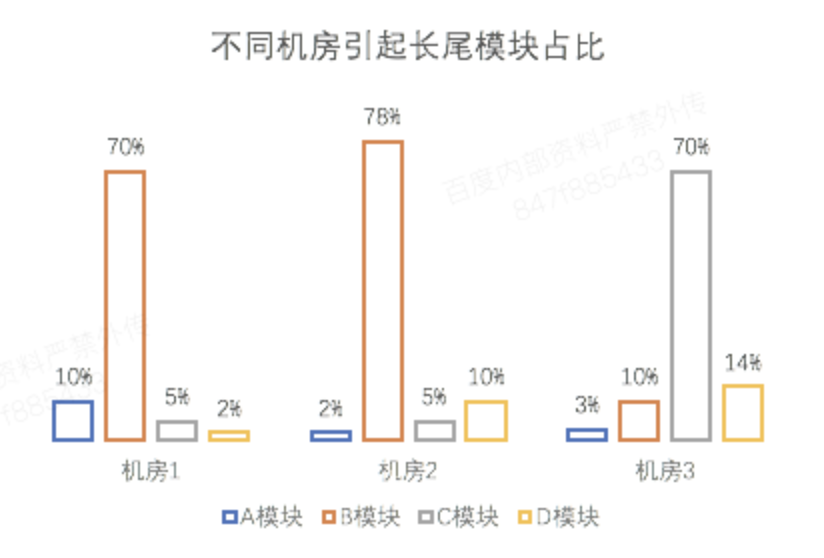
4.3 异常状态全流程追踪
为了确保用户体验的稳定性,搜索会定期分析未召回预期结果的query。query没有返回预期结果,可能是因为它命中了“捣乱者”写入的cache,也有可能它穿透了cache,召回了有问题的结果,这里问题的原因可能是偶发的或者是稳定的。我们需要能筛选出可以稳定复现的问题进行追查。为了实现这个需求,我们先拿到各个query的tracing以及logging信息,根据这些信息可以: (1)找到哪些query命中了“捣乱者”写入的脏cache; (2)哪些query穿透到了后端并重新进行了检索。 将命中cache的query和写入cache的query关联起来,即可得到下图所示的结果——异常状态的全流程追踪。只要异常效果持续时间内的cache命中是连续的,并且触发了多次cache的更新,那么就可以认为在这一段时间内,故障是稳定复现的,可以投入人力追查。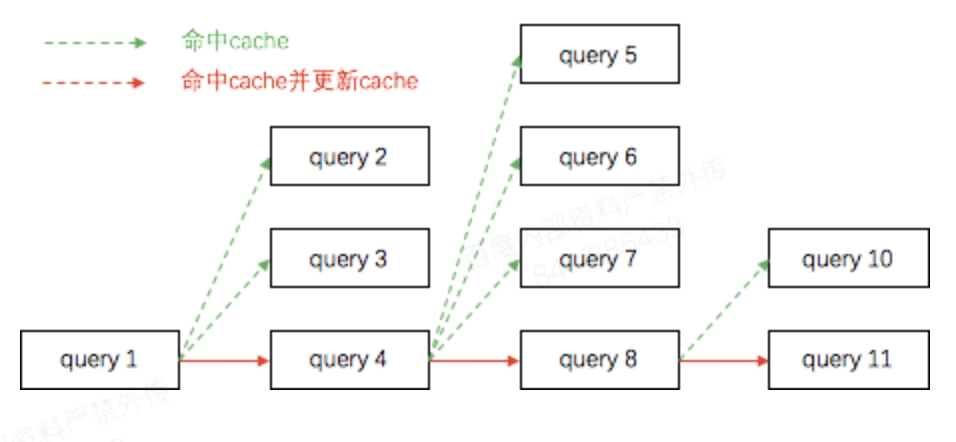
第五章 总结
本文首先介绍了百度搜索可用性保障的困境,超大的服务规模、极高频的变更和参与人数、海量数据和请求量、多样且多变的故障种类等构成的复杂系统,对年只能停服5分钟的极端严格可用性目标构成了极大挑战。然后,以时间顺序介绍了我们对百度搜索可用性保障的解决经历和经验。 首先,为了解决问题追查死角的问题,我们建设了可观测基础——logging、tracing、metrics,这些没有精细加工的基础数据解决了可用性保障中的一部分问题,但是我们发现基础数据的自动化程度较低、智能性较差,复杂问题需要大量人力投入,分析效果强依赖人工经验,甚至根本无法分析。 更进一步,为了解决可用性保障的效率问题,我们对体系中的各个组件进行升级,使可观测性的产出变得可观测,复杂的效果故障由不可追查变得可追查,拒绝分析从人工变得自动、准确、高效。在整个体系建设过程中,我们从数据的消费者,变成数据的生产者和加工者,通过数据的生产、加工、分析全流程闭环,使得百度搜索中各种故障无处遁形、无懈可击,使得百度搜索可用性保障摆脱困境,持续维持较好的用户口碑,同时本文也希望给读者带来一些启发,更希望能引起志同道合者的共鸣和探讨。
本文分享自微信公众号 - 百度开发者中心(baidudev)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK