

Information Extraction From Semi-Structuted Data Using Machine Learning
source link: https://www.inovex.de/de/blog/information-extraction-from-semi-structuted-data-using-machine-learning/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
In this article we will tackle the task of information extraction from semi-structured data (documents). We shortly cover the difficulties posed by the semi-structured nature of documents as well as the current solutions to ensure better extraction results.
The problem at hand
Paper documents are still an integral part of all areas of life. They appear in everyday life as invoices, contracts or user manuals. Their structure, purpose and content can therefore vary greatly. These documents do however have one common characteristic: they are semi-structured. „Semi-structured“ in this context means that documents are comprised of both structured (e.g. tables or lists) and unstructured information (e.g. continuous text). As a result, conventional machine learning approaches, such as pure computer vision and natural language processing, cannot capture these documents in their entirety. To circumvent this problem, current state of the art machine learning approaches try to combine methods for document comprehension into a single multimodal model. A reoccuring idea troughout these models is the combination of both text and layout information. The main focus of this article is to answer the question whether the combined processing of text content and position information by a single model improves the information extraction.
Information Extraction
 Figure 1: A generalized visualization of an information extraction pipeline.
Figure 1: A generalized visualization of an information extraction pipeline.The process of information extraction can be generalized as seen in figure 1. Starting with an optical character recognition (OCR) engine, individual words are extracted from a document. These token, along with their position, are then processed by an extractor. Features of the document or simple heuristics can be used as an additional input. Finally, figure 1 shows two possible outputs for this process.
- Semantic labeling looks for tokens that are part of predefined entities.
- Semantic linking, on the other hand, deals with the search of related tokens as value pairs. For this task no entities are predefined and the model is only given a shema of relationship types.
For this article we will consider the information extraction task as a semantic labeling problem. The different models will be evaluated on the example of English-language cash register receipts. These are provided by the ICDAR SROIE Challenge dataset [3]. Consequently the entities in question are the address, the name of the store, the date and the total amount for each receipt.
Proof of concept using a graph model
As a first approach, we implement a graph convolutional network simular to the work of Liu et al [1]. This model considers documents as graphs. Therefore individual tokens represent nodes which are then interconnected with directed edges using a custom neighborhood definition. Each edge contains information regarding the relative size and position of the connected nodes to each other. Meanwhile the nodes themselves each contain a vector representation of the token they represent. Figure 2 visualizes a selection of nodes and their edges from such a graph ontop of its respective document.
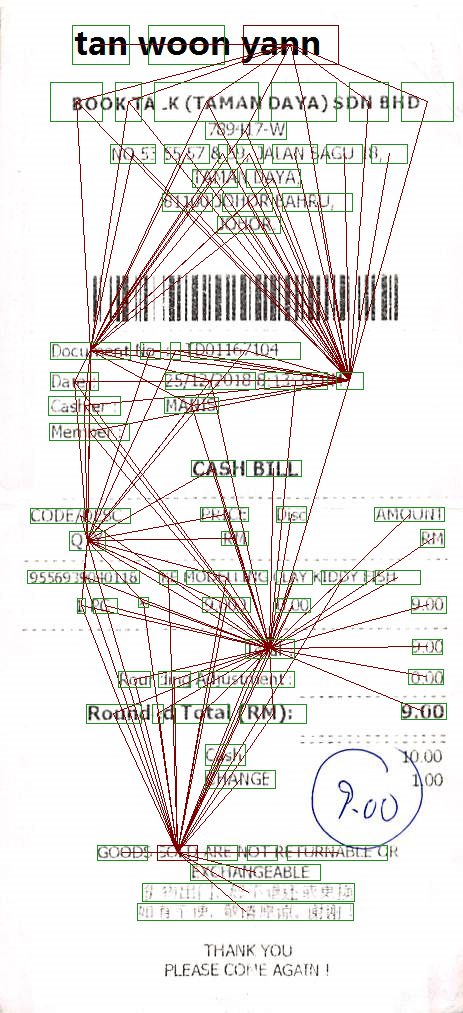 Figure 2: A selection of nodes from a document gaph with their edges and neighbors.
Figure 2: A selection of nodes from a document gaph with their edges and neighbors.The idea behind this graph network is to compute new node embeddings for each node based on their respective neighborhood context. Thus, text and layout will be combined in the computation of the new embeddings. As initial vector representations we try both BERT and Word2Vec embeddings.
Baselines
The graph network is then compared with different approaches for information extraction. As a low complexity approach, we implement rule-based extractors for individual labels. These rely on regular expressions and simple heuristics. Furthermore, a Bi-LSTM based on static and contextualized word embeddings (Word2Vec and BERT) and a BERT transformer model are trained to evaluate pure text extractors.
Finally, a Layout Language Model (LayoutLM) as proposed by Xu et al [2] serves as an advanced baseline. While based on a transformer architecture like BERT, LayoutLM additionally uses both textual and positional information. Since BERT and LayoutLM are otherwise structurally identical, comparing both models allows an evaluation of the multimodal approach.
Results
Metrics
To properly evaluate the trained models we choose metrics that mirror their real world usabilty. In a real use case, users would have to correct extracted values by deleting and/or adding characters. Additionaly, standard metrics such as F1 score only measure extracted token based on their assigned labels. The actual content of the extracted token, however, is completely ignored. A metric measuring the difference in characters between extracted text and a given ground truth for an entity would address both of these points. An example for such a metric is the Levenshtein distance, also often referred to as „edit distance“.
The Levenshtein distance measures an absolute distance between two character sequences. Two distances can therefore not necessarily be compared to eachother, since they do not consider the length of the sequences. The distance can however be used to calculate a coverage, indicating what percentage of the given ground truth is covered by the extraction. This coverage is the main metric when comparing the extraction performance of our models.
Our experiments show that the combined processing of text and position by a single model improves information extraction. LayoutLM is shown to be the best extractor across all labels, especially when compared to BERT, which is trained with identical parameters. This is displayed in figure 3 , visualizing the entities extracted from a receipt by BERT and LayoutLM.
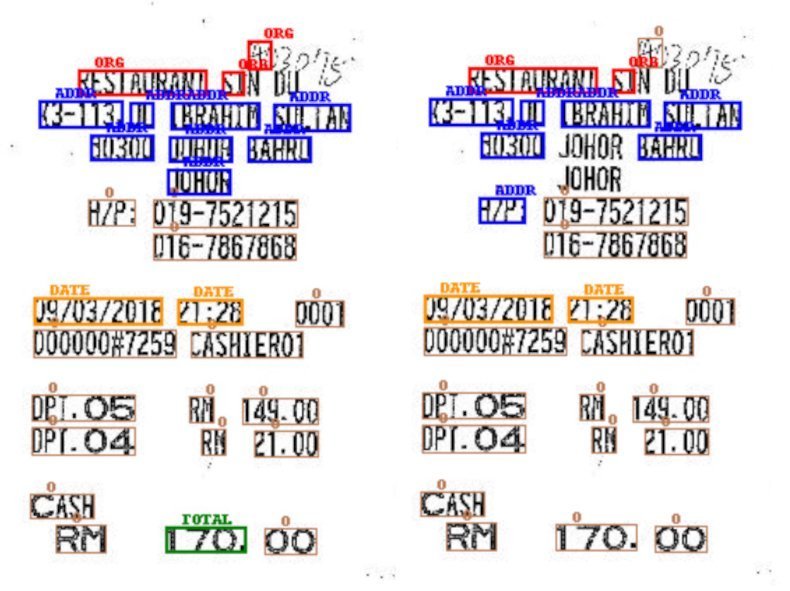 Figure 3: Extracted Entities for LayoutLM (left) and BERT (right) on a receipt from the ICDAR SROIE dataset.
Figure 3: Extracted Entities for LayoutLM (left) and BERT (right) on a receipt from the ICDAR SROIE dataset.Using a bar plot, Figure 4 depicts the results of the different models using the defined coverage metric as well as F1.
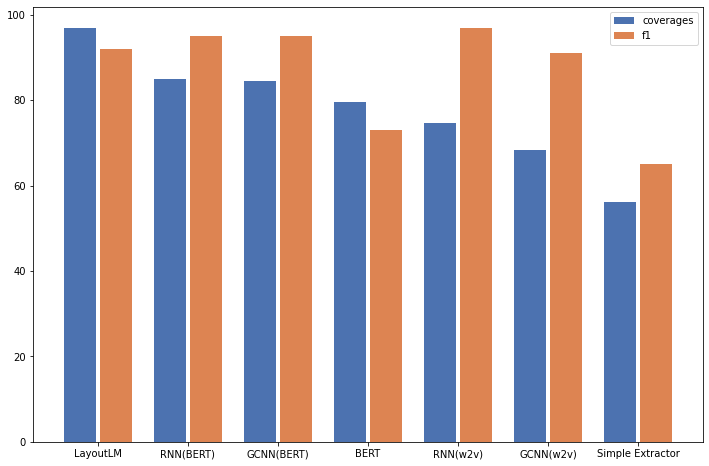 Figure 4: Coverage and F1 score for selected models on the information extraction task.
Figure 4: Coverage and F1 score for selected models on the information extraction task.LayoutLM performs best by a significant margin. The graph convolutional networks, on the other hand, appear to only have very limited benefits when compared to regular Bi-LSTM models. This is most likely due to the simplified reimplementation of the graph model presented by Liu et al [1]. The models using word2vec representations also drop significantly in performance when compared to the same models using BERT embeddings. BERT itself seems to be outperformed by simpler models.
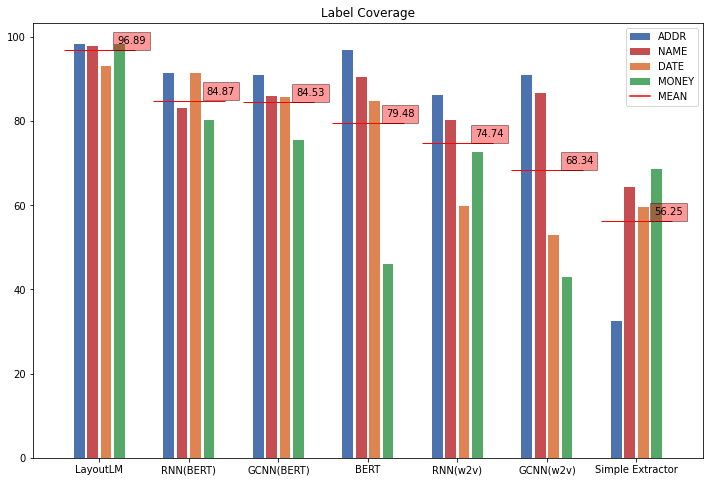 Figure 5: Model performance for information extraction on different labels.
Figure 5: Model performance for information extraction on different labels.After analysing model performance on individual labels as seen in figure 5, the main issue for BERT in this task is the extraction of money. This significantly lowers the overall performance of the model. Graph models also show to perform better on complex entities such as names and addresses. Moreover, all machine learning approaches achieve better results when compared to the rule-based extractor. Thus, the results also confirm the advantage of using advanced machine learning algorithms for the task of information extraction.
References
Bert and LayoutLM Models from Hugging Face
[1] Xiaojing Liu, Feiyu Gao, Qiong Zhang, and Huasha Zhao. Graph convolution for multimodal information extraction from visually rich documents. Proceedings of the 2019 Conference of the North, 2019.
[2] Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and Ming Zhou. LayoutLM: Pre-training of text and layout for document image understanding. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1192-1200.
[3] Z. Huang, K. Chen, J. He, X. Bai, D. Karatzas, S. Lu, und C. V. Jawahar. Icdar2019 competition on scanned receipt ocr and information extraction. In 2019 International Conference on Document Analysis and Recognition (ICDAR), pages 1516{1520, 2019
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK