

ASP.NET Core 搭载 Envoy 实现微服务的监控预警
source link: https://blog.yuanpei.me/posts/1519021197/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

ASP.NET Core 搭载 Envoy 实现微服务的监控预警
在构建微服务架构的过程中,我们会接触到服务划分、服务编写以及服务治理这一系列问题。其中,服务治理是工作量最密集的一个环节,无论是服务发现、配置中心、故障转移、负载均衡、健康检查……等等,这一切的一切,本质上都是为了更好地对服务进行管理,尤其是当我们面对数量越来越庞大、结构越来越复杂的集群化环境的时候,我们需要一种科学、合理的管理手段。博主在上一家公司工作的时候,每次一出现线上故障,研发都要第一时间对问题进行排查和处理,而当时的运维团队,对于微服务的监控止步于内存和CPU,无法系统而全面的掌握微服务的运行情况,自然无法从运维监控的角度给研发部门提供方向和建议。所以,今天这篇文章,博主想和大家聊聊,如何利用Envoy来对微服务进行可视化监控。需要说明的是,本文的技术选型为Envoy + ASP.NET Core + Prometheus + Grafana,希望以一种无侵入的方式集成到眼下的业务当中。本文源代码已上传至 Github ,供大家学习参考。
从 Envoy 说起
在介绍 Envoy 的时候,我们提到了一个词,叫做可观测的。什么叫可观测的呢?官方的说法是, Envoy 内置了stats模块,可以集成诸如prometheus/statsd等监控方案,可以集成分布式追踪系统,对请求进行追踪。对于这个说法,是不是依然有种云里雾里的感觉?博主认为,这里用Metrics这个词会更准确点,即可度量的,你可以认为, Envoy 提供了某种可度量的指标,通过这些指标我们可以对 Envoy 的运行情况进行评估。如果你使用过 Elastic Stack 中的 Kibana,就会对指标(Metrics)这个词汇印象深刻,因为 Kibana 正是利用日志中的各种指标进行图表的可视化的。庆幸的是,Grafana 中拥有与 Kibana 类似的概念。目前, Envoy 中支持三种类型的统计指标:
- Counter:即计数器,一种只会增加不会减少的无符号整数。例如,总请求数
- Gauge:即计量,一种可以同时增加或者同时减少的无符整数。例如,状态码为200的有效请求数
- Timer/Hitogram:即计时器/直方图,一种无符号整数,最终将产生汇总百分位值。Envoy 不区分计时器(通常以毫秒为单位)和 原始直方图(可以是任何单位)。 例如,上游请求时间(以毫秒为单位)。
在今天的这篇文章中,除了 Envoy 以外,我们还需要两位新朋友的帮助,它们分别是Prometheus 和 Grafana。其中,Prometheus 是一个开源的完整监控解决方案,其对传统监控系统如 Nagios、Zabbix 等的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。可以说,Prometheus 是完整监控解决方案中当之无愧的后起之秀,它最为人所称道的是它强大的数据模型,在 Prometheus 中所有采集到的监控数据吗,都以指标(Metrics)的形式存储在时序数据库中。和传统的关系型数据库中使用的 SQL 不同,Prometheus 定义一种叫做 PromQL 的查询语言,来实现对监控数据的查询、聚合、可视化、告警等功能。
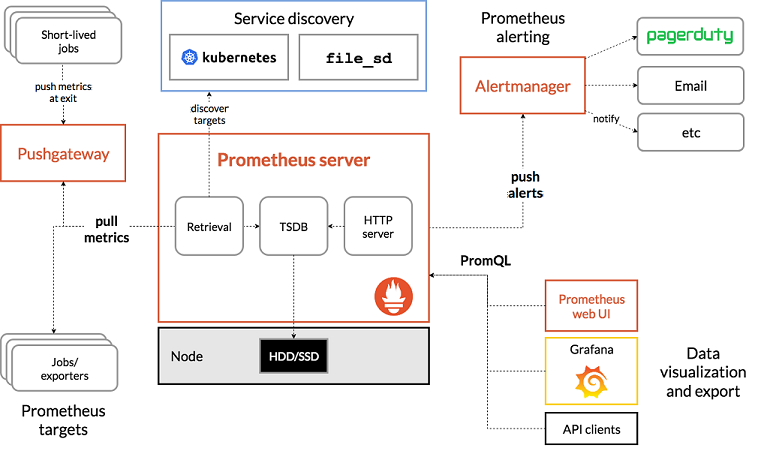
目前,社区中提供了大量的第三方系统的采集功能的实现,这使得我们可以轻易地对MySQL、PostgresSQL、Consul、HAProxy、RabbitMQ, Redis等进行监控。而 Grafana 则是目前主流的时序数据展示工具,正是因为这个原因, Grafana 总是和 Prometheus 同时出现, Prometheus 中采集到监控数据以后,就可以由 Grafana 赖进行可视化。相对应地,Grafana 中有数据源的概念,除了 Prometheus 以外,它还可以使用来自 Elasticsearch 、InfluxDB 、MySQL 、OpenTSDB 等等的数据。基于这样一种思路,我们需要 Envoy 提供指标信息给 Prometheus ,然后再由 Grafana 来展示这些信息。所以,我们面临的主要问题,其实是怎么拿到 Envoy 中的指标信息,以及怎么把这些指标信息给到 Prometheus 。
首先,我们来简单阐述一下原理。在 Envoy 的早期版本中,通常是通过 statsd 来采集 Envoy 中的信息,这些信息会被存储在 Prometheus 中,然后由 Grafana 从 Prometheus 中读取数据并展示为图表。而在 Envoy 最新的版本中,Envoy 本身就可以输出 Prometheus 需要的数据格式,故而就不再需要 statsd 这样一个监控工具。关于第一种方案,大家可以参考这篇文章:Envoy Service Mesh、Prometheus和Grafana下的微服务监控。这里,为了简单起见,我们采用第二种方案来进行集成。在接下来的例子中,我们会部署下面四个服务,我们希望在调用 gRPC 服务的时候,可以在 Grafana 看到相关的监控指标:
version: "3"
services:
# prometheus
prom:
image: quay.io/prometheus/prometheus:latest
volumes:
- ./Prometheus/prometheus.yml:/etc/prometheus/prometheus.yml:rw
ports:
- 2333:9090
# envoy_gateway
envoy_gateway:
build: Envoy/
ports:
- "9090:9090"
- "9091:9091"
volumes:
- ./Envoy/envoy.yaml:/etc/envoy/envoy.yaml
# grpc_service
grpc_service:
build: GrpcService/GrpcService/
ports:
- "8082:80"
environment:
ASPNETCORE_URLS: "http://+"
ASPNETCORE_ENVIRONMENT: "Development"
# grafana
grafana:
image: grafana/grafana
ports:
- "3000:3000"
environment:
- “GF_SECURITY_ADMIN_PASSWORD=Gz2020@”
- “GF_INSTALL_PLUGINS=alexanderzobnin-zabbix-app”
restart: always
depends_on:
- prom
接下来,为了让 Prometheus 可以直接读取 Envoy 中输出的指标数据,我们需要在其配置文件prometheus.yml中添加一个对应的任务:
global:
scrape_interval: 15s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'envoy'
metrics_path: '/stats/prometheus'
scrape_interval: 15s
scrape_timeout: 15s
static_configs:
- targets: ['localhost:9091']
大家还记得 Envoy 中提供的管理接口吗?我们说 Envoy 提供了 Prometheus 格式的指标数据,其实就是指 Envoy 管理接口中的 stats/prometheus 接口,它对应的地址为:http://localhost:9091/stats/prometheus,直接访问这个地址,我们就可以得到下面的结果,这就是 Prometheus 需要的指标数据格式:

数据源与可视化
现在,万事俱备,我们通过docker-compose启动服务即可,默认情况下,Prometheus 使用9090端口,Grafana 使用3000端口,其中,Grafana 默认的账号为admin/admin,建议大家第一次登录后,及时修改默认的账号密码。
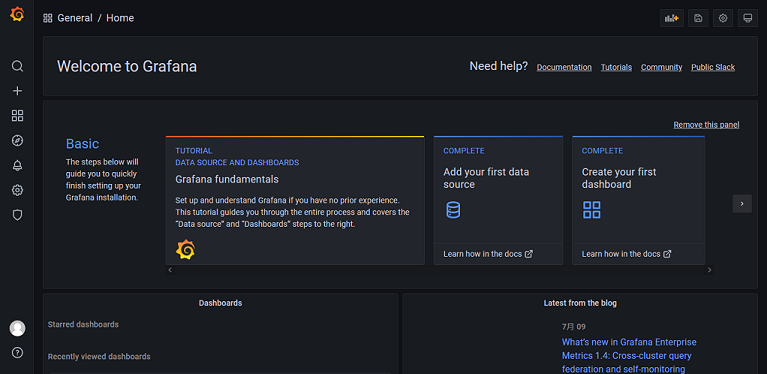
接下来,我们可以注意到,Prometheus 中两个 target 都已正常启动,这表示它们开始采集数据,我们还可以通过 Graph 菜单来查看当前采集到的数据。
那么,数据采集到 Prometheus 以后,如何在 Grafana 中进行图表的可视化展示呢?首先,我们需要在 Grafana 中添加一个数据源,点击左侧第6个图标就可以找到入口。显然,这里的数据源就是 Prometheus :
接下来,我们可以到官方的 社区 里找一个 Envoy 的模板,这是一个别人做好的 Dashboard,我们暂时用这个模板来看看效果。随着学习的深入,我们会先从自定义图表开始做起,最终,我们会拥有一个属于自己的 Dashboard 。这里,我们选择一个 Dashboard 模板后,复制其ID,并在 Grafana 中进行导入,导入的时候需要选择数据源,我们选择 Prometheus 即可。接下来,就是见证奇迹的时刻:
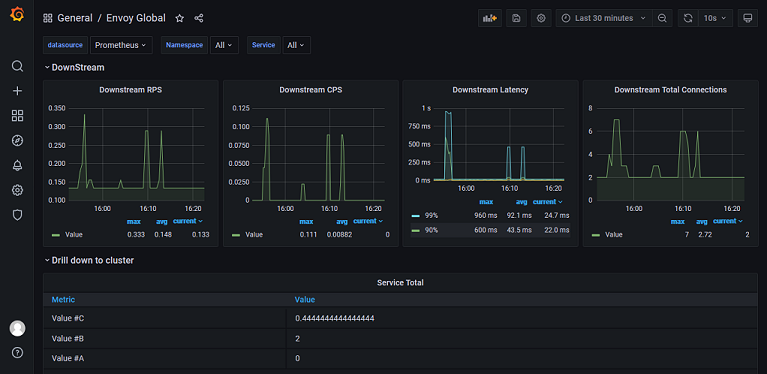
自定义图表
好了,如果大家阅读过官方文档,就会知道,除了 Prometheus ,像常见的 MySQL、Nginx 等,都可以作为 Grafana 的数据源,如果你需要监控 Nginx 的某个指标,这会是个非常不错的思路。那么。如何按照个人/领导的要求,对 Dashboard 进行进一步的定制呢?这就要说到 Grafana 的自定义图表,这里,我们通过下面的例子来进行说明:
rate(envoy_http_rq_total{envoy_http_conn_manager_prefix="grpc_json", instance="192.168.6.120:9902"}[5m])
在 Prometheus 中,采用的是与 OpenTSDB 类似的时序格式:
<metric name>{<label name>=<label value>, ...}
可以注意到,每一个指标含有多个键值形式的标签。例如,http_requests_total{method="POST"}表示的是所有 HTTP 请求中的 POST 请求。
此外,除了上文中提到过的 Counter 、 Gauge 、Histogram 这三种类型,Prometheus 还支持一种叫做 Summary 的类型。和大多数语言类似,这门被叫做 PromQL 的语言,(1):支持常见的运算符,例如算术运算符、比较运算符、逻辑运算符、聚合运算符等等。(2):支持大量的内置函数,例如,由浮点型转换为整型的floor和ceil,计算平均速率的rate等等:
floor(avg(http_requests_total{code="200"}))
ceil(avg(http_requests_total{code="200"}))
rate(http_requests_total[5m])
在这里,我们给出的示例,它表示的是5分钟内 HTTP 请求的平均数目。我们可以在 Prometheus 中的 Graph 菜单对其结果进行查看:
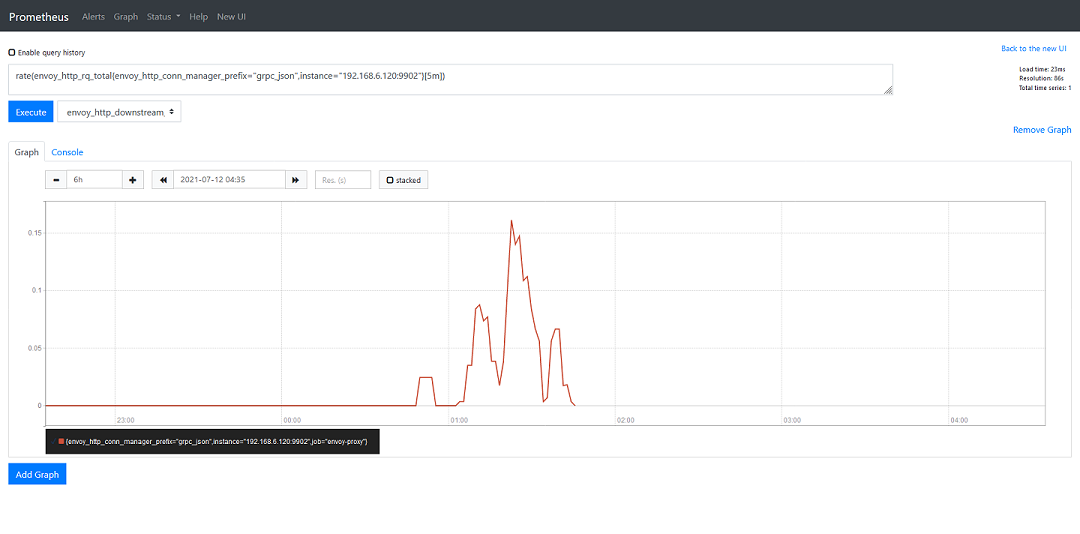
通常,我们可以在这里对查询语句做简单的调试,而如果需要将其集成到 Grafana 中,我们就需要在 Grafana 新建一个图表,可以注意到,两者的语法是完全相同的,这里唯一的不同点在于,时间间隔从固定的5分钟变成了一个变量:
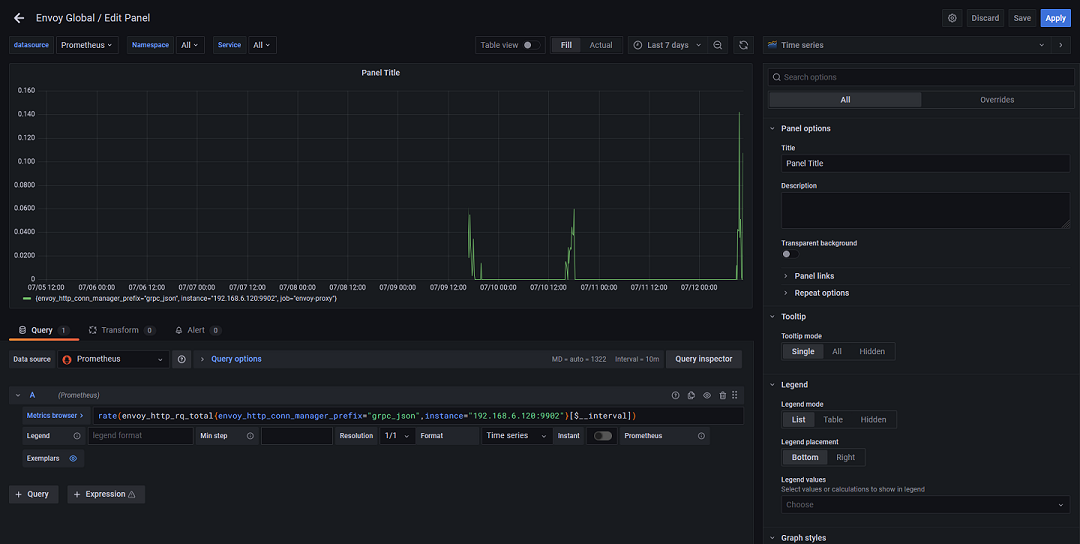
此时,我们就完成了一个自定义图表的制作,其中的关键有两点,其一是了解每一个指标的含义,其二是了解每一个内置函数的用法。革命尚未成功,同志仍须努力。这些内容无法在一篇博客里全部讲到,如果需要做进一步的探索,还是建议大家去看官方文档,这里博主给大家可以推荐一个不错的中文文档。
本文介绍了利用 Prometheus 和 Grafana 对 Envoy 进行监控预警的方案。在 Envoy 的早期版本中,主流的方案都是通过 statsd 来采集 Envoy 的指标信息,而在 Envoy 最新版本中,它本身就可以输出 Prometheus 需要的数据格式,我们只需要在 Prometheus 的配置文件中指定stats/prometheus这个地址即可。Prometheus 采用了和 OpenTSDB 类似的时序格式,每一个指标均含有多个键值形式的标签。Prometheus 在此基础上提供了 PromQL 查询语言,我们可以利用这个查询语言在 Grafana 中制作自定义图表,这些自定义图表可以是一个瞬时数据、可以是一个区间数据,或者是一个纯量数字,因此,我们可以按照自己的喜好去定制整个仪表盘,结合实际的业务场景来决定要关注哪些指标。除此以外,我们还可以在 Prometheus 定义告警规则,当业务系统出现问题时,可以第一时间通知运维或者研发团队。在后端研发越来越服务化、集群化的今天,我们不能永远都盯着 CRUD 这一亩三分地,更普遍的,可能是针对 Docker、K8S、Redis、MySQL 等等基础设施的监控,扁鹊见蔡桓公的故事大家耳熟能详,防微杜渐,无论过去还是现在甚至将来都是一样的。好了,以上就是这篇博客的全部内容啦,谢谢大家!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK