

基于机器学习的高价值用户自动发现
source link: https://cosx.org/2016/05/machine-learning-user-high-figure/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

作者:迟保昉 (猎聘大数据研究院) 苏铖 (猎聘大数据研究院) 单艺 (猎聘大数据研究院)
摘要:猎聘每天有数万新用户注册。但是,其中有的用户只是填写了少量的职业信息,即名片信息,而并未完成整个简历的填写。为获得完整的简历,猎聘职业顾问团队(GCDC)需要电话联系该部分用户完善简历。历史数据表明,未填写简历的用户中有相当数量的高价值的用户,而猎聘职业顾问需要能够优先拨打这批高级用户并提升其转化率。 为此,我们研发了基于 k-NN 算法的自动名片用户分类系统——card-rater。该系统根据用户填写的名片信息对新用户的级别进行预测,推断其为高级简历用户的可能性。将评分较高、更有可能是高级的用户推荐给 GCDC 进行优先电话拨打,显著地提高了高级用户简历转化率。
一、业务介绍
猎聘于 2011 年上线。是国内唯一真正实现企业、猎头和职业经理人三方互动的职业发展平台。猎聘始终专注于打造以经理人用户体验为核心的职业发展平台,全面颠覆传统网络招聘以企业为核心的广告发布平台。截至 2016 年 4 月,猎聘拥有超过 2800 万的注册会员,已服务超过 50 万家优质企业。目前,有超过 25 万名猎头在猎聘平台上寻找核心岗位的候选人。
自 2014 年起,猎聘建立全球职业发展中心(Global Career Develop Center, 简称 GCDC),同时服务企业和求职者,作为两者互动的桥梁发挥着重要的作用。不同于其他互联网招聘企业,猎聘重点关注中高端招聘需求,如中高层企业管理者、专业技术人才等。这些企业需求量相对较小,但是招聘难度大,招聘过程附加价值高。猎聘通过这种方式明确了自身的品牌定位,获得了企业客户的认可和信赖。经过几年的发展,猎聘已经在中高端招聘领域取得了领先的市场地位,并积极拓展其他细分市场。
对于任何互联网招聘企业来说,求职者的简历库都是核心资产。因为这是他们变现的基础。只有拥有足够多的简历,让企业可以在该网站上获取需要的人才,才能持续从企业客户获得订单。对于猎聘来说,与其他互联网招聘企业又有一定的不同。这是因为猎聘定位中高端招聘需求,要求猎聘向企业客户提供的简历是具有一定质量的白领、高级白领、乃至金领的简历。出售这样的简历资源,也是猎聘变现的主要来源。在定价上,企业需要付较高的费用来购买此类简历;而对于其余的简历,企业仅需要付出非常低廉的成本即可获得。因此猎聘内部根据简历的信息,将简历进行等级划分。满足一定标准(如一定收入、一定职级等)、可以进行高价售卖的简历,称为高级简历;而剩下的简历则称为白领简历。对于猎聘来说,如何快速高效低成本获取高级简历成为用户获取工作的重要组成部分。
获取简历的最主要方式是通过在线注册。求职者通过搜索引擎、网站导航、或者直接输入网址等各种方式进入猎聘之后,即可进行在线注册成为猎聘的用户。搜索引擎、网站导航等用户注册完成后可以填写基本信息,如当前的公司、职位等等——这时成为了一份 “草稿简历”——乃至进一步填写完整的工作经历和教育经历信息,最终形成一份完整的简历。前面提到的简历分级的前提是,必须有一份完整简历,这是因为在分级的过程中,使用了简历中多方面的信息,如果简历不完整,将无法准确对简历进行评价。在注册填写简历的过程中,有些用户如果找工作的意愿并不强烈,他可能就不会把信息完善到最后一步,也就是说他的简历状态可能停留在了草稿简历的阶段。但是不排除未来的某一天,他可能会来把自己的简历完善。每天注册并且能够直接填完的简历被称为即时简历;而并非在当天创建,而是历史上某天被创建的简历,如果在当天被填写完整了,则被称为回归简历。每天新增的简历数,便是由这两部分组成。这两部分简历其实对应的是两类人群:主动求职者——急于找工作,所以需要赶紧完成一份简历,以便自己应聘职位,或者让企业和猎头可以搜索到;以及被动求职者,现在并不着急找工作,想使用猎聘提供的其他功能,如人脉功能,便不用填写完整的简历,也可以在猎聘的平台上积累人脉,为将来做准备。对于这两类人群,围绕着简历数这一核心 KPI,采取的方案其实并不一样。对于第一类用户,为了能够让他填写简历更为顺畅,需要在产品设计和用户体验上多下功夫,令用户不觉的填写简历是一个非常繁琐的事情,从而提高即时简历的转化率。而对于第二类用户,由于他自身当前并没有需求,所以改进产品对他的影响并不明显,还需要用各种办法去引导用户,让他去填写简历。
然而通过在线渠道获得的流量都需要付出高昂的成本,因此对于猎聘来说,需要最大限度地使在线注册的用户填写完整的简历,而简历召回也就成为了重要的工作内容。召回的方式也有很多,包括:系统站内信、EDM、短信提醒等等。这些方式成本较低,但是也因为不够直接,所以效果得不到保证。而效果最好的方式,是通过 GCDC 的职业顾问电话直接引导用户填写简历。当然这种方式也是成本最为昂贵的。我们来算一笔账:职业顾问的每一通电话的成本可以近似认为是固定的 C,每通电话之后能够将求职者的简历从草稿简历变为完整简历的概率为 P,这个概率受到多个因素的影响,也可以近似认为是不变的;每份完整简历的价值为 V(l),其中 l 是简历等级,而 V 是随简历等级增加而增加的函数,不难计算出猎聘的收益。由于 C 和 P 固定,那么 Y 与 V(l) 是正相关的,也就是与 l——简历等级是正相关的。同时,由于每天新增的草稿简历数量众多,职业顾问甚至无法全部都打一遍电话,这也要求我们要对草稿简历进行划分,找出草稿简历中价值高的简历——也就是有更高可能性成为高等级的简历——优先进行召回。
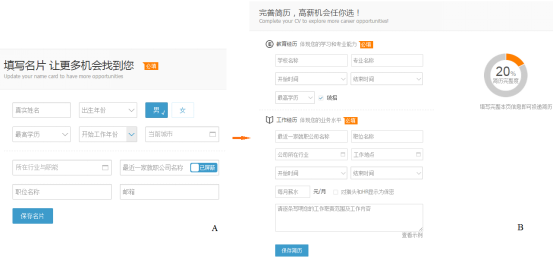
不断地获得新鲜的、高质量的注册用户以及完整简历,对于猎聘的商业模式是一件至关重要的任务。目前猎聘的主要用户获取来源是网站和手机客户端 APP。每名新用户在登录猎聘网进行注册时,首先需要填写个人的名片信息(图 1-A)。当填写完后,即可进入简历信息的填写(图 1-B)。但是,通过数据分析我们发现,许多用户在填写完名片信息后,并未进入简历页面完成整个填写过程。对这部分用户召回是用户获取工作的重要组成部分。但是,每日新注册用户数以万计,在人力有限而且成本较高的约束下,电话召回工作无法覆盖到全部用户,盲目电话召回的投入产出比低下。如果能够实现对高级用户进行优先召回,则可以显著地提高职业顾问和用户获取部门的工作效率。
二、数据描述
(一)数据采集
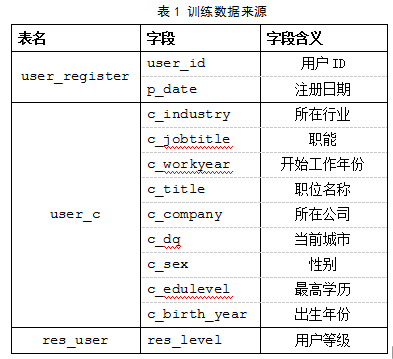
用于建模的训练数据主要来自三张表——user_c、user_register 和 res_user。表 user_c 主要存储用户的名片信息;user_register 存储用户的注册信息;res_user 存储用户的简历信息。从这三个表中我们抽取用户的名片信息及评级信息。(字段及对应含义见表 - 1)
数据的生成时间:2014 年 5 月~ 2015 年 5 月。在这一时期,用户注册流程和评级模型未有变更。
(二)数据清洗
构建规范的训练数据集是赋予预测模型良好性能的前提。为此,我们实施了如下的数据清洗步骤:
移除重复记录
由于某些技术原因,数据库中会存在一些重复信息。为此,首先需要去掉重复信息,确保每个用户 ID 只在数据集中出现一次;
移除含有无效信息的样例
名片信息的真实性对基于样例的机器学习算法(card-rater 系统的核心算法是 k-NN,详见后文)非常关键。然而出于某些原因,部分经理人可能会填写无效的名片信息,而这种实例是应当被看做噪音数据移除的。目前,我们对名片信息有效性的判断策略,主要基于领域知识、法律法规和公司的产品定位。主要的判断标准如下:
1)名片信息年龄减去工龄低于 16 年的,为无效名片信息。依据是:根据《中华人民共和国劳动法》第十五条规定,禁止用人单位招用未满十六周岁的未成年人;
2)男性年龄超过 60 周岁、女性年龄超过 55 周岁的样例,被认定为无效样本。依据是《国务院关于安置老弱病残干部的暂行办法》和《国务院关于工人退休、退职的暂行办法》 (国发〔1978〕104 号)文件所规定的退休年龄;
3)工龄不足 2 年,却在职能部分填写高级职能(如 CEO、总裁等)的,也会被判定为无效信息而移除。这一做法的依据是基于常识。在实际情况,有可能这样的信息可能是真实的。如注册用户创业、或者继承了家族企业的高级领导岗位。但是,一方面,这些情况并不普遍;另一方面,猎聘主要的服务对象是中高端经理人,而非如上两类人群。
然后,根据每月新注册完整简历用户中高级与低级用户的比例情况,从 2014 年 5 月~ 2015 年 5 月期间每个月份随机抽取用户 1000 条。最终得到来自 12 个月的共 12000 条用户名片记录。
(三)特征工程
-
对特征的选择主要依据是对业务了解。
1)“行业” 属性不作为有效特征:首先,根据前期的数据统计分析,行业本身不会对用户级别产生影响;其次,在猎聘的业务体系中,共涉及 13 个大行业。如果作为特征,那么如何进行量化处理是个难点。“行业” 为非度量属性,传统做法是将之映射为 13 个二值特征向量,那么维度就由 7 个增加至 20 个。这会带来数据稀疏性的问题。(尤其对于 k-NN 算法来说,会给预测准确性带来负面影响);
2)年龄和工龄的选择:二者通常会呈现显著的正相关,但是相关度并不大(rho≈0.7)。我们的理解是,工龄作为衍生特征,会受年龄和教育水平共同影响。工龄虽然和年龄呈现显著正相关(显著性和受试样本规模密切相关),但是和教育水平呈一定的负相关。而教育水平的量化处理又会涉及新的问题,这会使特征的处理复杂化;何况,衍生特征也并不是给带来坏处。简化起见,我们将二者看做独立的特征;
3)职能和职位的处理:因为二者刻画的是用户的同一方面,所以我们将其作为同一特征处理。根据经验我们发现,当新注册用户在职能列表中找不到与自己当前的职能名称时,通常会在职能部分选择 “其他” 这一选项,然后再在当前职位部分手工填写职位名称。对此,我们运用了一些自然语言处理技术(如计算职位名称与职能名称的相似度)对用户的职能进行判定。
特征的预处理
k-NN 是涉及距离计算的机器学习算法,距离的计算方式直接决定着模型的性能。特征的内在属性不同,决定着其在可度量性和有序性上的差异,因此需要采取不同的特征表示方法。
1)非度量属性的二值化处理:性别属性不可度量,也难以实现可序化。因此,我们将之映射为两个特征——“是否为男性” 和 “是否为女性”。每个特征均设定为二值属性(是→1;否→0);
2)可度量离散特征的有序化处理:如我们将城市按照一线、二线、三线以下城市划分为三个数值级别;所在公司设定为国外上市、国内上市、未上市三个级别,同样的方法还应用于学历特征和职位特征的处理;
3)连续特征的离散化处理:我们会选取几个数值点分别对年龄、工龄进行离散化处理,年龄(工龄)越高,则设置的数值越高。(严格来讲,二者属于离散特征;但是由于其在性质上与连续特征更为接近,需要进一步的离散化和有序化处理,因此,我们称之为连续特征)
至此,我们确定了如下 8 个特征:性别(男、女)、出生年份、开始工作年份、最高学历、职能、当前公司、当前工作的城市。将每个名片的相关特征信息进行归一化处理后,用于后续的建模分析。
三、数据建模
(一)模型设定
综合考虑公司的业务特点和数据平台情况,我们选择了基于混合策略的排序方法:k 近邻算法 + 过滤规则。
k 近邻(k-Nearest Neighbors,简称 k-NN)是一种常用的监督式学习方法。其基本思想是 :相似的对象具有相同或者相近的类别。如果一个对象在特征空间中的 k 个距离最近、最相似的训练样本大多数属于某个类别,则该对象可以被判定属于该类别。
本项目中,我们选择 k-NN 主要基于如下考虑:
1)k-NN 工作机制简单,训练开销小:k-NN 是懒惰学习(lazy learning)的著名代表,没有显式的学习过程,训练阶段仅仅是把样本保存起来。这相较于需要大规模训练的机器学习算法(如深度学习)建模效率更高;
2)k-NN 具备良好的性能:k-NN 虽然简单,但是有理论研究表明,它的泛化错误率不超过贝叶斯最优分类器的错误率的两倍;
3)数据维度低而稠密:我们的数据的可用特征只有 8 个,这在很大程度上避免了机器学习领域经常面临的数据稀疏性问题。因此,使用基于样例学习的 k-NN 算法能满足业务对性能的需求;
4)良好的解释性与灵活性:使用 k-NN 可以很容易地给出每个样例属于高级用户的概率值并根据大小进行排序。GCDC 部门只需要按照分数由高到低的顺序进行拨打即可。
在建模时,我们随机抽选高级 / 普通用户实例各 600 个作为训练实例。对于每一个新的实例,计算其与每个训练实例的欧式距离,选取距离最近的 k 个实例(k 值的选取依赖于交叉验证),采用 “多数表决” 的策略,计算新样例属于高级用户的可能性(打分在 1~100 分),并根据分数高低对用户进行排序,推荐给用户获取部门作为召回策略的重要参考。
从如上的计算过程我们知道,对于每一个新的样例,k-NN 需要计算其与每个训练样本的距离。如果训练样例的数量较大的话,该计算步骤比较耗时,且耗费内存。为提高打分效率,我们引入了基于规则的 “低端职位过滤” 机制。
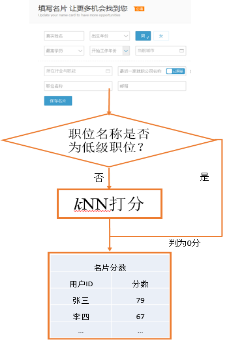
从业务角度来讲,猎聘主要的产品瞄准的是中高端人才。因此中高端经理人是猎聘的优先服务对象。为此,我们构建了一个 “常用低端职位词典”(如“摆地摊”、“司机”、“服务员” 等)。如果一个新的样例的职位名称存在于该职位词典中,则被直接判为 0 分,而无需进入 k-NN 算法的相关计算环节,这样就显著提高了打分效率。同时,也可以提高准确率。
(二)模型的评估结果
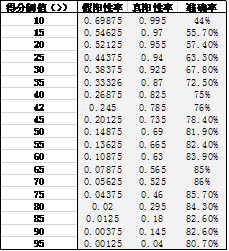
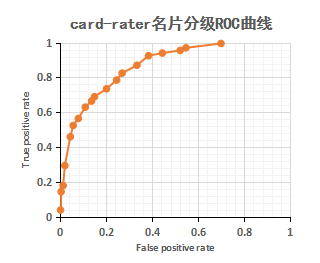
因为数据量不大,模型的调参、测试过程均在桌面 PC 进行。每个样本的计算平均耗时 0.07s。我们绘制 ROC 对 card-rater 的效果进行评价。用户获取团队会结合自己的业务需要选择不同的分数阈值对用户进行召回。
四、业务实施
内部 ERP 系统会每天给 GCDC 的职业顾问分配一个拨打计划,职业顾问按照该拨打计划进行简历的召回。之前拨打计划的生成逻辑是人工指定的规则,如根据行业、地区等方式进行排序。在草稿简历分级模型上线之后,每天由数据团队离线计算好高优先级的候选草稿简历,并按照可能性从高到低进行排序。ERP 团队每天从数据平台拉取相关数据,并生成拨打计划,直接将模型计算的结果推送给 GCDC 的职业顾问,无缝嵌入职业顾问的工作流程。在实施过程中,采取了灰度上线的方式,起初拨打计划中只有一定比例的数据是来自数据团队的模型。对于由数据团队生成的部分,进行了追踪监控,观察效果。并逐渐增加这个比例,最终完全取代老的拨打计划生成规则。该模型从 2015 年 12 月起上线,2016 年 1 月召回简历中商业简历的占比从 51% 提升到 78%,而到 2016 年 3 月时,商业简历占比已经上升到 95%,为业务带来了切实的价值提升。
五、总结讨论
从目前应用的效果来看,自动名片分级系统取得了令人满意的效果。为了进一步提升效果,完成更为强大的名片分级功能,我们考虑从以下三个方面进行后续工作:
(一)尝试新算法进行细粒度的预测
在猎聘的业务中,用户共有 5 个级别。而目前的名片分级系统将之转化为二分类问题。如何实现对五个级别分别进行预测,仍然面临着较大的挑战。我们可以考虑使用有序回归(Ordinal Regression),直接对用户级别进行预测。此外,集成算法(如 Random Forest、Gradient Boosting)以其的优良性能,受到工业界的广泛关注。我们也计划尝试使用该类方法进行探索性试验,以期进一步提高模型的预测准确率;
(二)设计更多的特征
新用户的注册行为本身也蕴含着与其用户级别相关的重要信息,如注册时间、简历完整程度等。后续工作中,我们会尝试对这些行为数据进行挖掘。
(三)解决信息缺失问题
我们模型在使用时的一个基本假设是,用户填写了全部的名片信息。但是实际情况是,有相当比例的新注册的用户未填写职能信息和所在城市信息。这就导致很多的高级用户,因为未提供足够的信息,而在评分系统中得分很低。对此,我们还需要在产品设计、运营等方面做更多的努力。
参考文献
[1] I. Guyon, A. Elisseeff. An Introduction to Variable and Feature Selection. Journal of Machine Learning Research 3 (2003), 1157-1182.
[2] M. Zhang, Z. Zhou. A k-Nearest Neighbor Based Algorithm for Multi-Label Classification. 1st IEEE International Conference on Granular Computing, 2005, 718-721.
[3] X. Wu, V. Kumar, J. R. Quinlan, J. Ghosh, Q. Yang, H. Motoda, G. J.McLachlan, A. F. M. Ng, B. Liu, P. S. Yu, Z.-H. Zhou, M. Steinbach,D. J. Hand, and D. Steinberg. Top 10 Algorithms in Data Mining, Knowledge Information System , vol. 14, no. 1, 2008, 1–37.
[4] T. Chiang, H. Lo, S Lin. A Ranking-based KNN Approach for Multi-Label Classification. JMLR: Workshop and Conference Proceedings 25, 2012, 81-96.
[5] 周志华 著 机器学习. 北京:清华大学出版社,2016.
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:[email protected]),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK