

我就想些个爬虫,怎么要学那么多东西?
source link: https://zmister.com/archives/1618.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

我就想些个爬虫,怎么要学那么多东西?
一开始,老板给了一个任务,需要从网页上复制几百页的数据到本地。一遍一遍的复制粘贴,贴得我身心憔悴。听说有一种爬虫技术,可以自动采集数据,省去了人肉取数的痛苦。
我一听,「诶,这不错,学了就不用再废这双老手了」。
于是网上一搜索,都说 Python 适合写爬虫,而且简单易学,最适合非计算机专业的普通人了。
那就学起来吧。
于是一本 《简明 Python 教程》 就带我入了门。
学完 Python 之后,就打算用 Python 写爬虫了。他们说,爬虫很简单的,就是一个 HTTP 请求到数据,再把数据解析出来就可以了。
我一听,说起来是很简单的,立马找了 python 的 HTTP 请求库——requests。
这也太简单了吧。于是我马上写出了我的爬虫的 HTTP 请求代码来。
但是为什么 HTTP 的响应里面没有我看到的那些数据呢?
在网上问了一下大神,他们说你要先看看网页源码是否有你看到的那些数据,很多网站是通过前端请求接口渲染的数据,直接请求网页是不会有数据的。
虽然听得迷迷糊糊的,但还是用大神们教的方法打开网页源代码。一看,好家伙,果然里面没有我想要的数据。这种情况,直接用requests请求网页是拿不到数据了的。
没辙,按照大神说的,找接口呗。于是按了 F12 打开了浏览器的调试控制台,在一大串看不懂的面板里面一个一个地找。
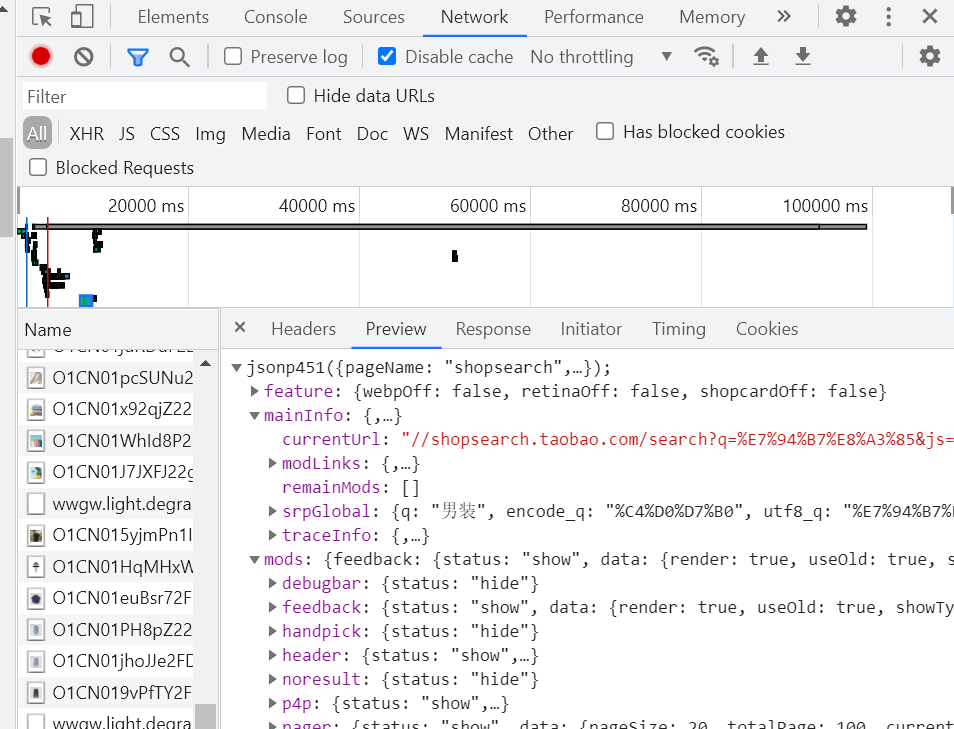
终于看到了一个和我要复制的数据一模一样的接口了。大神说直接 HTTP 请求它。
照做了,还是不行,响应说请求错误。
继续上网搜索,有人说是要携带 「请求头」,天呐,请求头又是什么鬼?
真是学海无涯呀。
网上一顿搜索,知道怎么配置请求头了,然后请求也成功了,数据也打印出来了,本以为大功告成,正打算点一杯奶茶庆祝。
第二页数据请求失败了。
这次响应说「token无效」。wocao!token又是什么鬼!
找了一圈发现,是请求头里面的一个参数,它的值是一串很长的参数。据网上所说,这个是使用JS生成,用来验证请求是否合法的

听说又要学习另一门编程语言,我退缩了。看看有没有别的方法。
嗯,找到了一个叫做 Selenium 的工具,据说可以模拟浏览器进行操作,
这个操作简单多了,简单学习了一下,从浏览器审查元素里面复制数据所在的路径,然后查找定位。
so easy!
虽然速度慢了点,但还是比人肉取数强啊!Python 真香!爬虫真香!
1页,2页,3页,4页,10页,20页,30页……完成工作指日可待!
突然,程序挂了!
一看,浏览器上出现了一个拼图验证码,说我操作过于频繁,需要进行验证码验证。重新启动程序也不行

这可如何是好?
百度大法好,搜一下解决方法。解决方法是有,我人快没了。
一堆没听过的词语又出现了,什么 OpenCV、什么 Keras、什么轨迹、什么计算机视觉。
开始只想采集点数据,然后学了 Python,学了 HTTP请求,学了从浏览器中找接口,为了放弃学习 JavaScript 转而学了 Selenium 浏览器自动化,学了……
不行,我学不动了。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK