

「爬虫实战」采集高校历史录取分数线
source link: https://zmister.com/archives/1617.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

「爬虫实战」采集高校历史录取分数线
高考过后,这几天各省份都陆续放榜。

又到了一年一度的高考志愿填报时间,不管考得好,还是考得不好,基本上,都会有学校就读。
大多数时候,我们只能通过过去的高效录取分数线,来做一个参考,筛选出自己的分数能够报考的学校和专业。
家里人最近让州的先生给查查资料,看家里的小朋友大概能报什么学校。
网上一搜,打开「中国教育在线」的网站(网址:https://gkcx.eol.cn ),筛选起了学校来。
首先选择「院校大全」,来到学校的列表页面:
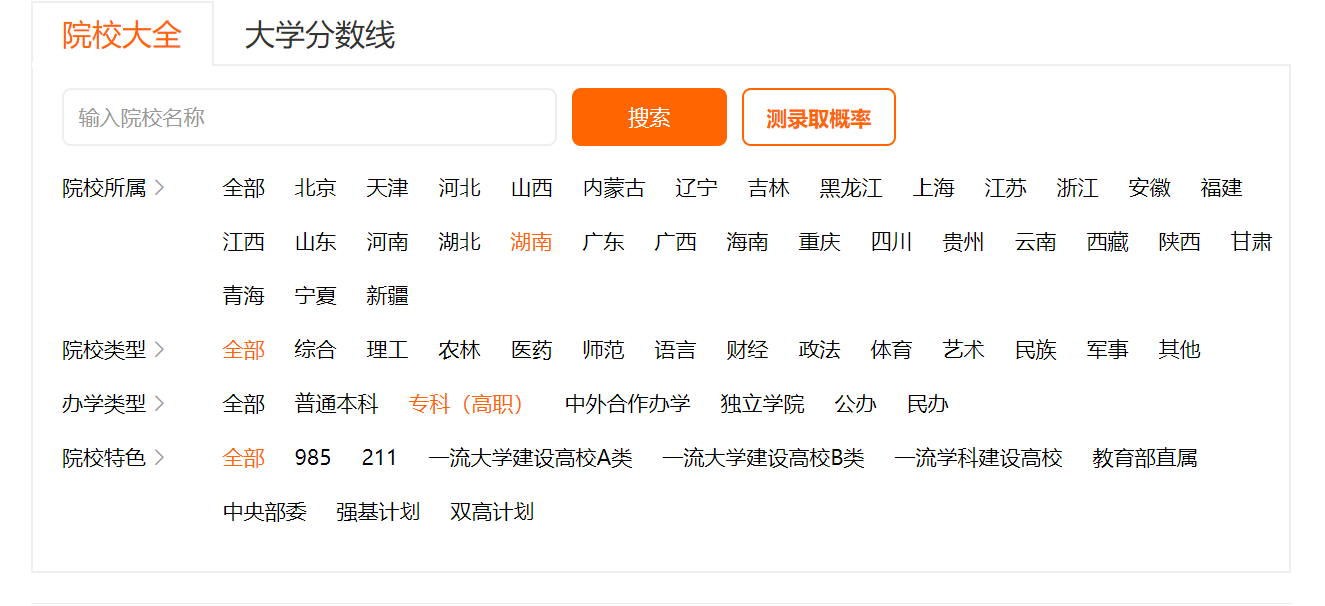
筛选过后,会显示符合条件的学校列表(这里筛选的是高职专科院校,其他的类似):
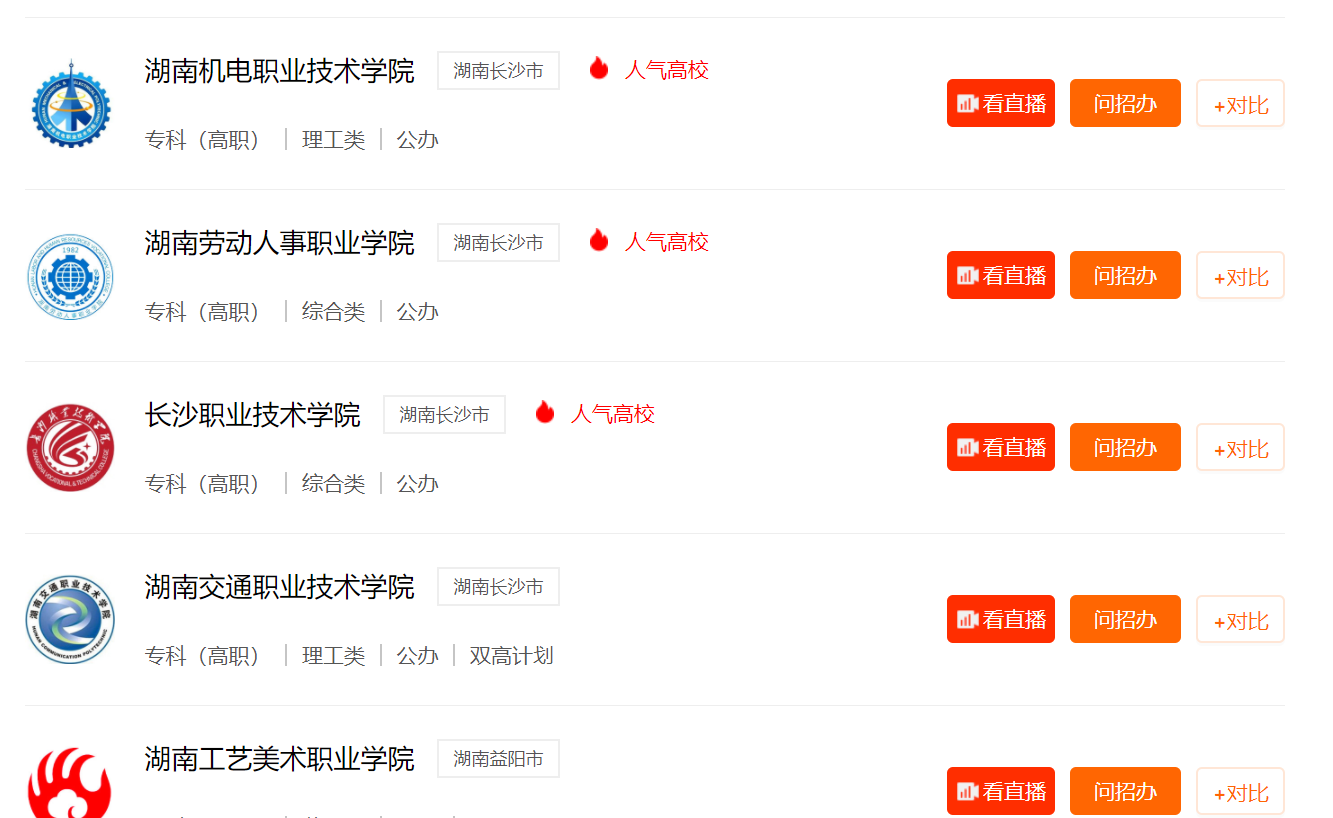
然后点击进入学校的主页,选择「历年分数」:
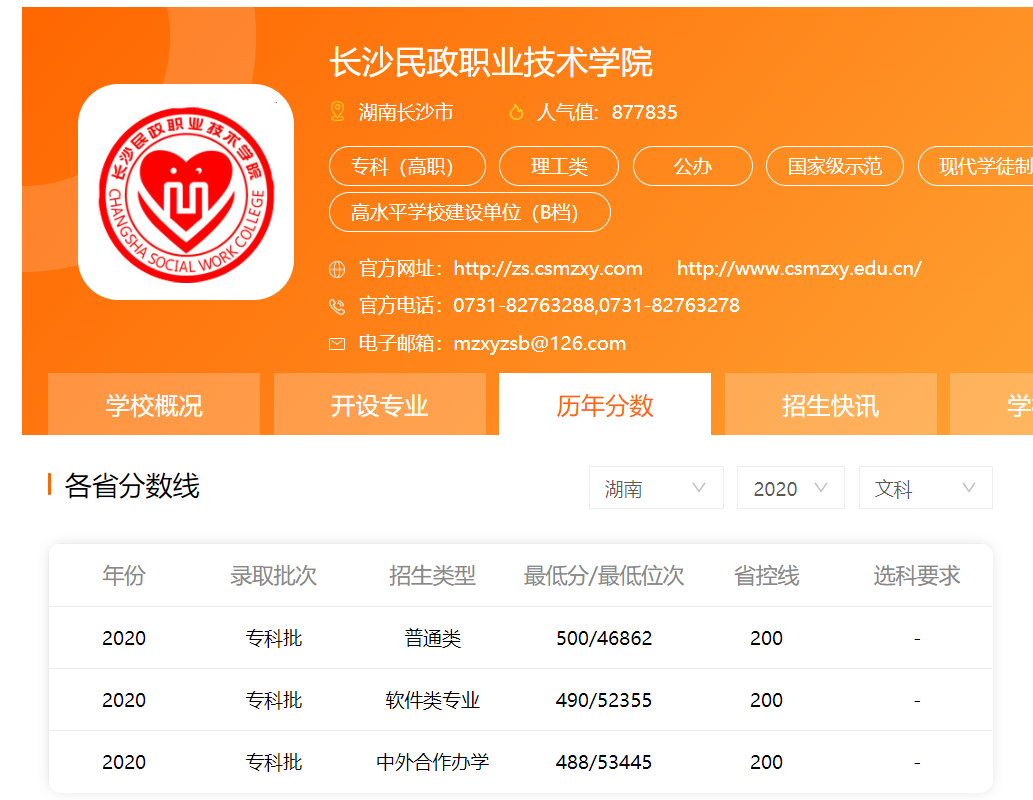
按照省份、科类、年份进行筛选,就可以看到这个学校的历史录取分数线了。
虽然操作没啥难度,但是州的先生一看学校的列表:
一页20个学校,4页就是80个学校,那得查到什么时候去。
打开网页控制台,看了一下,院校列表页面通过接口按查询参数返回学校列表数据,学校列表数据里面有 school_id 字段用于标识这个学校。
院校详情页面的数据也是通过接口传入 school_id 返回的数据。那就索性写个爬虫,省时省力。
文章目录 [显示]
(这里以湖南省的高职专科院校为例)
首先引入所需的库:
import requests
import time
import random
接着编写学校录取分数函数:
def get_school_score(id):
"""
获取学校录取分数信息
@州的先生 zmister.com
:param id: 学校id
:return: 学校最低录取分数线,最低位次
"""
url = 'https://static-data.eol.cn/www/2.0/schoolprovinceindex/2020/{school_id}/43/2/1.json'.format(school_id=id)
header = {
'Accept':'application/json, text/plain, */*',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Host':'static-data.eol.cn',
'Origin':'https://gkcx.eol.cn',
"Upgrade-Insecure-Requests":"1",
'Referer':'https://gkcx.eol.cn/school/{school_id}/provinceline'.format(school_id=id),
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
"Cookie":"areaid=44; cityid=4401; gr_user_id=88b49629-e82b-4044-acda-a46bd74eaed7; 88025341dda01c5f_gr_session_id=cf2c99d4-c376-493a-b916-a4711ed00abf; 88025341dda01c5f_gr_session_id_cf2c99d4-c376-493a-b916-a4711ed00abf=true"
}
try:
r = requests.get(url,headers=header)
data = r.json()['data']['item'][0]
min = data['min']
min_section = data['min_section']
print("最低分:",min,"最低位次:",min_section)
except:
print("暂无")
然后编写获取学校列表的函数,将提取的学校id传入上一个函数内:
# 获取学校列表
def get_school_list():
"""
获取学校列表
@州的先生 zmister.com
:return:
"""
url = 'https://api.eol.cn/gkcx/api/'
header = {
'Accept':'application/json, text/plain, */*',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Content-Length':'355',
'Content-Type':'application/json;charset=UTF-8',
'Host':'api.eol.cn',
'Origin':'https://gkcx.eol.cn',
'Referer':'https://gkcx.eol.cn/school/search?province=%E6%B9%96%E5%8D%97&cityname=&argschtype=%E4%B8%93%E7%A7%91%EF%BC%88%E9%AB%98%E8%81%8C%EF%BC%89&schoolflag=',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
}
for i in range(1,5):
data = {
"access_token":"",
"admissions":"",
"central":"",
"department":"",
"dual_class":"",
"f211":"",
"f985":"",
"is_doublehigh":"",
"is_dual_class":"",
"keyword":"",
"nature":"",
"page":i,
"province_id":43,
"ranktype":"",
"request_type":1,
"school_type":6001,
"size":20,
"sort":"view_total",
# "top_school_id":"[2035,2016,3385,2017]",
"type":"",
"uri":"apidata/api/gk/school/lists"
}
r = requests.post(url,json=data,headers=header)
for d in r.json()['data']['item']:
print(d['name'],d['type_name'],d['school_id'])
get_school_score(d['school_id'])
time.sleep(random.uniform(5,8))
在这里,州的先生设置了随机 5 到 8 秒的时间间隔,这是为了避免高频率请求对目标网站服务器造成的影响。
请谨记,你的高频率采集,很有可能会演变成 DDOS(分布式拒绝服务攻击),进而很有可能触犯刑法的「破坏计算机信息系统罪」
最后,运行代码即可:
if __name__ == '__main__':
get_school_list()
运行这个采集代码,我们会在控制台得到如下所示的打印信息:
湖南商务职业技术学院 财经类 2001
最低分: 471 最低位次: 62651
湖南铁道职业技术学院 综合类 1998
最低分: 486 最低位次: 54544
湖南城建职业技术学院 理工类 2022
最低分: 385 最低位次: 108265
湖南化工职业技术学院 理工类 2021
最低分: 401 最低位次: 99989
湖南高速铁路职业技术学院 理工类 2034
最低分: 434 最低位次: 82297
数据采集下来了,更进一步地,打算对这些数据进行一下处理,按照录取分数的高低,对学校进行一下简单的排序。
这里,我们直接使用 pandas 模块进行数据处理:
import pandas as pd
school_list = []
score_list = []
result = []
for i in str.splitlines():
if i.startswith('最') is False and i.startswith("暂无") is False:
school_list.append(i)
else:
score_list.append(i)
for s1,s2 in zip(school_list,score_list):
row = s1.split(' ')[:2]+s2.split(' ')
print(row)
try:
item = {
'name':row[0],
'type':row[1],
'min_score':row[3],
'min_section':row[5]
}
result.append(item)
except:
pass
df = pd.DataFrame(result)
df.sort_values('min_score',ascending=False).to_csv('./result.csv',encoding='utf-8')
代码中的str是打印在控制台上的采集的数据,我们将其复制到编辑器中,赋值给str变量。
运行代码,可以得到如下所示的CSV文件:

如果需要这份采集结果的 Excel 文件,可以添加州的先生私人微信:taoist_ling,备注:录取分数文件,我将发送给你。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK