
7

python重量级爬虫框架scrapy
source link: https://www.80shihua.com/archives/1986
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
python重量级爬虫框架scrapy
作者: dreamfly 分类: python 发布时间: 2019-01-31 23:03
提起爬虫,大家一定会想到python,想到python,一定会想到scrapy,可以说不会scrapy,你就是没有掌握爬虫,没有体会到爬虫的精髓。
首先介绍下如何安装,基本上我们在有了pip包管理工具之后,我们基本都使用pip来安装第三方库。 pip install scrapy
安装好后,我们就可以使用pip命令,命令行输入pip就可以查看它的使用方式。
通过scrapy fetch url就可以进行基本的抓取查询
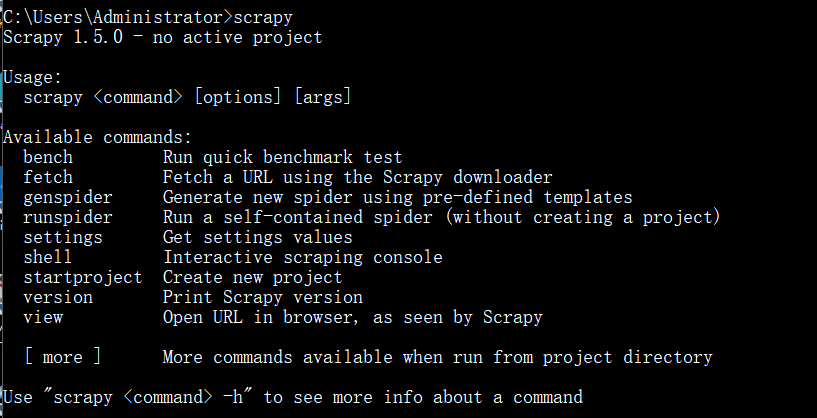
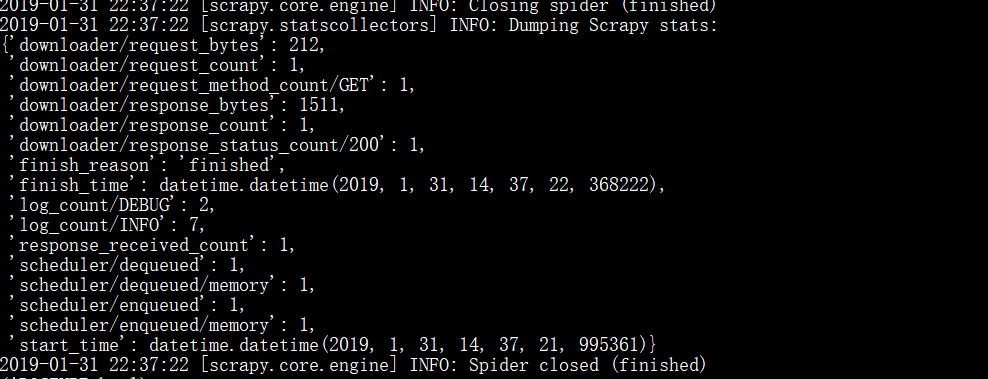
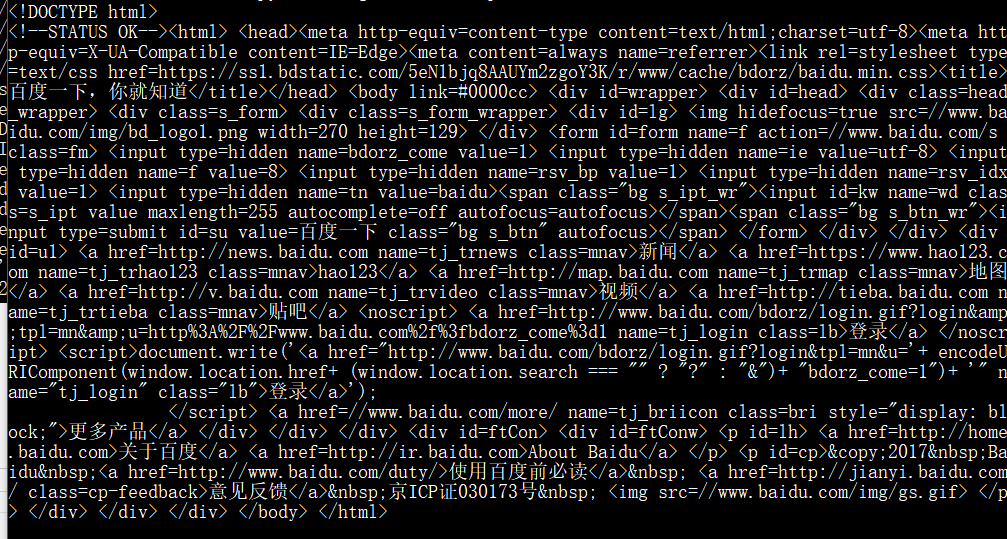
这里我们可以看到网页的基本信息,网页源代码。
当然,我们还可以测试一些匹配规则,进行验证,比如,我们获取下底部的关于百度链接。这个就是通过scrapy shell 进行分析,比如scrapy shell https://www.baidu.com/
然后我们输入response就可以看到相应结果,<200 https://www.baidu.com>
比如我们要获取网页的title

使用chrome浏览器审查元素后,我们有件就可以获取到xpath路径,非常方便我们查询到内容。
通过执行fetch('https://www.80shihua.com'),我们就可以换取新的网站进行分析。
如果觉得我的文章对您有用,请随意打赏。您的支持将鼓励我继续创作!
发表评论 取消回复
电子邮件地址不会被公开。 必填项已用*标注
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK