

Uber 机器学习平台的高速迭代实践
source link: https://tech.ipalfish.com/blog/2021/05/31/uber-michelangelo-pyml/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文是「算法工程化实践调研」系列的第 3 篇,介绍来自 Uber 在 2018 年 10 月发布的技术博客 Michelangelo PyML: Introducing Uber’s Platform for Rapid Python ML Model Development [1]。它介绍了 Uber 机器学习平台(以下简称平台)为了提高基于 Python 的迭代效率,而进行的一个有趣的演进。
性能 vs 迭代效率
我们在 Uber 机器学习平台实践一文中提到,平台早期着重于提高模型训练和预测的性能,而较少考虑迭代效率。
因此,对于平台内置支持的模型(XGBoost、GLM、回归等),算法工程师可以很容易地使用平台进行超大规模训练、在线和离线预测。然而,对于平台尚未内置支持的模型,例如最新发表的研究成果(Google BERT 等),则必须等到平台在特征工程、模型训练、模型部署和模型服务等多个环节均支持该模型,才能开始模型的线上评估。
这就带来一个问题。如果工程师花费了很多力气,终于用 Java / Scala 在平台层面支持了新模型,而模型上线后,模型评估的结果不佳,需要弃用该模型,那么前面的功夫就就都白费了。
因此,平台希望提供一条捷径。允许算法工程师调用任意 Python 库实现模型,并快速上线模型开始评估。如果模型评估的结果理想,算法工程师再和平台工程师配合,将新模型集成到平台上,提供高并发、低延迟的服务。通过这个捷径进行的训练和预测任务,并不需要满足超大规模和超低延迟的需求,唯一重要的就是迭代效率。
PyML 应运而生。算法工程师在本地完成特征工程和模型训练后,可以调用 PyML API 进行模型部署和模型服务调用,快速开始模型的线上评估,大大缩短迭代周期。如下图所示,相比于更早期的平台,有 PyML 加持的平台更着重于灵活性和迭代效率。

下面,让我们看看算法工程师如何使用 PyML 上线一个简单的回归模型。
PyML 工作流
第一步,算法工程师将训练所需的数据下载至本地,在 Jupyter Notebook 中使用任意 Python 库进行特征和标签的获取,以及模型的定义,并利用本地资源进行训练,得到训练好的模型 log_reg。
feature_columns = ...
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
第二步,保存模型的状态,存储在名为 prediction_model 的文件夹中。
!mkdir -p prediction_model
from sklearn.externals import joblib
joblib.dump(log_reg, 'prediction_model/weights.pkl')
import pickle
pickle.dump(feature_columns, open('prediction_model/feature_columns.pkl', 'wb'))
第三步,基于模型实现封装类,保存为 model.py。 scikit-learn 模型的封装类会继承 DataFrameModel ,在 predict 中返回 DataFrame;TensorFlow 和 PyTorch 模型的封装类会继承 TensorModel ,在 predict 中返回 Tensor。除了实现预测接口,封装类还需要在构造函数中载入前一步存储的模型状态。
%%writefile prediction_model/model.py
import pandas as pd
import numpy as np
import pickle
from pyml.model.dataframe_model import DataFrameModel
from sklearn.externals import joblib
class LogisticRegressionModel(DataFrameModel):
def __init__(self):
super(LogisticRegresstionModel, self).__init__()
self.clf = joblib.load('weights.pkl')
self.feature_columns = pickle.load(open('feature_columns.pkl', 'rb'))
def predict(self, df):
df['probability'] = self.clf.predict_proba(df[self.feature_columns])[:,0]
return df
第四步,声明库依赖。
%%writefile prediction_model/requirements.txt
pandas
numpy
scipy
scikit-learn
第五步,从本地文件系统载入封装好的 PyML 模型。
from pyml import PyMLModel
pyml_model = PyMLModel(model_path='prediction_model/', model_name=example_prediction_model)
第六步,调用 upload_model 接口,创建 Docker image 并上传至模型仓库,由平台进行包括版本控制在内的模型管理。
from pyml import Client
client = Client()
model_id = client.upload_model(pyml_model)
第七步,调用 deploy_model 接口,部署模型服务。
client.deploy_model(model_id)
几秒钟后,一个 Docker 容器就位,里面运行了一个在线预测服务和一个内嵌的 Docker 容器。该内嵌容器内运行了模型服务。
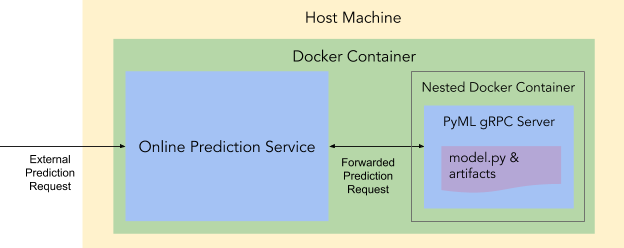
至此,算法工程师完成了模型上线的过程。此时,可以调用 predict_online 接口,发送预测请求。
# Online prediction
X = ...
y = client.predict_online(model_id, X)
也可以调用 predict_offline 接口,该接口启动一个容器化的 PySpark 工作流,从指定数据源读取数据,并将预测结果批量写入指定的表。
# Offline prediction
DESTINATION_TABLE = 'example.predictions'
SOURCE_DATA_QUERY = """SELECT * FROM exmple.data"""
batch_job = client.predict_offline(model_id, SOURCE_DATA_QUERY, DESTINATION_TABLE)
assert batch_job.wait() == 'success'
最后,算法工程师在平台上,使用与评估非 PyML 模型一样的流程,对 PyML 模型进行评估,针对性地调整模型。在确定模型可行后,才开始着手在平台层面对模型进行支持,随后将模型从 PyML 迁移到平台上。
初代 Michelangelo 平台在「高性能还是高速迭代」之间选择了高性能。补充了 PyML 的新生代平台说,「我全都要」。
[1] Michelangelo PyML: Introducing Uber’s Platform for Rapid Python ML Model Development. https://eng.uber.com/michelangelo-pyml/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK