

为以太坊引入 KZG 承诺:工程师视角
source link: https://ethfans.org/posts/kzg-commitments-in-ETH-engineering-view
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

为以太坊引入 KZG 承诺:工程师视角
曾汨 | 17. Jun, 2021 | 106 次阅读
(译者注:本文所介绍的技术在密码学社区里一般称为 “KZG10 承诺”,得名于论文三位作者的姓氏首字母。但在介绍到以太坊生态中时,被简化成了 “Kate 承诺”,甚至连核心开发者也是这么称呼的。这是对另外两位作者的不尊重,不应该继续下去。在本译文中,凡原作者使用 “Kate commitment” 的地方,都一律译为 “KZG10 承诺”。)
免责声明 :本文仅仅是汇集、链接了许多已经公开的成果,对应的荣誉(包括本文所链接的图片)应归属于相应的 作者/开发者。
P.S. :特别感谢 Ethereum R & D discord 频道(尤为感谢 @vbuterin 和 @piper)帮助我理解 KZG10 承诺的某些方面。此外,还要感谢 @vbuterin 帮忙审校本文。
PPS :本文是出于 lodestar 团队的利益而撰写的;lodestar 是一个很棒的 ETH PoS 客户端,基于 typescript,可以让以太坊的服务 无处不在,也开启了作者对以太坊生态和创新的理解。
我希望本文也能对全世界的其他 开发者/技术人员 有所帮助。 本文遵循 CC0 自由创作公约,作者已放弃所有权利。
作为一个有益的指南,帮助读者熟悉、总结以太坊背景下 KZG10 承诺的提议用法,并提供深入理解的指南。
本文的目的更多是总结,而非严谨,不过,您可以点击文中所附的链接,它们会有更详细的解释。
注-1:哈希值就是一个对被哈希的原像的承诺,用于检验被哈希的数据的完整性。(译者注:这话其实不是很严谨。因为哈希函数往往难以满足 “承诺方案” 所需的性质。)
举个例子,假设 h1 = H(t1, t2, t3..),然后把 h1 交给验证者(比如,把它放在区块头内),然后给出一个伪造的区块 (t1,t2',t3...),对方快速计算这个伪造区块的哈希值之后,发现两者对不上,就可以合理地拒绝你的伪造区块。
类似的,一棵默克尔树的根节点,就是对按特定索引(路径)组织起来的所有叶子节点的承诺。或者简单来说,是对 indexes => values(从索引值到数值)的映射的承诺。

而这里的 “证明” 就是一个叶子的 默克尔分支(merkle branch) 以及(这个分支在每一层上的) 兄弟哈希值(sibling hashes),凭借这些数据,可以逐级向上哈希,并通过最终的哈希值是否与根节点一致来判断该叶子是否与这棵默克尔树一致(存在于这棵默克尔树上)。

可看看这里的介绍 : )。
注-2:数据映射与一个多项式的对应关系
indexes => values 这样的数据映射可以表示为一个多项式 f(x),并且 f(index)=value(由拉格朗日插值法可知满足这个条件的多项式必定存在)。“ f(index)=value ”通常被称为 求值形式,而 “ f(x)=a0+ a1.x + a2.x^2... ” 则是其 系数形式。直观来说,我们其实是根据映射中所有的 (index,value) 点,拟合出了一个多项式。

为了简便计算,并确保多项式与数据映射的一一匹配,我们不使用索引值来作为 f(x) 的 x,用的是 w^index,也就是 f(w^index)=value,其中 w 是 d 次单位根(即 w^d = 1 且 w 是一个复数),而 d 是该多项式的次数(也是我们能够包含的索引值的个数上限)。因此,我们可以使用快速傅立叶变换来实现高效的多项式计算,比如乘法和除法,在求值形式下其计算复杂度会是 O(d),而且可以在 O(d*log(d)) 的复杂度内转化回系数形式。所以保持 d 数值较小还是很有好处的。

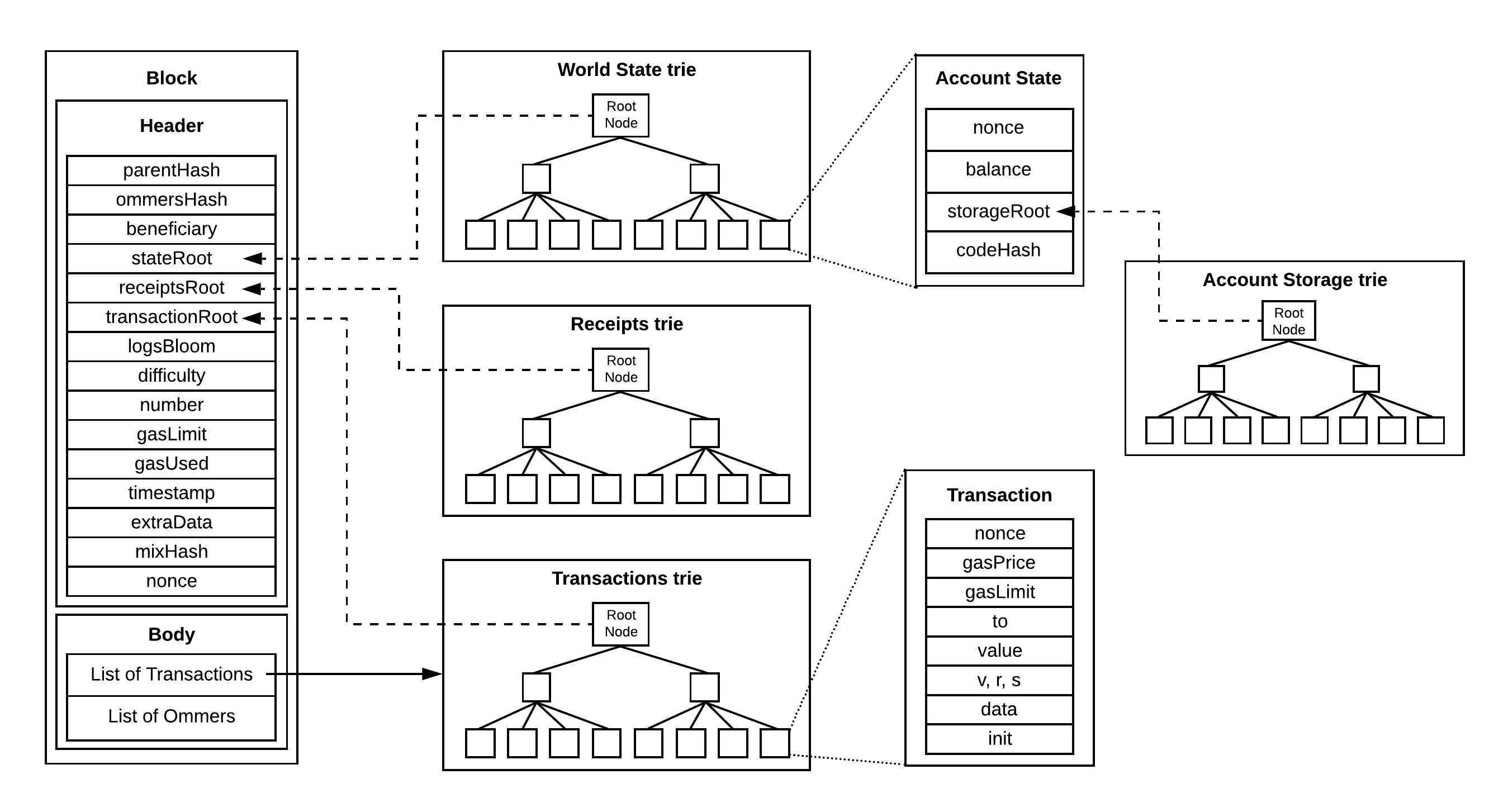
注-2.1:以太坊的状态是一个从地址到账户状态(addresses => (version,balance,nonce,codeHash,storageRoot))的映射。

以太坊当前使用默克尔树(更具体一些是 “帕特里夏默克尔树”)作为 EVM 数据(EVM 状态、区块事务及事务收据,也许还有最近的合约代码)的承诺。此种承诺方式可以:
{kind=link}
- 逐个区块地 插入/更新 数据,以增量的方式产生新的根哈希(即承诺)
- 验证者可以逐个区块(甚至逐笔事务)地校验和证明
前缀树结构在这里提供了这种逐块更新的特性。

给定一个 d 叉的、有 N 个叶子的前缀树,任意更改一个叶子节点,都需要更新 O(log-d(N)) 个节点(也就是该叶子与根节点相连路径上的节点数量)以计算反映新状态的新根值;而这需要额外的 (d-1)*O(log-d(N)) 个 兄弟节点哈希值/承诺 来用作时间和空间(假设要服务于轻节点)的见证数据(witness)。一个区块可视为一个需要更改 m 个随机叶子的批量更新,且 m<<N。因为预计只有一小部分的节点可以共享 witness 和计算,所以,每次更新的 Order(复杂度)不会有太大改变。
在下列情况下,问题还会变得更加严重(因为见证数据的规模):
- 部分采用快速同步的协议,比如 beam sync(光子同步),会下载并快速验证区块头来追上最新的主链顶端并参与网络的共识,注意,它不会先行构建好完整的状态再参与共识,而是(在共识中)通过获取 错过的/未加载的 状态的见证数据,来逐步构建出完整的状态
- 为 轻节点 服务的时候,他们只关心自己,只想获得区块链状态的特定部分
- 网络走向完全无状态时,所有的事务和合约操作,都要附带相关的见证数据,来证明数据输入和输出的正确性(译者注:粗体为译者所加)
- 在验证者会被混洗到不同分片的区块链分片模型中,要让验证者每到一个分片就构建完整状态是不现实的
- 代码默克尔化,访问代码时需要附带这些代码块的见证数据
- 在状态保质期协议中,访问过期的账户需要重新附带状态见证数据,以便重建该账户的状态
(译者注:需要解释的是,在当前的以太坊网络中,事务和区块不会附带上文所述的见证数据。即,网络所传播的见证数据规模与 事务/区块 的规模无恒定的关系。前两种情形恰好是在当前以太坊协议下为数不多的、需要传播见证数据的情形。我们关心状态数据的规模,完全是出于一种协议改进方向 —— “无状态性” 的需要。后面四种情形都跟无状态性有关,当然都比理论上要传播的数量更多。但是,以上述的理论计算来作为基准点去比较,本身是不合适的 —— 连代码默克尔化这种在无状态下节省状态数据的方案,也会被归为让情况更严重的方案。)
在无状态以太坊项目的一个实验中,出现了 1 MB 的区块证据(其中大部分都是默克尔证据),在发生攻击的时候还会膨胀好几倍。

其中一种解决办法是转为使用 “二进制默克尔树”,也就是把 d 降下来,这样虽然树的深度(高度)会增加,但仍然是 O(log(N)) 的规模。

为什么要使用 KZG10 承诺?
对于要放在区块头内承诺数据的承诺方案来说,以下特点是理想属性:
- 证据的数据量较小,可以塞进区块头里,且仍具有很强的安全保证
- 易于证明某个承诺是使用分组化数据(chunkified data)的一个子集生成出来的
- 足够小,最好证据的数据量是恒定的
- 为了跟踪数据,承诺应当易于以增量的形式变更
基于KZG10 承诺的方案就是大家一番搜寻的结果。

什么是 KZG10 承诺?
KZG10 承诺可以视为另一种哈希方案,只不过它哈希的不是 “字节”(数据),而是多项式。
实际上,它就是 计算(evaluation) 多项式 f(x) 在秘密的定点 s 上的值,只不过 它们都是表示在一条椭圆曲线上的,也即 [f(s)]=f([s])。这需要一个受信任的启动设置(跟 zcash 区块链的创世活动一样),来生成[s]、[s^2]、… [s^d](以便在多项式需要 x^i 的地方插入),而 d 就是多项式的最大阶数。

这里的 [t] 表示点 t 处的椭圆曲线值,也就是 t[1],是椭圆曲线加法群的生成点([1])相加 t 次(等同于对 Fp 求模,modulo Fp )。椭圆曲线上的所有计算都是对 Fp 求模,Fp 给曲线施加了一定的范围(译者注:Fp 是一个由 p 个元素组成的有限域,限制了该椭圆曲线值的范围)。
注 3.0:在 indexes=>values 的映射中,所有的 值 都要表示为一条椭圆曲线上的元素,即 [value],以便计算承诺(后文有详述)。这就使得 value 的大小有了限制(为了要成为 modulo Fp 的值)。在 BLS 曲线上,大概在 31~32 字节之间。为了简便,value 的大小就限制在 31 字节,任意更大的 值 都要分块化,并用其索引值来恰当地表示(或者截断)。

注 3.1:[t] 可以被视为 t 的哈希值,因为从 [t] 找回 t 是个离散对数问题(discrete log problem),对于安全的曲线来说,是很难做到的。
*注 3.2:s 是一个秘密的数值,永远不应泄漏给 任何人/所有人,但椭圆曲线点 [s], [s^2]…[s^d] 及其在另一条椭圆曲线上的值 [s]' (其生成点为 [1]' 且只需知道 [s]' )则应生成并公开出来,让所有人知道。这就是启动设置要做的事。 *
这些 系统参数 定义了整个系统的安全性,因为 s 暴露会使得攻击者可以构建任意内容的 证据。因此,一个有 N 个参与者共同参与的启动设置仪式中,他们要通过协议把本地的 s 结合起来,这样只要有 1 个参与者是诚实的、在参与之后就销毁掉了自己提供的 s,这个系统就会是安全的。即,信任模型是 1/N 模型,N 越高,风险就越低。
*注 3-3:[] 是一个线性的操作,即[x]+[y]=[x+y],而且 a[x]=[ax]。 *
如果上所述,我们将数据映射(索引值 => 数值)表示为 f(w^index)=value,即一个多项式的求值形式,也可说,我们用这些 (w^index,value) 点拟合出了一条曲线(多项式)。
所以,一个多项式 f(x) 的 KZG10 承诺c(f) 是一个椭圆曲线点 f([s]),这个点可以靠在 f(x) 的展开式中插入 [s],[s^2] … 计算得出。
注 3-4:f(s) 是无法计算的,因为 s 是个秘密值。但是 C(f)=[f(s)]=f([s]) 是可以计算的。
注 3-5:f(x)的承诺 C(f)=[f(s)] 也是一个线性的运算符,即,C(f+g)=C(f)+C(g)。
Rollup/聚合器 可以使用这一属性来更新承诺。在求值形式下,更新一个求值点将导致 f(x) 完全改变,但因为有这个属性,其承诺 c(f) 仍然是易于更新的。
注 3.6:如果启动设置所计算的 [s],[s^2]…[s^d] 只计算到了指数 d,这一组值是不能用来生成任何阶数大于 d 的多项式的承诺的。反之亦然。
因为在安全的曲线上,没有办法用两个点相乘来得出第三个点,所以 [s^(d+k)] 是一个(永远!)无法求出的值,因此可以说,任意的承诺 c(f) 都只能表示一个阶数小于等于 d 的多项式。
*注 3.7:使用 KZG10 承诺的证据基本上就是在证明 f(x) - 某些余数 的结果可以按特定的办法来分解,但这就要有一种办法可以 *相乘 这些因数,并与原始的承诺相比较 C(f)=f([s])。 **
为此,我们需要 “配对方程”,就是一种能把曲线上的两个点相乘并与另一个曲线点比较的乘法,因为我们无法直接让这两个曲线点直接相乘来得到合成的曲线点。
注 3.8:上述两个属性,可以进一步用来证明某个承诺 c(f) 所代表的多项式 f(x) 的阶数 k 小于 d。
综上,KZG10 承诺可以有很好的属性:
-
验证承诺的过程是:(由区块生成者)提供底层多项式在任意点
r上的值y=f(r),以及除法多项式q(x)=(f(x)-y)/(x-r)在[s]点的值(即q([s])),并用 配对方程 来对比之前所提供的承诺f[s]。这就叫 开启 在 r 点的承诺,而q([s])就是证据。容易看出,q(s)就是p(s)-r除以s-r,恰好就是我们用配对方程来检查的东西,即检查(f([s])-[y]) * [1]'= q([s]) * [s-r]'(译者注:此处疑为f(s)-r,但原文就是p(s)-r)。 - 在非交互且确定性的版本中, Fiat Shamir Heuristic 提供了一种办法来获得相对随机的点 r:因为随机性只跟我们尝试证明的输入有关,即,只要已经有了承诺
c=f([s]),r 就可以用哈希所有输入(r=Hash(C,..))来获得,而 承诺的提出者 要负责提供 开启点 和 证据。 - 使用预先计算好的拉格朗日多项式,
f([s])和q([s])都可以在 求值形式 下直接计算。要计算 r 处的开启值,就需要把 f(x) 转为f(x)=a0+ a1*x^1....的系数形式(也即抽取出a0、a1、…)。可以通过 反向快速傅立叶变换 来实现,复杂度为O(d log d),但甚至这里也有一种可用的替代算法,在O(d)的复杂度内完成计算,而无需使用反向快速傅立叶变换。 你可以使用单个开启点和证据来证明 f(x) 的多个值,也就是多个索引值对应的数值,
index1=>value1、index2=>value2…- (用于计算证据的)除法多项式 q(x) 现在变成了 f(x) 除以零多项式
z(x) =(x-w^index1)*(x-w^index2)...(x-w^indexk)的商 - 余数为
r(x)(r(x)是一个最大阶数为 k 的多项式,由index1=>value1,index2=>value2…indexk=valuek插值而成) - 检查
( f([s])-r([s]) )* [1] ' = q([s]) * z([s]')
- (用于计算证据的)除法多项式 q(x) 现在变成了 f(x) 除以零多项式
在 PoS 链的共同起步设置中,共享的数据块会被表示为低阶的多项式(并为了 纠删码 而使用同样的 拟合 多项式扩展为两倍大),KZG 承诺可以用来检查任意 随机 分块并验证和确保 数据可得性,而无需获得 兄弟数据点。这就开启了随机取样的可能性。
现在,对于一个最大可能包含 2^28 个账户键的状态,你需要至少 2^28 阶的多项式来构建 扁平的 承诺(flat commitment)(实际上的账户键总空间会大得多得多)。在更新和插入的时候,会有一些不便利。对任一账户的任意更改,都会触发承诺(以及更麻烦的,见证数据/证据)的重新计算。
更新 KZG10 承诺
- 对任一
索引值 => 数值点的任何更改,比如更改了indexk,都需要使用相应的拉格朗日多项式来更新承诺。复杂度约为每次更新O(1)。 但是,因为 f(x) 本身也改变了,所以所有的见证
q_i([s]),也即所有对第 i 个键值对的见证,也需要更新。总复杂度约为O(N)- 如果我们没有维护预先计算好的
q_i([s])见证,任何一条见证数据都要从头开始计算,都需要O(N)
- 如果我们没有维护预先计算好的
- 一种复杂度为
sqrt(N)的更新 KZG10 承诺的构造
因此,为了实现理想承诺方案的第四点,我们需要一个特殊的构造:Verkle trie。
Verkle 树
需要表示的以太坊的状态大约有 2^28 约等于 16^7 约等于 2.5 亿 个键值对。如果我们只使用扁平的承诺(那么我们需要的阶数就至少是 2^28)。虽然我们的证据永远是 48 个字节的椭圆曲线元素,但任意的插入或更新,都需要 O(N) 次操作来更新所有预先计算好的见证数据(也就是所有点的 q_i(s) ,因为 f(x) 本身已经改变了);甚至于,如果没有预先计算好的见证数据,则每条见证数据都需要花 O(N) 来重新计算。
因此,我们需要把扁平的结构换成叫做 Verkle 树 的结构,跟默克尔树一样是树结构。

即,像默克尔树一样,构建出一棵承诺树,这样我们就可以保证阶数 d 比较小(但也需要高达约 256 或者 1024)。
- 每个父节点都编码对其子节点的承诺,子节点就是一个映射,其索引值都存在其父节点内
- 实际上,父节点的承诺编码了哈希后的子节点,因为承诺的输入是标准化的、32 字节的值(见上文的 注3.0)。
- 叶子节点编码了对其所存储的数据的 32 字节哈希值的承诺;或者直接跳转到数据,假如其 32 字节的数据的用法与下一章提到的 状态树 提议用法一样的话。
- 要提供对一个分支的证据(类似于默克尔分支证据)时,一个多值证明的承诺
D、E可以围绕使用 fiat shamir heruristic 产生一个相对随机的点 t 来生成。
复杂度
这里是一份对 Verkle 多值证明的分析
- 更新/插入 叶子节点
index=>value需要更新log_d(N)个承诺 ~log_d(N) 为生成证据,证明者需要
- 计算
f_i(X)/(X-z_i)在[s]处的值,用于生成D,复杂度总计O(d log_d N),但可以在 更新/插入 时调整以节约预计算,复杂度会变成O d log_d(N) - 计算
m个 ~O( log_d(N) )个f_i(t)来计算h(t),总计为O (d log_d N) - 计算
π,ρ,需要对m~ log_d N个指数多项式的和做除法。需要约O(d log_d N)来获得分子的求值形式,以计算除法
- 计算
- 证明的规模(包括用于计算
E的分支承诺)加上验证的复杂度 ~O( log_d(N) )
Verkle 树构建
单一的树结构,存储账户的 header 和 代码分块,还有 存储项分块,节点的承诺为阶数 d=256 的多项式
- 把地址和 头/存储空档 结合起来推导出一个 32 字节的
storageKey,本质上就是元组(address,sub_key,leaf_key)的一种表示 - 所推导的键的前 30 个字节用于构建普通的 verkle 树节点 pivots
- 后 2 个字节是一个树高为 2 的子树,表示最多 65536 个 32 字节的分块
- 对于基本的数据,这个树高为 2 的子树最多有 4 个叶子承诺,来覆盖 haeader 和 code
- 因为一个分块为
65536*32字节的分块表示为单个的字数,所以主树上可能有许多子树来存储一个账户 Gas 定价方案
- 访问类型
(address, sub_key, leaf_key)的事件 - 每一个专门的访问事件都收取
WITNESS_CHUNK_COST - 每个专门的
address,sub_key组合都收取额外的WITNESS_BRANCH_COST
- 访问类型
代码默克尔化
代码会自动成为 verkle 树的一部分(作为统一的状态树的一部分)
- 一个区块的 header 和 code 都作为一个树高为 2 的承诺树的一部分
- 单个分块最多有 4 条见证数据,分别收取
WITNESS_CHUNK_COST,访问账户需要收取一次WITNESS_BRANCH_COST
数据采样和 PoS 协议中的分片
ETH PoS 的目标之一是能够提交约 1.5MB/s 的数据量(把这个吞吐量理解为状态变更的吞吐量,因而是 L2 rollup 可以利用的交易吞吐量,最终是 L1 EVM 的吞吐量)。要实现这一点,许多并行的区块提议要能发出并在给定的 12 秒内验证;也就是要存在多条分片(约 64),每个分片在每个 slot 都要发布自己的数据块。若有大于 2/3 的投票支持,信标链区块将包含分片数据块,分叉选择规则也将根据信标链区块内所有数据块及其祖先的数据可得性确定它是否能成为主链区块。
注 3:此时的分片不是链,任何隐含的顺序都要由 L2 协议来解释。
KZG 承诺也可以用来构建数据有效性和可得性方案,客户端无需访问分片提议者发布的完整数据就可以校验其可得性。

-
分片数据块(不带纠删码)是
16384个样本(每个 32 字节),约为 512 kb;还有数据头,主要由这些样本相应的最大 16384 阶的多项式承诺组成- 但多项式求值形式
D却有2^16384的规模,即,1,w^1,…w^,…w^32767,而 W 是 32768 的单元根(不是 16384 的) - 我们可以为数据(
f(w^i)=sample-ifori<16384)拟合出最大 16384 阶的多项式,并扩展到 32768 作为纠删码样本,即计算f(w^16384)…f(w^32767) - 对每个点的值的证明也同时计算并与样本一起发布
- 32768 个样本中获得任意 16384 个都可以完全恢复出 f(x) 以及原始的样本,即
f(1),f(w^1),f(w^2)…f(w^16383)
- 但多项式求值形式
这纠删编码的 32768 个样本分为 2048 个分块,每个分块包含 16 个样本,即 512 字节的数据;由分片提议者水平地发布,即将第 i 个分块以及相应地证据发给第 i 个垂直子网络,外加全局公开完整数据的承诺
-
在被指定的 (shard, slot),每个验证者都在
k~20个垂直子网中下载和检查这些分块,并使用对应数据块的承诺来验证它们,以建立数据可得性保证- 我们需要为每个 (shard, slot) 安排足够多的验证者,使得总体上一般(乃至更多的数据)都被获取了;另外,还要满足一些统计学上的要求,每个 (shard, slot) 约 128 个委员,需要有至少 70 个(也即 2/3 )委员的见证,使得该分片数据块能成功打包到信标链上,
- 至少需要约 262144 个验证者(32 个 slot,乘以 64 个分片,再乘上至少 128 个委员)
如我们在 POC verkle go 代码库中看到的,以状态树的规模构建完一次 verkle 之后,插入和更新都非常快:

插入/更新 的基准测试

证明生成验证的基准测试

原文链接: https://hackmd.io/yqfI6OPlRZizv9yPaD-8IQ
作者: g11tech
翻译: 阿剑
你可能还会喜欢:
![]()
微信扫一扫
分享至朋友圈
Recommend
-
25
腾讯云在这次事件中的结论表述为因受所在物理硬盘固件版本Bug导致的静默错误,文件系统元数据损坏:根据这个表述,故障应出现在硬盘固件故障导致的文件系统元数据损坏。这其中,涉及具备因果关系的三个知识点:硬盘固件故障—>文件系统元数据损坏—>文件损坏。...
-
21
默认情况下,你在以太坊上所有的交易历史和余额都是公开的。通过诸如 Etherscan 这样的区块浏览器可以查看所有的交易,某人但凡知道了你的地址,就可以轻轻松松获取你的支付记录、跟踪你的资金来源、计算你的持仓、甚至分析你的链上活动。...
-
22
一直忙着做安服项目,好久没发稿了,今天特意抽出时间写篇文章,希望能帮助到大家。作为一直在乙方做渗透测试的攻城狮,入行之前在freebuf上看过类似渗透测试流程的文章,当然对我的帮助不少,非常感谢。但是现如今再次翻看这些文章,发现...
-
5
引言自 2015 年创世以来,以太坊区块链已历经五个寒暑。五年的时间不仅把作为一种理念的以太坊协议 1 变成现实、使这套协议变得更加成熟、更加具体,也使这样一套设计的特性和权衡关系暴露出来。这些权衡关系,作为设计上的挑战,自...
-
4
以太坊伦敦硬分叉预计于周四到来,将引入EIP-1559 作者:BENJAMIN PIRUS | 编译者:Maya | 来源:Cointel...
-
9
零知识证明 - KZG多项式承诺 零知识证明 - KZG多项式承诺 ...
-
5
Aave V3将引入支持以太坊Layer 2以及跨链等功能 • 8 小时前 碳链价值APP讯,Aa...
-
3
Evmos对以太坊互操作性做出承诺后,Cosmos生态内代币价格飙升 作者:JORDAN FINNESETH | 编译者:Maya | 来源:
-
5
← 今日好价 0524猴痘爆发:目前已知的信息(截至5月21日) →
-
0
独家新闻:Netflix历史性地引入软件工程师级别 ...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK