

【DBSCAN】理论与实现
source link: https://www.guofei.site/2017/11/28/dbscan.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

【DBSCAN】理论与实现
2017年11月28日Author: Guofei
文章归类: 3-2-聚类 ,文章编号: 304
版权声明:本文作者是郭飞。转载随意,但需要标明原文链接,并通知本人
原文链接:https://www.guofei.site/2017/11/28/dbscan.html
模型介绍
密度聚类 是一种聚类模型,其思想是,只要样本点的密度大于某个阈值,则将该样本添加到最近的簇中。
- 可以处理形状和大小的簇
- 对噪音不敏感
- 计算复杂度大
- 如果簇的密度变化太大时,会有麻烦
- 对于高维问题,密度定义是个比较麻烦的问题
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
DBSCAN
核心点(core point) : 半径Eps内含有超过MinPts数目的点
边界点(border point) 半径Eps内的点的数量少于MinPts,但是 核心点 的邻居 噪音点 不是核心点或边界点的点 直接密度可达 p在q的Eps-邻域内,q是核心点,叫做q→pq→p直接密度可达 密度可达 p1p2…pnp1p2…pn,度过pi→pi+1pi→pi+1直接密度可达,那么叫做p1→pnp1→pn密度可达 密度相连 如果对于p,qp,q, 存在oo, 使得o→p,o→qo→p,o→q密度可达,那么叫做p,qp,q密度相连
Python实现
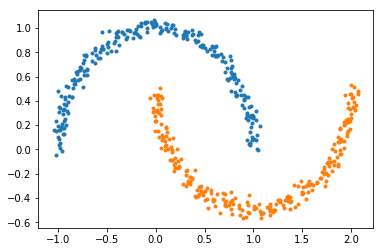
import sklearn.datasets
data,target=sklearn.datasets.make_moons(n_samples=500,noise=0.04,shuffle=True)
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.3, min_samples=6)
dbscan.fit(data)
DBSCAN(algorithm=’auto’, eps=0.3, leaf_size=30, metric=’euclidean’, metric_params=None, min_samples=6, n_jobs=1, p=None)
dbscan.labels_ # 有lable=-1的情况,这是噪音点import matplotlib.pyplot as plt
label=dbscan.labels_
for i in [0,1]:
plt.plot(data[label==i,0],data[label==i,1],'.')
plt.show()
参考资料
您的支持将鼓励我继续创作!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK