

贝叶斯参数估计
source link: https://www.guofei.site/2018/05/07/beyestry.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

贝叶斯参数估计
2018年05月07日Author: Guofei
文章归类: 趣文,文章编号:
版权声明:本文作者是郭飞。转载随意,但需要标明原文链接,并通知本人
原文链接:https://www.guofei.site/2018/05/07/beyestry.html
问题提出
假设一次实验结果只有两种,还没有去做实验收集数据,这时有理由相信每个事件发生的概率是一个均匀分布
(这个问题中,事件发生的概率本身是一个有待估计的随机变量)
先验分布是这样的:
⎧⎩⎨⎪⎪P(x=0)=θP(x=1)=1−θθ∼U(0,1){P(x=0)=θP(x=1)=1−θθ∼U(0,1)
(有理由相信,未得到实验数据之前,先验的参数服从均匀分布)
问题解决
根据贝叶斯公式
P(θ∣X)P(θ∣X)
=P(X∣θ)P(θ)∫+∞−∞P(X∣θ)P(θ)dθ=P(X∣θ)P(θ)∫−∞+∞P(X∣θ)P(θ)dθ
假设经过两次实验,结果是(1,1),那么
P(X∣θ)=(1−θ)2P(X∣θ)=(1−θ)2
P(θ)=1,∀θ∈(0,1)P(θ)=1,∀θ∈(0,1)
结果是P(θ∣X)=3(1−θ)2P(θ∣X)=3(1−θ)2
数值计算
def func_prob_theta(theta):
'''
p(\theta) 先验分布
'''
if 0 < theta < 1:
return 1
else:
return 0
def func_prob_X_given_theta(X, theta):
'''
$P(X\mid\theta)$
:param X: list,每次实验的结果,例如[1,0,0,1,1]
:param theta:
:return:
例如,X=[1,0,0,1,0,0]
func_prob_X_given_theta(X,0.5),代表均匀0-1分布下,X这个实验结果出现的概率
'''
prob_X_given_theta = func_prob_theta(theta)
for x in X:
prob_X_given_theta *= theta ** (1 - x) * (1 - theta) ** x
return prob_X_given_theta
# 假如某次实验结果是这样的:
X = [1, 1, 0, 0, 1, 1]
# 先计算分母,这是一个积分:
from scipy import integrate
func = lambda theta: func_prob_X_given_theta(X, theta)
S, _ = integrate.quad(func, 0, 1)
# 计算并画出Theta的概率密度分布图
import numpy as np
list_p_theta = []
Theta = np.arange(0, 1, 0.01)
for theta in Theta:
list_p_theta.append(func(theta) / S)
import matplotlib.pyplot as plt
plt.plot(Theta, list_p_theta)
plt.title(X)
plt.show()
上结果:(标题是此次实验结果)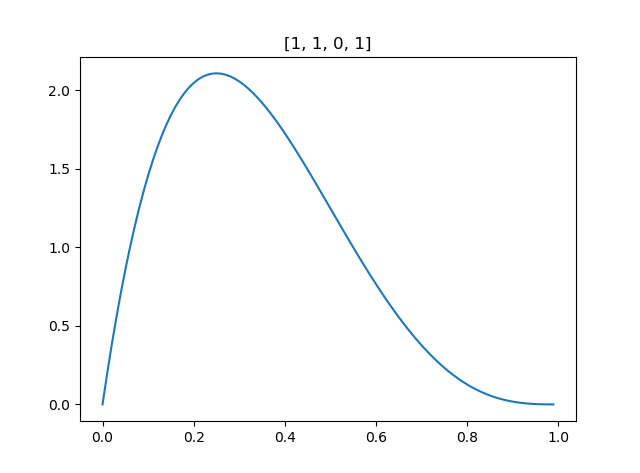
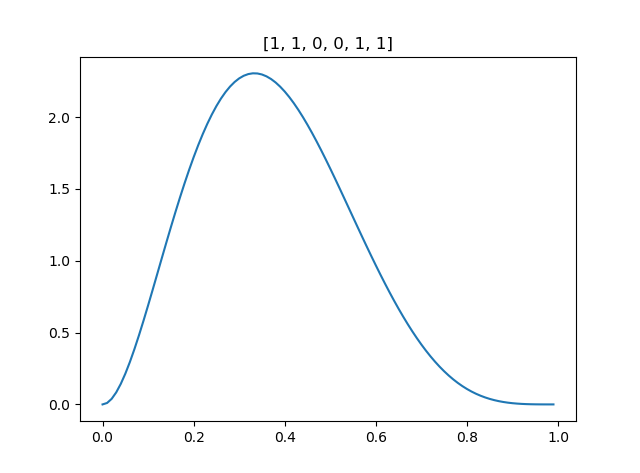
这是20个1和10个0的实验结果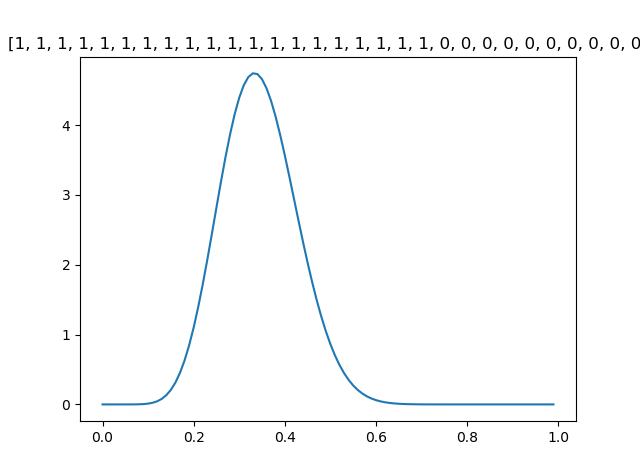
这是200个1和100个0的实验结果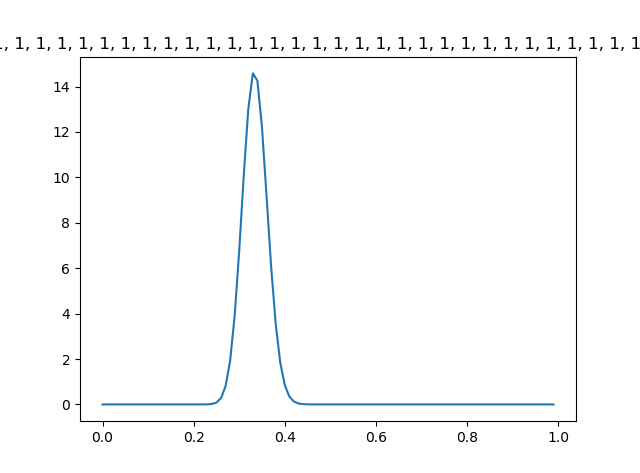
火车头问题
选自弗雷德里克·莫斯泰勒《五十个概率难题的解法》
铁路上火车头以1到N命名,你看到3个火车头,标号分别为30,60,90. 请估计铁路上有多少火车头
1. 假设先验为均匀分布
θ∼U(90,N)θ∼U(90,N)
X:看到标号 30,60,90
所以,P(X∣θ)=⎧⎩⎨1θ30θ≥90o/wP(X∣θ)={1θ3θ≥900o/w
P(θ)=1N−90P(θ)=1N−90
计算得到 P(θ∣X)=P(X∣θ)P(θ)∫+∞−∞P(X∣θ)P(θ)=1/θ31/(2⋅902)−1/(2N2)P(θ∣X)=P(X∣θ)P(θ)∫−∞+∞P(X∣θ)P(θ)=1/θ31/(2⋅902)−1/(2N2)
我们想知道平均可能有多少个火车头,也就是 E(θ∣X)E(θ∣X)
用期望的计算公式E(θ∣X)=∫θP(θ∣X)dθ=1/N−1/901/(2⋅902)−1/(2N2)E(θ∣X)=∫θP(θ∣X)dθ=1/N−1/901/(2⋅902)−1/(2N2)
2. 假设为指数分布
我们相信,企业的规模服从幂律分布,也就是说,概率密度函数是f(θ)=1/xαf(θ)=1/xα
进一步,我们近似假设f(θ)={λ⋅1/θ090≤θ≤Nf(θ)={λ⋅1/θ90≤θ≤N0,其中 λλ是使得全事件概率为1的因子。这个近似假设在实际中是合理的,因为总有一个规模的上限。
用代码模拟计算E(θ∣X)E(θ∣X),其中贝叶斯公式P(θ∣X)=P(X∣θ)P(θ)∫+∞−∞P(X∣θ)P(θ)P(θ∣X)=P(X∣θ)P(θ)∫−∞+∞P(X∣θ)P(θ)
N=500 # 试试增加N,结果收敛
def func_prior_prob(theta):
return 1/theta if 90<=theta<=N else 0
def func_X_given_theta(theta):
return 1/theta**3
prob_X=sum([func_X_given_theta(i)*func_prior_prob(i) for i in range(90,N+1)])
sum([func_X_given_theta(i)*func_prior_prob(i)*i/prob_X for i in range(90,N+1)])
(二战期间,英美统计了德国坦克编码规则和缴获坦克的编码,使用类似方法,计算得到了有巨大价值的情报)
您的支持将鼓励我继续创作!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK