

ETL工程师必看!超实用的任务优化与断点执行方案
source link: https://my.oschina.net/u/944575/blog/5069416
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

前言
随着大数据时代的快速发展,企业每天需要存储、计算、分析数以万亿的数据,同时还要确保分析的数据具备及时性、准确性和完整性。面对如此庞大的数据体系,ETL工程师(数据分析师)如何能高效、准确地进行计算并供业务方使用,就成了一个难题。
作为一家数据智能公司,个推在大数据计算领域沉淀了丰富的经验。本篇文章将对大数据离线计算过程中出现的任务缓慢和任务中断这两大痛点问题提出解决思路,期望读者能够有所收获。
任务缓慢
“任务执行缓慢”通常是指任务的执行时间超过10个小时,且不能满足数据使用方对数据及时性的要求。比如业务方需早上就能够查看T-1的数据,但是因为任务延时,业务方只能等到下午或者傍晚才能查询、浏览T-1的数据,从而无法及时发现经营问题、进行高效决策。因此,对缓慢任务进行优化成了ETL工程师必不可少的一项工作。
在长期的大数据实践中,我们发现,缓慢任务往往具有一定的共性。只要我们能找到问题所在,并对症下药,就能将任务执行时间大大缩短。个推将任务执行缓慢的常见问题归纳为以下四点:逻辑冗余,数据倾斜、大表复用,慢执行器。接下来会对每个痛点进行详细阐述。
1.逻辑冗余
“逻辑冗余”往往是因为ETL工程师进行数据处理和计算时更关注处理结果是否满足预期,而未深入考虑是否存在更高效的处理方式,导致原本可通过简单逻辑进行处理的任务,在实际中却使用了复杂逻辑来执行。
减少“逻辑冗余”更多地依赖开发者经验的积累和逻辑思维以及代码能力的提升。这里分享一些高级函数,希望能够帮助开发者进一步提升数据处理效率。
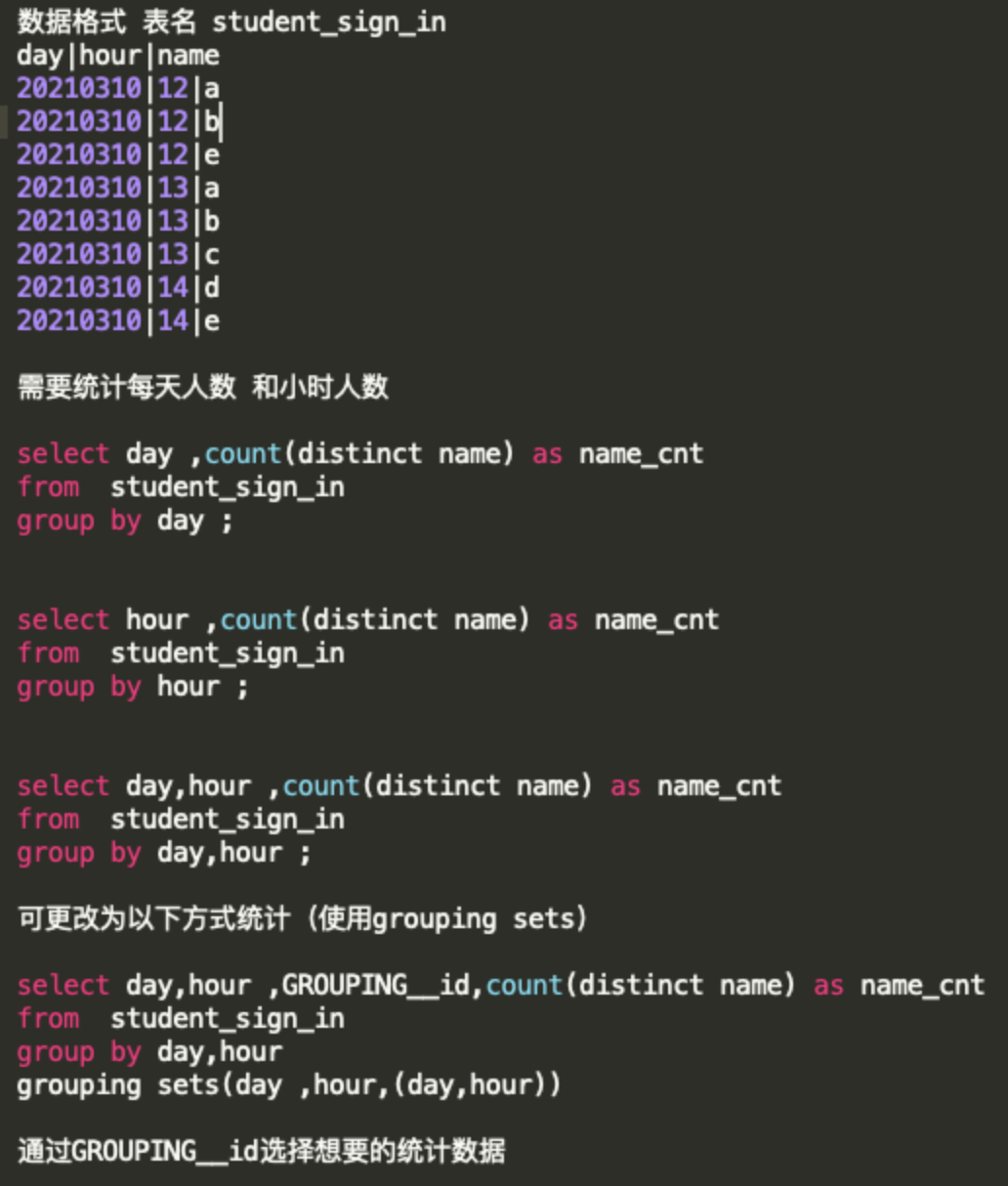
Grouping sets
分组统计函数。这个函数可以实现在一段SQL中输出不同维度的统计数据,避免出现执行多段SQL的情况,具体写法如下:
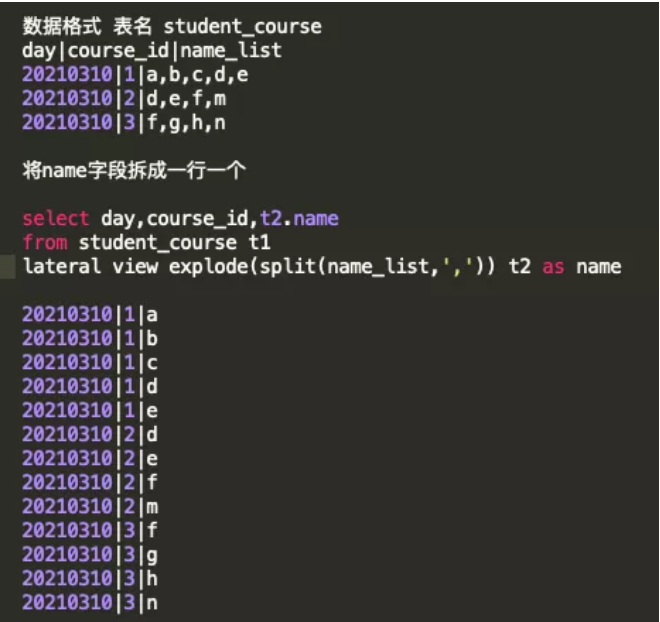
Lateral view explode()
一行转多行函数。这个函数只能处理array格式数据,需要配合split()函数使用,具体写法如下:
还有其他一些函数、函数名及功能如下,具体用法需要读者自行查询(可登录hive官网查询函数大全):
-
find_in_set() :查找特定字符串在指定字符串中的位置
-
get_json_object():从json串中抽取指定数据
-
regexp_extract():抽取符合正则表达的指定字符
-
regexp_replace() :替换符合正则替换指定字符
-
reverse():字符串反转
数据倾斜
“数据倾斜”是指在MR计算的过程中某些Map job需要处理的数据量太大、耗时太长,从而导致整个进程长时间无法结束,任务处理进度长时间卡在99%的现象。
针对数据倾斜的情况,开发者们可通过代码层面进行修改,具体操作如下:
-
使用group by方式替换count(distinct id ) 方式进行去重统计
-
进行大小表关联时使用mapjoin操作或子查询操作,来替换 join操作
-
group by出现倾斜需要将分组字段值随机切分成随机值+原始值
-
join操作避免出现笛卡尔积,即关联字段不要出现大量重复
大表复用
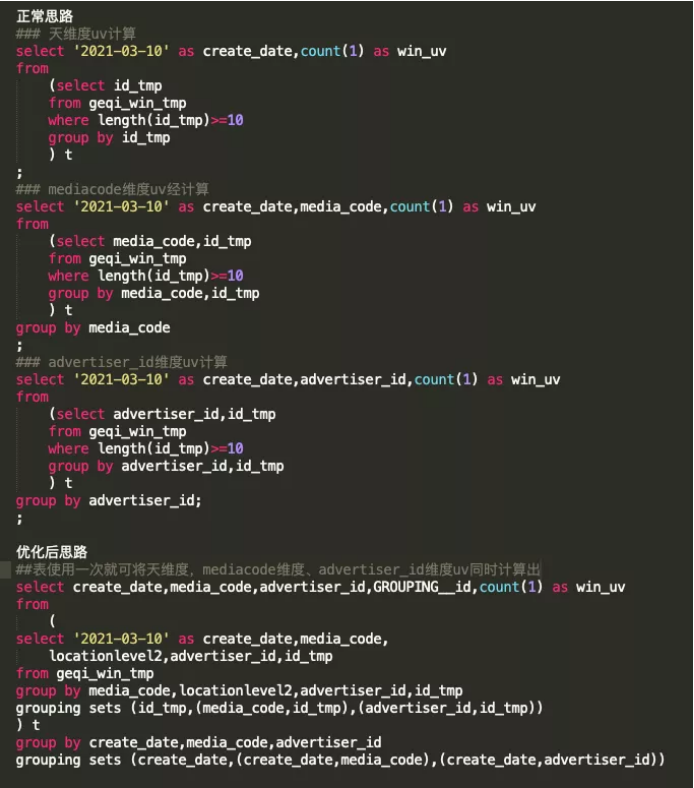
“大表复用”,是指对上亿甚至几十亿的大表数据进行重复遍历之后得到类似的结果。避免大表复用就要求ETL工程师进行系统化的思考,能够通过低频的遍历将几十亿的大表数据瘦身到可重复使用的中间小表,且同时支持后续的计算。
因此,工程师需要在工程开发之初就将整体的工程结构考虑进去,并且坚持“大表仅使用一次”的原则,以提升整个工程的执行效率。
这里介绍一个实战中的例子,供读者参考:
慢执行器
“慢执行器”是指数据体量过于庞大时,Hive的底层计算逻辑已经无法快速遍历单一分区中的所有数据。
由于在同等资源的情况下,Spark进行数据遍历的效率远高于MapReduce;且Spark任务对资源的抢占程度远大于MapReduce任务,可在短时间内占用大量资源高效完成任务,之后快速释放资源,以提高整个集群任务的执行效率。
因此,针对该情况,开发者可考虑使用pyspark等更为高效的计算引擎进行数据的快速遍历。同时,开发者也需要有意识地加强思维训练,养成良好的开发习惯,在面对海量数据时探索更快、更准、更体系化的计算和处理方式。
任务中断
因为各种各样的原因,线上任务经常会出现被kill掉然后重新执行的情况。任务重新执行会严重浪费集群资源,同时使得数据计算结果延迟从而影响到业务方的数据应用。如何避免这种现象的发生呢?个推是这样解决该问题的。
个推的定时任务是基于Azkaban调度系统开发的,个推的数据分析师主要使用shell、HSQL、MySQL、Pypark四种代码进行数据处理,将原始日志清洗、计算,然后生成公共层、报表层数据,最终供业务方使用。
因此个推需要设定四种代码执行器以支持脚本中对不同类型代码的处理。这里主要对其中的三个核心内容进行介绍:代码块输入、执行函数以及循环器。
代码块输入
一般情况下,脚本中的shell、HSQL、MySQL、pypark代码会按照顺序直接执行,不能选择性执行。在实践中,我们将代码块以字符串的方式赋值给shell中的变量,并在字符串的开头标记是何种类型的代码,代码执行到具体步骤时只有赋值操作,不会解析执行,具体如下:
✦ 执行HSQL代码块
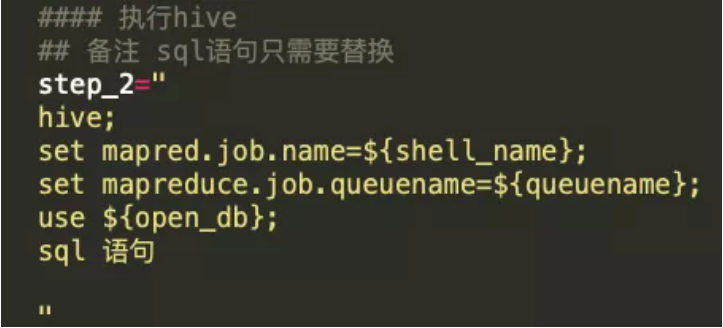
✦ 执行shell代码块
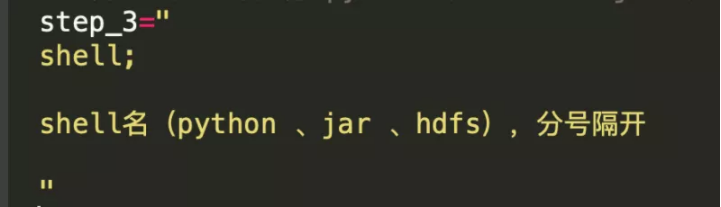
✦ 执行mysql代码块

✦ 执行pyspark代码块
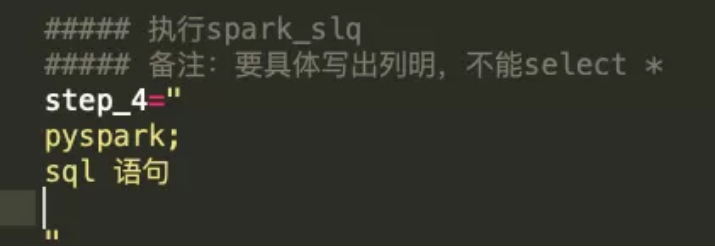
如此,就实现了将不同的代码放入对应的step_n中。在后续的执行器中这些代码能够直接执行,开发者只需要关心逻辑处理即可。
执行函数
执行函数是对shell中变量step_n当中的字符串进行代码解析并执行。不同类型的代码块解析方式不同,因此需要定义不同的执行函数。函数一般单独放在整个工程的配置文件中,通过source的方式调用,具体函数定义如下:
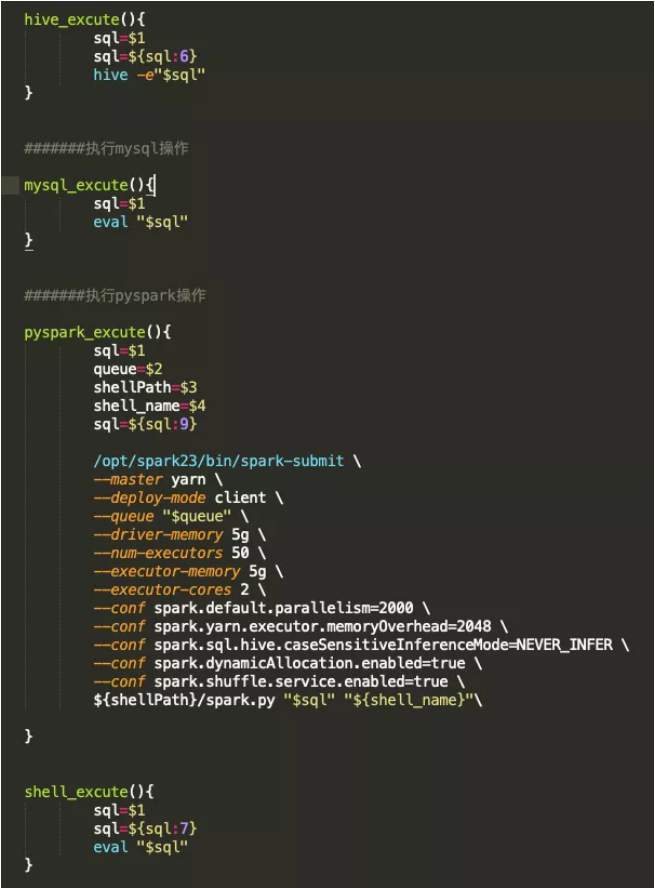
Hive、MySQL以及shell的执行函数比较简单,通过hive-e 或者eval的方式就可以直接执行。pyspark需要配置相应的队列、路径、参数等,还需要在工程中增spark.py文件才能执行,此处不做赘述。
循环器
循环器是断点执行功能的核心内容,是步骤的控制器。循环器通过判断shell变量名确定需要执行哪一步,通过判断变量中字符串内容确定使用何种函数解析代码并执行。
下图是参考案例,代码如下:
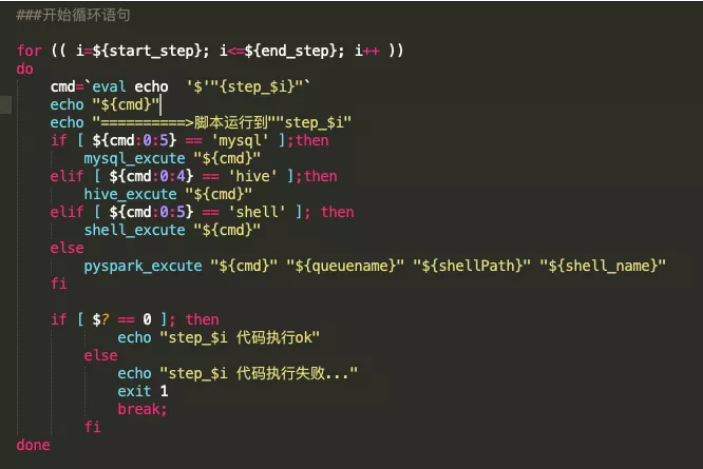
开发者需要在脚本的开始定义好整个代码的结束步骤,以确保循环器正常运行;同时,可将开始步骤当作脚本参数传入,这样就很好地实现了任务的断点执行功能。
总结
ETL工程中的任务缓慢和任务中断问题是每个大数据工程师都需要面对和解决的。本文基于个推大数据实践,针对任务缓慢和任务中断问题提出了相应解决思路和方案,希望能够帮助读者在任务优化以及ETL工程开发方面扩宽思路,提高任务执行效率,同时降低任务维护的人力成本和机器成本。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK