

现在后端都在用什么数据库存储数据?
source link: https://www.cnblogs.com/readbyte/p/14781043.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

现在后端都在用什么数据库存储数据?
那我就根据这两三年的研究与工作经历,说说如今的情况。
1.Oracle:传统行业,尤其是政府,医疗,学校和大企业,基本上还是Oracle应用最广,其次就是DB2。反而是WebLogic和WebSphere这些中间件基本上随着经典javaee的没落,已经逐步退出历史舞台,被富前端和微服务框架的轻量级组合所替代。
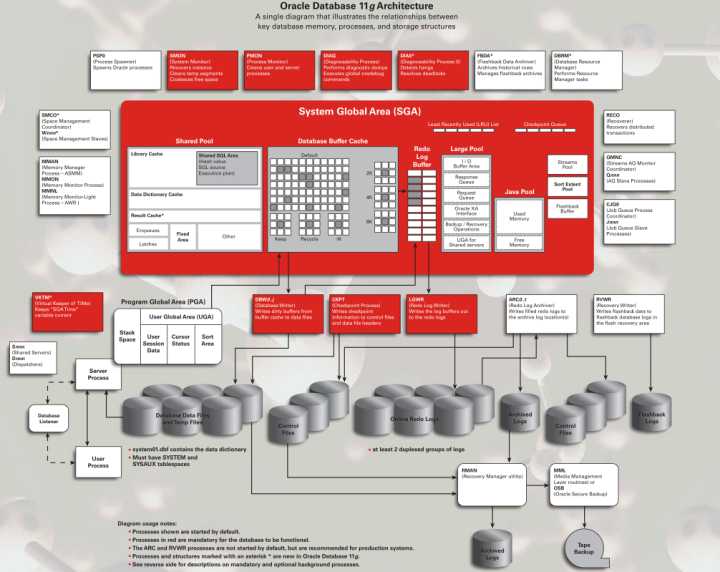
2.MySQL:传统行业的很多新项目也大量开始应用MySQL,因为轻量级数据库的前期成本很低,可以保证项目预算够用,所以主要是新项目居多,面向互联网连接的项目也居多。这些系统一般不会像Oracle一样承担关键性业务的数据存储,所以选择什么样的数据库都是开发公司自己的选择决定。
目前有大量企业都开始上云,大家买云服务以阿里云ecs为主,总体上阿里云还是比较稳定,那么对于云上数据库的稳定有要求的企业一般都会选择阿里云主打的的rds系列,MySQL居多,PostgreSQL也开始逐渐被认可。
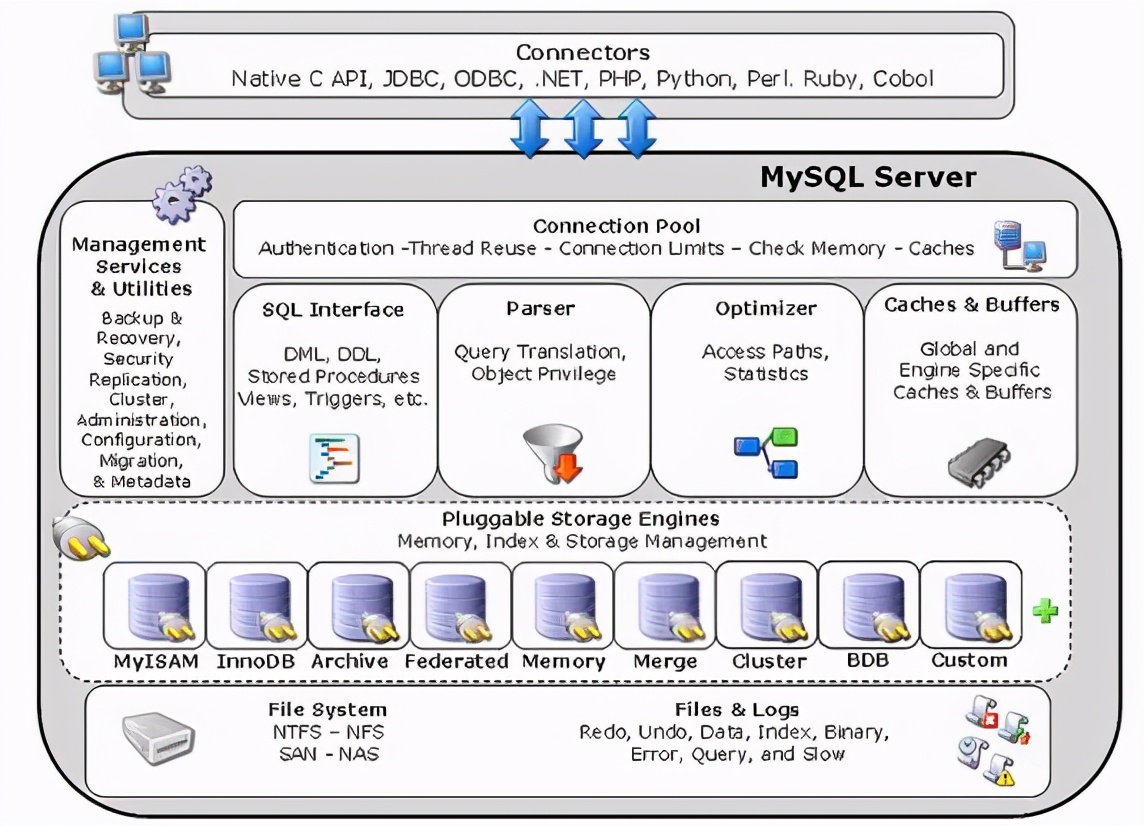
3.PostgreSQL:说到PostgreSQL,的确这两年PG风头正劲,以前我的文章也提到过我做过的互联网医疗产品,其架构设计就选择采用了PostgreSQL,主要就是看中PostgreSQL在生产上的稳定性极高,而且成本很低。尤其是精通Linux服务的架构师,对于PostgreSQL更容易掌握。
更具体地说就是使用PostgreSQL的关键因素主要还是业务数据很关键,因为我们当时承载的是互联网医疗数据,医疗数据自身属性就很关键!所以稳定和安全都是刚性要求,同时要平衡成本与互联网方式的灵活性,所以才否定了MySQL方案,坚决执行了PostgreSQL方案。
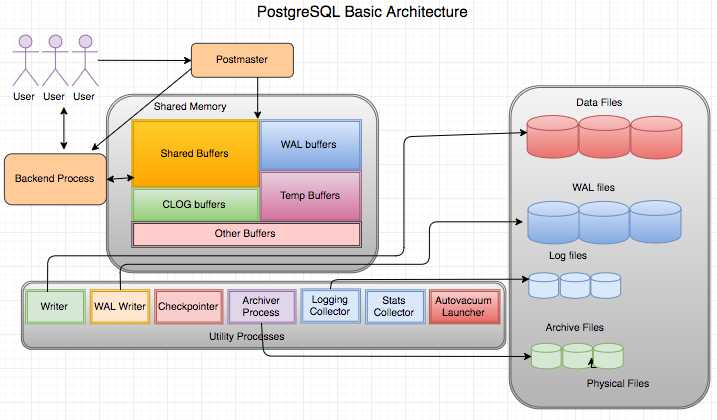
4.Hadoop HDFS:大数据类项目的主数据集还是以Hadoop HDFS作为基础存储设施。尽管现在很热的讨论就是Hadoop已经是日落黄昏,可以选择其他更快的NoSQL存储方案。实际上,大数据工程师在最终落地的执行上,还是很诚实的选择了Hadoop,因为其成熟度,稳定性是最终考量的标准。
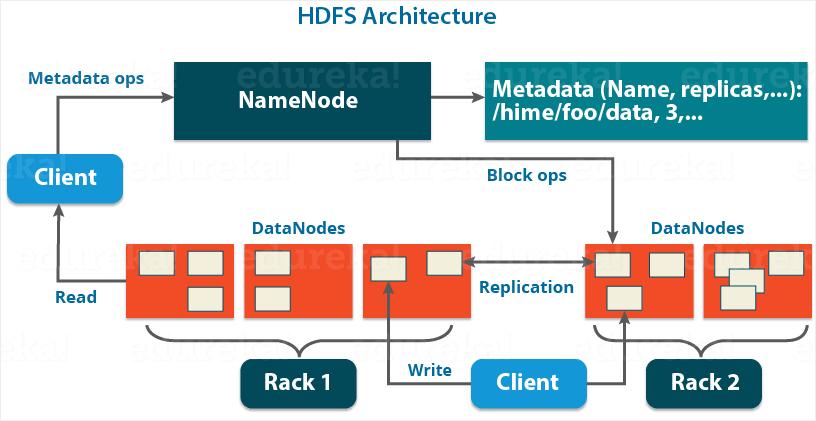
5.Elasticsearch:ELK家族的Elasticsearch目前被大量作为日志监测分析的主数据集去使用,甚至都忽视了它本身是搜索引擎的这个事实,在电子商务网站,内容发布网站以及社交媒体网站,Elasticsearch作为专业搜索引擎,还是稳坐第一把交椅。
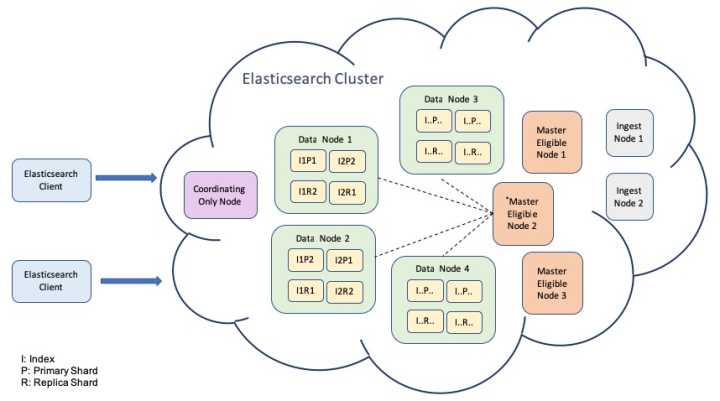
6.实时/时序数据库:工业能源以及其他物联网行业,实时、时序数据库正在逐步采用开源的解决方案,例如Druid.io、InfluxDB,OpenTSDB,还是目前存储物联网数据最好的开源选择方案。Druid.io是实时与历史一整套实时库解决方案;InfluxDB目前热度非常高的时序数据库,自己独立实现了一套原生的集群存储结构;OpenTSDB主要依赖HBase分布式数据库与HDFS分布式文件系统。另外提一句,清华推出的开源时序数据库IOTDB,目前已经升级成Apache.org的顶级项目。
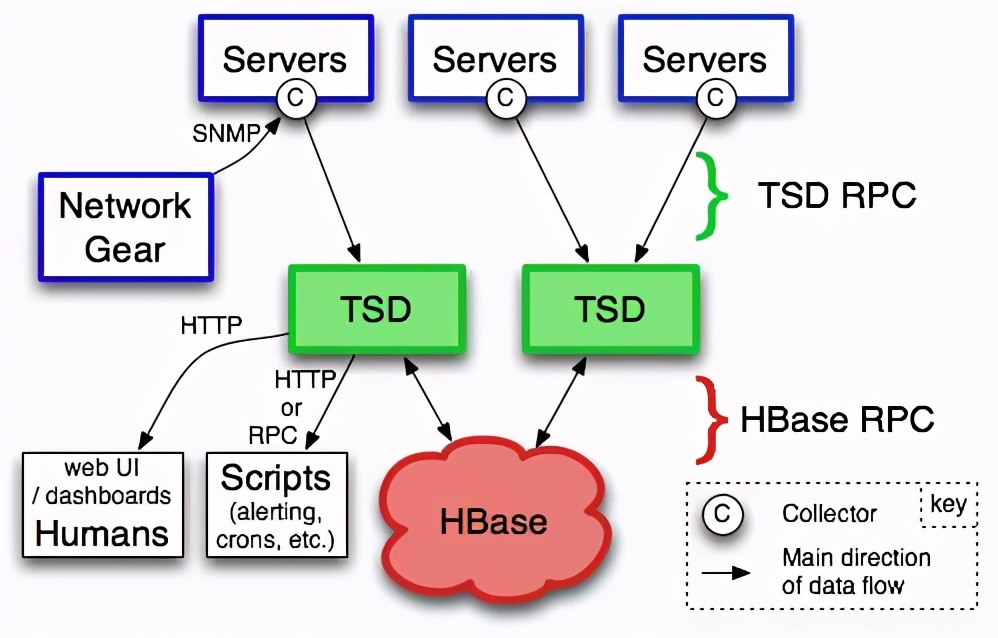
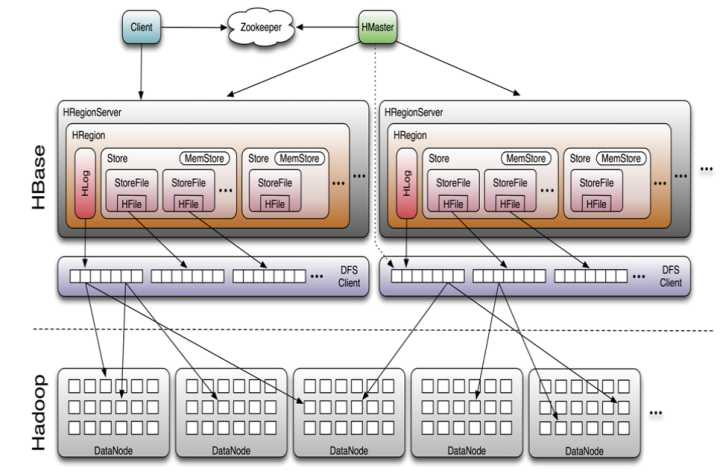
7. Hadoop HBase:Hadoop hbase作为列簇存储,也是毫秒级的k-v存储,越来越适应通用场景下的实时数据分析了,可能哪个领域都有能用到它,支撑实时处理的联机分析以及小型批处理业务。它的分布式一致性,存储hdfs的稳定性,都是关键性业务数据进行实时分析的极佳方案。
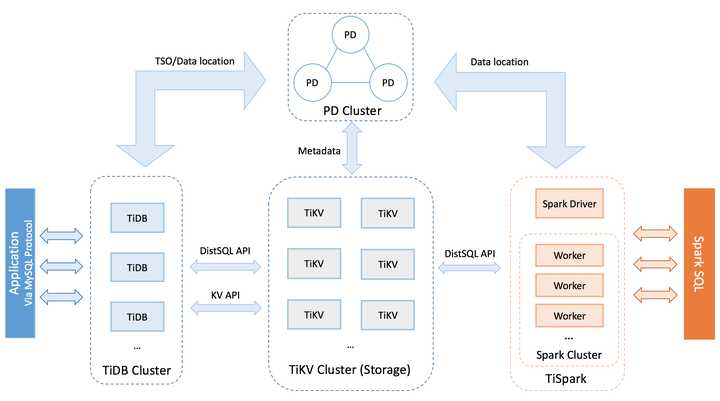
8.TiDB:在互联网海量数据查询,保证事务一致性以及大吞吐写入并行的时代,就会形成两种模式,一种是NewSQL对关系型数据库的替代方案,以前我的文章也不断提到TiDB对关系数据库替代的必要性,这种替换行为一般会出现在基于关系数据库的上层复杂业务不断升级更新带来的问题,导致运维过程中相关人员生无可恋的情况。那么NewSQL这种分布式一致性,满足ACID,又带有k-v水平伸缩存储的方案就极为合适,不用在关系数据库的分库分表的泥潭中挣扎。
9.MongoDB:另一种是关系数据库自身的改进或者引入MongoDB进行部分替代,例如电子商务的订单业务数据,互联网医疗的健康档案数据,内容发布的文章数据,都能实现MongoDB的文档化替代,这不仅更符合业务的文档化模型,而且能保证事务的前提下,实现海量数据的支撑。

10.关系数据库并行能力:关系数据库也是在不断改进中前进,尤其是轻量级数据库的改进,MySQL8的cluster特性,PostgreSQL11的并行特性,都是不同手段想要达到同一个目的:那就是关系库都在想尽一切办法,不必让用户脱离关系型数据库,非得拥抱NoSQL才能追求到海量数据的并行处理能力,同时也能降低用户替换导致的巨大升级成本。
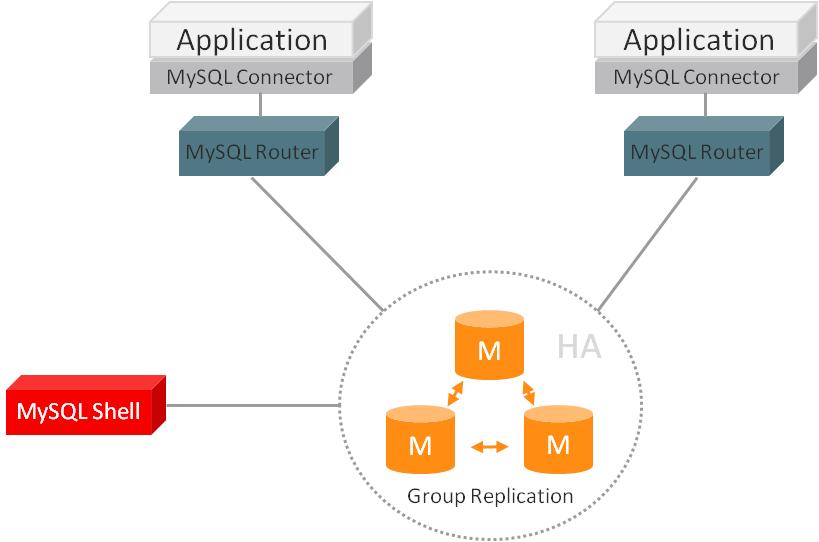
备注:以上架构图均来自数据库官方网站或相关技术的权威网站。
可以阅读另一篇关于分布式和大数据技术的详细文章:

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK