

小程序云开发实战:从零搭建科技爱好者周刊小程序
source link: http://xuedingmiao.com/blog/science_lover.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

# 前言
作为一名程序猿经常会逛 github ,也会关注一些科技类资讯,自然就发现了阮一峰老师的科技爱好者周刊,每到周五经常会打开这个开源杂志看看有没有新奇好玩的东西。这个周刊是个开源杂志,目前可以从多个地方查看,除了 github 之外还有阮一峰老师的博客、云加专栏、语雀等地方,但是感觉不如小程序这个形态来的方便快捷,然后发现语雀有小程序但是打开路径还是略长,需要登录后点击【我】再进入【我的收藏】,再从列表中选择收藏的周刊进行查看(而且右上角胶囊菜单没有分享功能)......。所以就想到利用小程序的云开发能力来实现这么一个开源杂志的小程序版。
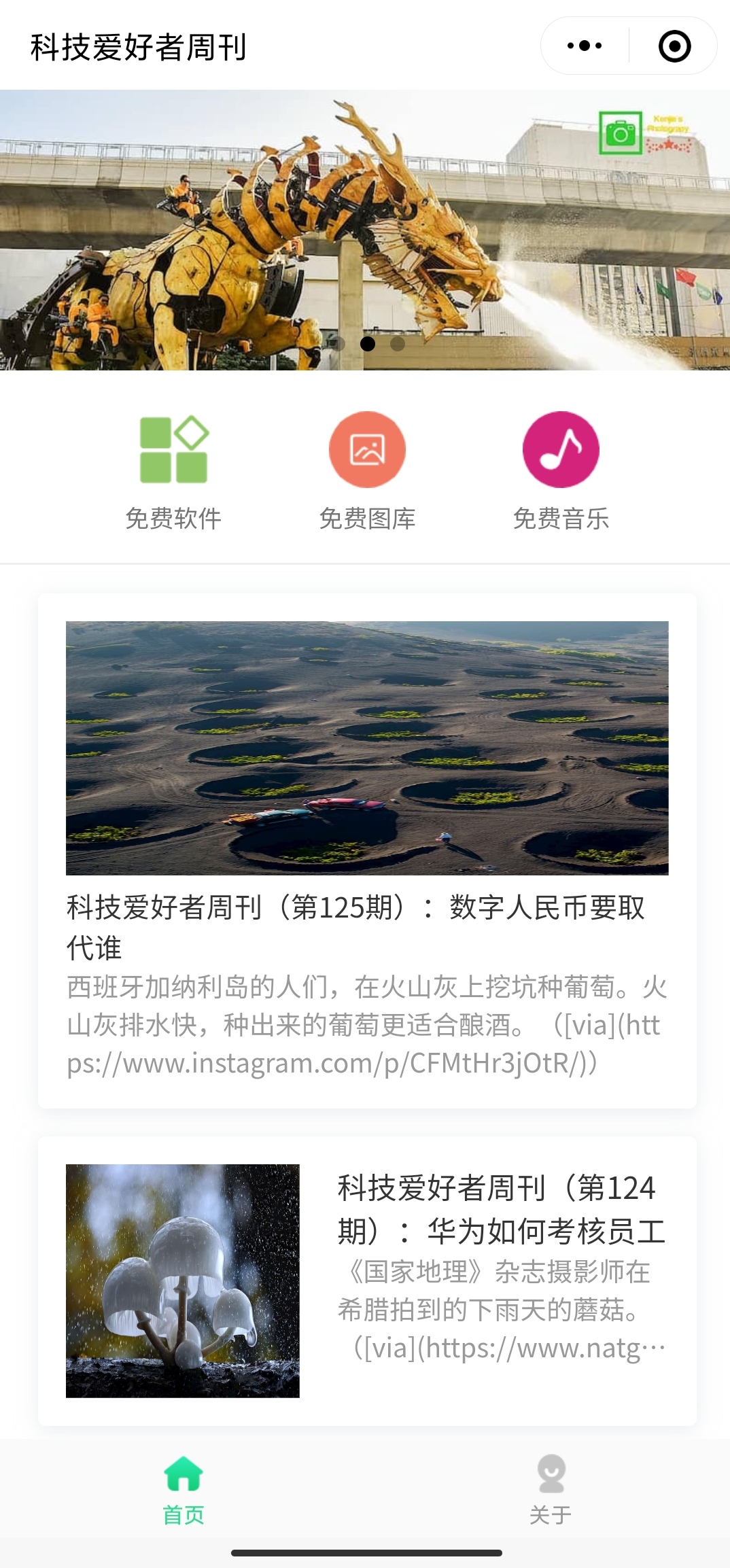
# 界面效果
小程序首页及详情页

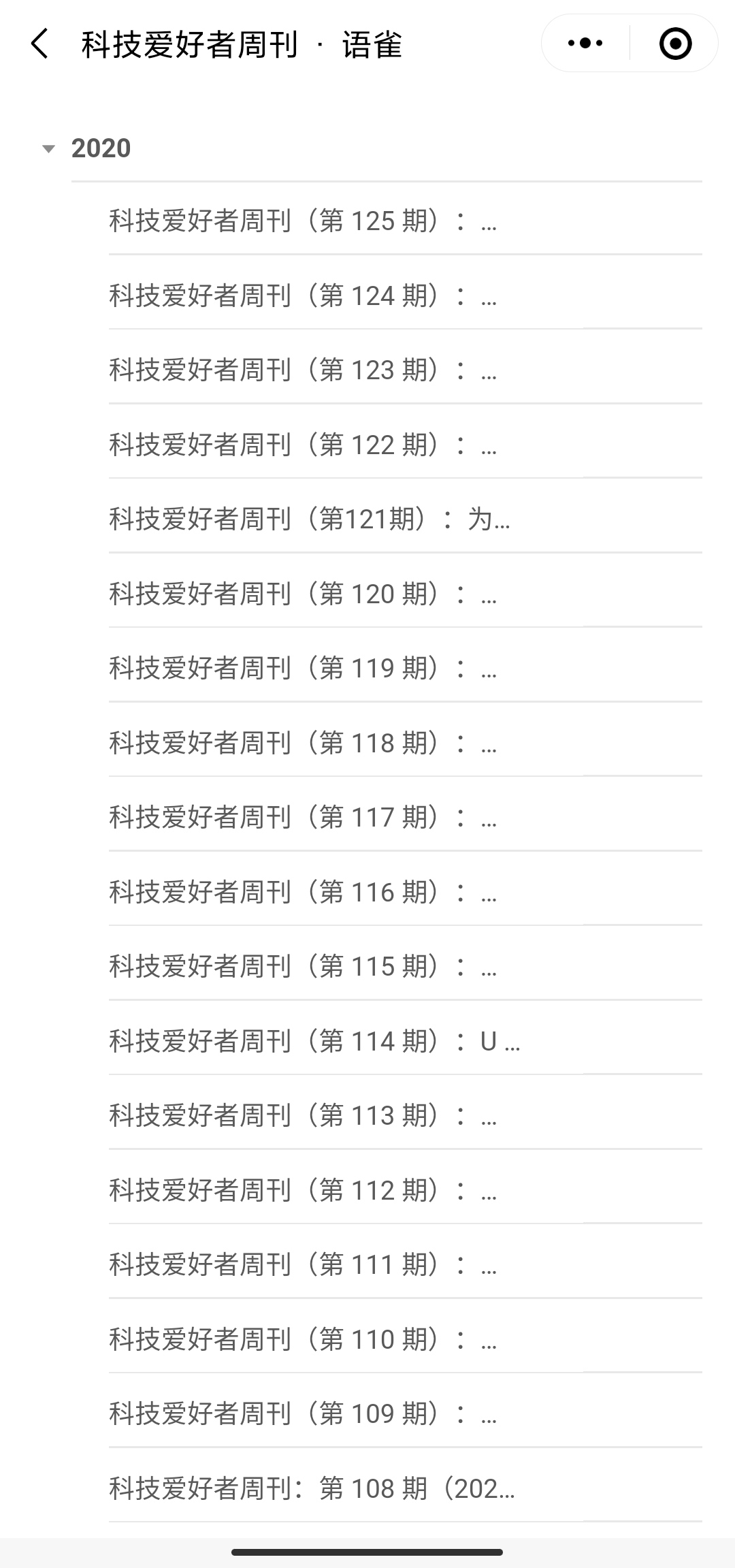
# 与语雀的界面对比
语雀小程序中周刊的列表页及详情页
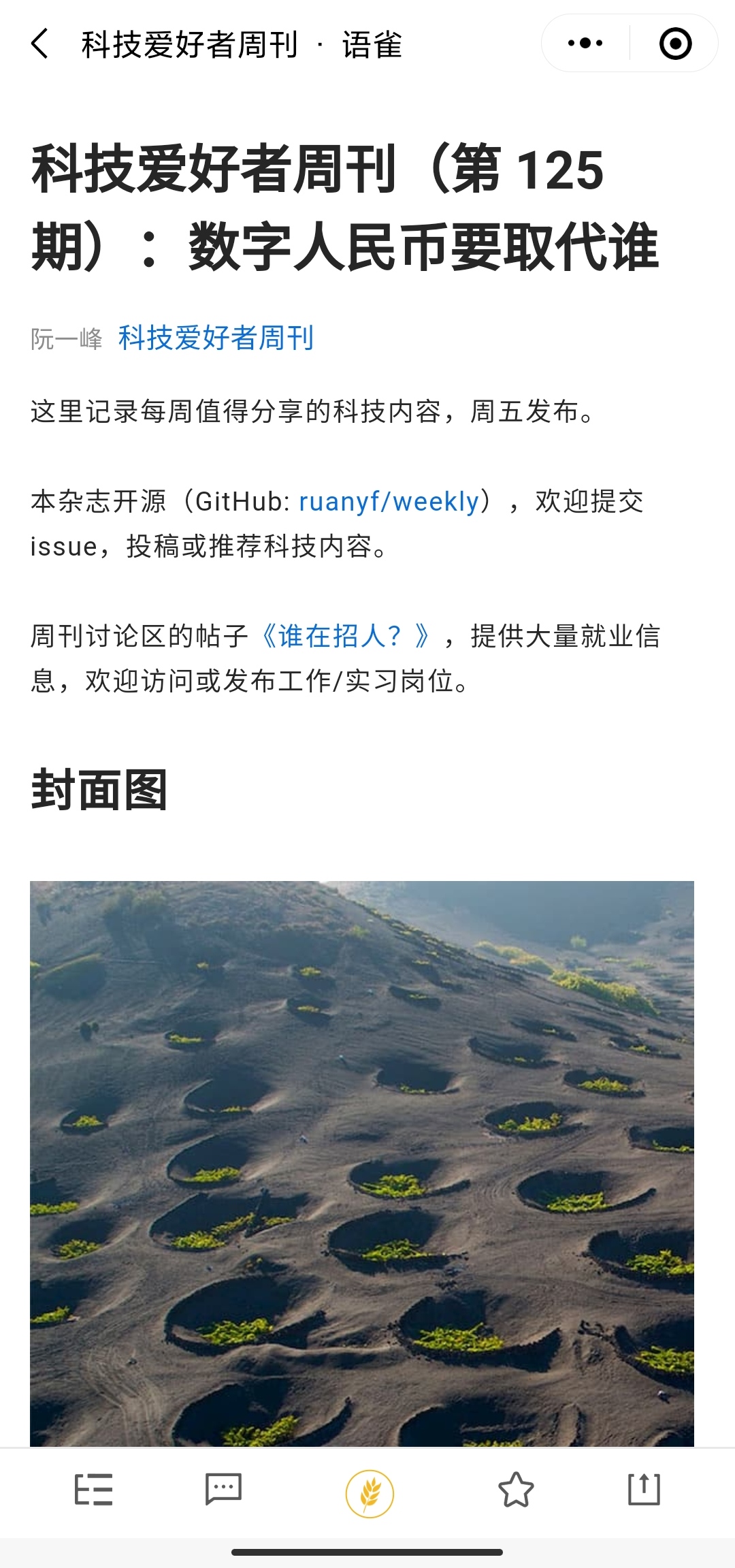
- 以下是使用方式上的一些差异,仅供参考
# 技术选型
# 小程序端
- 主框架使用 mpvue
- UI框架采用 Lin-ui
- 渲染插件使用 wemark
# 服务端
- 小程序云开发部署若干云函数
- weeklies:获取周刊列表
- weekly:获取周刊 markdown 数据
- 服务器部署基于 koa 框架开发的接口
# 架构方案
主体采用服务器加云开发混合部署,如下图所示:
- 服务器定期从 github 拉取最新文章的 markdown 文件,并进行基础的数据处理,生成文章的 json 缓存文件
- 小程序内调用云函数后从独立服务器获取文章数据进行展示
- 文章内页的数据为markdown类型故采用开源插件 wemark 进行渲染
# 重点问题
1.文章内容渲染的问题。小程序内的 markdown 渲染插件有几种解决方案,最终选择了 wemark 来渲染(当然也可以选其它的) markdown 文件
<wemark :md="content" link highlight type="wemark"></wemark>
2.每期周刊并没有在文件中标注说明创建时间,但是文件是从 github 同步过来的,所以可以通过执行 git log 命令来获取日志从而大致确定文章的更新时间
核心实现示例如下:
// 需要借助 child_process 及 moment 模块
...
var data = fs.readFileSync(row, 'utf-8') // row 为markdown文件本地路径
// 最后更新时间
let dateGit = execSync(
'cd ' + config.base_path + ' && git log -n 1 -s --format=%cd ' + row
).toString() // config.base_path 为本地周刊仓库地址
let lastdate = moment(new Date(dateGit)).format('YYYY-MM-DD')
3.接口数据格式。前期的文章格式并不居有明显的规律性,在文章配图及概要获取上存在一定问题,为了使首页的最终显示效果更加美观,最终确定取封面图及其描述作为每期的介绍。
最终确定的周刊列表 json 格式示例:
{
"code": 0,
"data": [{
"title": "科技爱好者周刊(第125期):数字人民币要取代谁",
"seq": "125",
"desc": "西班牙加纳利岛的人们,在火山灰上挖坑种葡萄。火山灰排水快,种出来的葡萄更适合酿酒。([via](https://www.instagram.com/p/CFMtHr3jOtR/))",
"lastdate": "2020-09-18",
"file_name": "issue-125.md",
"img": "https://www.wangbase.com/blogimg/asset/202009/bg2020091705.jpg"
}]
}
4.markdown 数据的处理,需要匹配 markdown 文件内部引用的图片
markdown 文件内部引用图片不一定完全契合标题,但是一篇文章没有配图也太丑了,所以这里权衡之后决定使用第一张图及其描述作为周刊文章封面及概要
获取图片的方式为正则匹配 markdown 文件内容中的所有图片,然后获取第一张图,并把图片之后的固定 90 个字符作为该期周刊的描述文字
// 获取第一张图
let imgReg = /!\[.*\]((.+))/ //匹配img
let cnt = data
let imgArr = cnt.match(imgReg) //筛选出所有的img
// 图后的内容截取作为描述
let desc = cnt.substr(cnt.indexOf(imgArr[0]) + imgArr[0].length + 2, 90)
let imgUrl = ''
if (imgArr && imgArr.length > 0) {
let url = imgArr[0]
imgUrl = url.substring(url.indexOf('(') + 1, url.indexOf(')'))
}
5.数据同步问题。目前基于koa写了一个 webhook 部署在独立服务器上,每周定期拉取最新周刊的 markdown 文件并生成缓存。
示例代码:
router.get('/weeklies/init', async (ctx, next) => {
// 拉取最新markdown文件
const { stdout, stderr } = await exec(
'cd ' + config.base_path + ' && cd ../ && git pull'
)
if (stderr == '') {
// 读取md文件列表
let blog_routes = await fg(blog_md_path, {
onlyFiles: true,
cwd: __dirname,
deep: 1,
})
ctx.data = '仓库更新成功->' + stdout + (await initTitle(blog_routes))
} else {
ctx.data = stderr
}
await next()
})
# 项目总结
项目整体上比较简单,极简风格,发现了有意思的东西可以方便地分享给朋友或者到朋友圈。目前 markdown 文件内容并没有使用云数据库,而是直接读取的文件,可能会对服务器 IO 有一定考验,后期会采取迁移到云数据库的方式。
# 体验方法
小程序目前已上线,欢迎扫码体验
或者也可以微信搜索『科技爱好者周刊』

# 参考资料
# 致谢
再次致谢阮一峰老师 😄
Recommend
-
76
科技爱好者周刊:第 61 期
-
77
这里记录每周值得分享的科技内容,周五发布。 欢迎投稿,或推荐你自己的项目,请前往 GitHub 的 ruanyf/weekly 提交 issue。
-
34
科技爱好者周刊:第 62 期
-
49
科技爱好者周刊:第 63 期
-
48
科技爱好者周刊:第 64 期
-
70
这里记录每周值得分享的科技内容,周五发布。...
-
74
科技爱好者周刊:第 66 期
-
30
这里记录每周值得分享的科技内容,周五发布。 欢迎投稿,或推荐你自己的项目,请前往 GitHub 的 ruanyf/weekly 提交 issue。
-
103
科技爱好者周刊:第 67 期
-
3
这里记录每周值得分享的科技内容,周五发布。 本杂志开源,欢迎
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK