

Hadoop(十)spark环境搭建
source link: https://blog.csdn.net/mingyunxiaohai/article/details/80642907
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本篇使用 Spark 2.3.0
Apache Spark是一个快速且通用的集群计算系统。它提供Java,Scala,Python和R中的高级API以及支持通用执行图的优化引擎。它还支持一组丰富的更高级别的工具,包括 Spark SQL , MLlib, GraphX,Spark Streaming.。
Spark运行在Java 8+,Python 2.7 + / 3.4 +和R 3.1+上。对于Scala API,Spark 2.3.0使用Scala 2.11。
下载地址 http://spark.apache.org/downloads.html
下载完上传到Linux服务器上解压
配置环境变量,在 Yarn 上运行 Spark 需要配置 HADOOP_CONF_DIR、 YARN_CONF_DIR 和 HDFS_CONF_DIR 环境变量
vim /etc/profile
export SPARK_HOME=/home/chs/software/spark-2.3.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoopsource /etc/profile
运行一下spark自带的例子
Spark带有几个示例程序。Scala,Java,Python和R例子都在 examples/src/main目录中。
./bin/run-example SparkPi 10其内部调用了更通用的 spark-submit 脚本来启动应用程序
例子是启动10个任务来计算pi,最后可以看到
2018-06-10 16:27:12 INFO DAGScheduler:54 - ResultStage 0 (reduce at SparkPi.scala:38) finished in 4.646 s
2018-06-10 16:27:13 INFO DAGScheduler:54 - Job 0 finished: reduce at SparkPi.scala:38, took 10.371892 s
Pi is roughly 3.1405471405471403运行shell
./bin/spark-shell --master local[2]–master选项指定分布式群集的 主URL,或者local使用一个线程local[N]在本地运行,或者使用N个线程在本地运行
运行后可以看到
Spark context Web UI available at http://master:4041
Spark context available as 'sc' (master = local[*], app id = local-1528620165516).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_172)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Spark是使用Scala语言编写的,不过支持使用java,pyhon,scala等编写应用程序。这里使用Scala做下练习。
Spark的主要抽象是一个称为数据集的分布式项目集合。数据集可以通过Hadoop InputFormats(例如HDFS文件)或通过转换其他数据集来创建。下面从Spark源目录中的自述文件中创建一个新的数据集
从新起个命令台,把spark解压目录下面的README.md文件上传到hdfs上
[root@master spark-2.3.0-bin-hadoop2.7]# hadoop fs -mkdir /user/root/
[root@master spark-2.3.0-bin-hadoop2.7]# hadoop fs -put README.md /user/root/创建一个数据集
scala> val textFile = spark.read.textFile("README.md")
2018-06-10 17:08:08 WARN ObjectStore:6666 - Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
2018-06-10 17:08:08 WARN ObjectStore:568 - Failed to get database default, returning NoSuchObjectException
2018-06-10 17:08:09 WARN ObjectStore:568 - Failed to get database global_temp, returning NoSuchObjectException
textFile: org.apache.spark.sql.Dataset[String] = [value: string]
textFile 就是我们创建的数据集,我们可以对它操作,比如查看行数,查看第一行
scala> textFile.count()
res2: Long = 103
scala> textFile.first()
res3: String = # Apache Spark
scala>
下面将这个数据集转换成一个新的数据集。我们调用filter返回一个新的数据集,过滤出来含有“Spark”的行
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark: org.apache.spark.sql.Dataset[String] = [value: string]查看一下行数
scala> linesWithSpark.count()
res4: Long = 20
找到一行最多有多少个单词
scala> textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)
res5: Int = 22
Spark还支持将数据集拉入集群范围的内存中缓存。
scala> linesWithSpark.cache()
res6: linesWithSpark.type = [value: string]
scala> linesWithSpark.count()
res7: Long = 20
scala> linesWithSpark.count()
res8: Long = 20
上面的例子中,我们设置了缓存,运行linesWithSpark.count()的时候,可以明显的看到第二次比第一次快很多。
Spark分布式集群环境搭建
上面是在一台机器上运行的 现在搭建spark集群
进入到spark解压目录下的conf文件夹下 配置slaves文件 ,将 slaves.template 拷贝到 slaves
cp slaves.template slavesslaves文件设置Worker节点。编辑slaves内容,把默认内容localhost替换成从节点
slave
slave2配置spark-env.sh文件,将 spark-env.sh.template 拷贝到 spark-env.sh
cp spark-env.sh.template spark-env.sh编辑spark-env.sh,添加如下内容:
export SPARK_DIST_CLASSPATH=$(/home/chs/hadoop-2.7.3/bin/hadoop classpath)
export HADOOP_CONF_DIR=/home/chs/hadoop-2.7.3/etc/hadoop
export SPARK_MASTER_IP=192.168.1.76SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
配置完成后将spark解压文件分别复制道从节点slave 和 slave2上
scp -r spark-2.3.0-bin-hadoop2.7 slave:/home/chs/sortware
scp -r spark-2.3.0-bin-hadoop2.7 slave2:/home/chs/sortware启动Hadoop集群,启动Spark集群前,要先启动Hadoop集群。
start-all.sh启动Master节点 , 在Master节点主机上运行如下命令
sbin/start-master.sh在Master节点上运行jps命令,可以看到多了个Master进程:
6374 ResourceManager
6184 SecondaryNameNode
8440 Jps
6826 Master
5963 NameNode
启动所有Slave节点 , 在Master节点主机上运行如下命令:
sbin/start-slaves.sh分别在slave、slave2节点上运行jps命令,可以看到多了个Worker进程
4202 DataNode
5450 Jps
4333 NodeManager
5374 Worker
这个地方运行sbin/start-slaves.sh的时候开始出了个错误 JAVA_HOME is not set
解决办法:
进入 sbin 目录 编辑 spark-config.sh文件
在里面加入 export JAVA_HOME=/home/chs/java/jdk1.8.0_172 在运行就好了
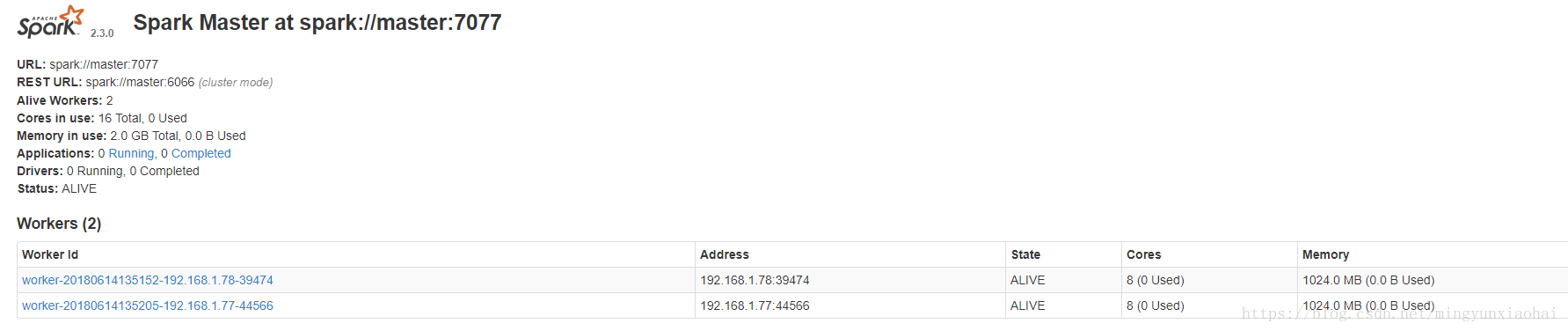
在浏览器上查看Spark独立集群管理器的集群信息
在master主机上打开浏览器,访问http://master:8080,如下图:
OK配置完毕!
sbin/stop-master.sh
sbin/stop-slaves.sh
stop-all.sh在集群上运行spark自带的demo
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster examples/jars/spark-examples_2.11-2.3.0.jarbin/spark-submit
–class org.apache.spark.examples.SparkPi //class后面是需要运行的程序主类 应用程序的入口
–master yarn-cluster //master 可以使用spark自带的管理器 这里使用yarn平台管理
examples/jars/spark-examples_2.11-2.3.0.jar //应用程序jar包
控制台我们可以看到下面的输出
2018-06-14 14:34:42 INFO Client:54 -
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1528958081043
final status: UNDEFINED
tracking URL: http://master:18088/proxy/application_1528950862529_0002/
user: root
把上面的tracking URL 复制到浏览器可以追踪任务的进度和日志

“`
OK完成。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK