

Padding IN predicates using Spring Data JPA Specification
source link: https://tech.asimio.net/2021/04/15/Padding-IN-predicates-using-Spring-Data-JPA-Specification.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
1. INTRODUCTION
I recently discussed how Spring Data JPA Specification and Criteria queries might impact Hibernate’s QueryPlanCache. A high number of entries in the QueryPlanCache, or a variable number of values in the IN predicates can cause frequent GC cycles where it releases fewer objects over time, and possibly throws OutOfMemoryError exceptions.
While padding the IN predicate parameters to optimize Hibernate’s QueryPlanCache we found setting in_clause_parameter_padding to true didn’t work when using Spring Data JPA Specification.
This blog post helps you to pad IN predicates when writing Spring Data JPA Specification and Criteria queries.
2. HIBERNATE CONFIGURATION
Let’s first add hibernate.query.in_clause_parameter_padding=true configuration property to the subject Spring Data JPA application:
spring:
jpa:
properties:
hibernate:
query:
in_clause_parameter_padding: true
3. STATEFUL SPRING DATA JPA SPECIFICATION
The idea behind a stateful JPA Specification is that instead of writing Spring Data JPA Specification and Criteria IN predicates using literal values as:
public static Specification<Film> categoryIn(Set<String> categories) {
if (CollectionUtils.isEmpty(categories)) {
return null;
}
return (root, query, builder) -> {
Join<Film, FilmCategory> filmCategoryJoin = root.join(Film_.filmCategories);
Join<FilmCategory, Category> categoryJoin = filmCategoryJoin.join(FilmCategory_.category);
return categoryJoin.get(Category_.name).in(categories);
};
}
You replace the literal values with named query parameters.
private Specification<Film> categoryIn(Set<String> categories) {
if (CollectionUtils.isEmpty(categories)) {
return null;
}
return (root, query, builder) -> {
Join<Film, FilmCategory> filmCategoryJoin = root.join(Film_.filmCategories);
Join<FilmCategory, Category> categoryJoin = filmCategoryJoin.join(FilmCategory_.category);
ParameterExpression<Set> queryParamCategories = this.createQueryParameter(
Set.class,
QUERY_PARAM_CATEGORIES, // Parameter name
categories, // Parameter values
builder
);
return categoryJoin.get(Category_.name).in(queryParamCategories);
};
}
But let’s go step by step to help you get to this approach.
Let’s first create an interface and a base implementation.
NamedQueryParametersSpecification.java:
public interface NamedQueryParametersSpecification<E> {
Map<String, Object> getNamedQueryParameters();
Specification<E> getSpecification();
}
Let’s implement it next:
AbstractNamedQueryParametersSpecification.java:
@Getter
public abstract class AbstractNamedQueryParametersSpecification<E> implements NamedQueryParametersSpecification<E> {
protected final Map<String, Object> namedQueryParameters = Maps.newHashMap();
protected Specification<E> specification;
protected <T> ParameterExpression<T> createQueryParameter(
Class<T> namedParamClazz,
String namedParamName,
T namedParamValue,
CriteriaBuilder builder) {
ParameterExpression<T> result = builder.parameter(namedParamClazz, namedParamName);
this.namedQueryParameters.put(namedParamName, namedParamValue);
return result;
}
}
This abstract class implements a base method that creates a named query parameter and keeps the parameter (name, value) pair association in a Map.
4. EXTENDING THE SPRING DATA JPA SPECIFICATION EXECUTOR
Next, let’s implement a custom JpaSpecificationExecutor.
AsimioJpaSpecificationExecutor.java:
public interface AsimioJpaSpecificationExecutor<E> extends JpaSpecificationExecutor<E> {
List<E> findAll(@Nullable NamedQueryParametersSpecification<E> specification);
}
I have defined only one method to keep this tutorial simple.
If you plan to add pagination support, you might also need to implement:
Page<T> findAll (@Nullable NamedQueryParametersSpecification<E> specification, Pageable pageable)
long count(@Nullable NamedQueryParametersSpecification<E> specification, Pageable pageable)
This is a list of methods found in JpaSpecificationExecutor that depending on your scenarios, you might need to implement passing a NamedQueryParametersSpecification<E> specification argument instead of a Specification spec one:
Optional findOne(@Nullable Specification spec) Page findAll(@Nullable Specification spec, Pageable pageable) List findAll(@Nullable Specification spec, Sort sort) long count(@Nullable Specification spec)
Let’s implement this interface now.
AsimioSimpleJpaRepository.java:
public class AsimioSimpleJpaRepository<E, ID extends Serializable> extends SimpleJpaRepository<E, ID>
implements AsimioJpaSpecificationExecutor<E> {
@Override
public List<E> findAll(@Nullable NamedQueryParametersSpecification<E> specification) {
TypedQuery<E> query = this.getQuery(specification.getSpecification(), Pageable.unpaged());
if (specification.getNamedQueryParameters() != null) {
specification.getNamedQueryParameters().forEach((k, v) -> query.setParameter(k, v));
}
return query.getResultList();
}
...
}
It extends from SimpleJpaRepository because we would like to reuse as much functionality as possible (eg getQuery(@Nullable Specification<T> spec, Pageable pageable)).
All the findAll() method does is to instantiate a TypedQuery object from the Spring Data JPA Specification and set named parameters included in the NamedQueryParametersSpecification argument.
5. SPRING DATA JPA REPOSITORIES
Let’s know associate the custom JpaSpecificationExecutor with the DAO / Repository classes.
FilmDao.java:
@Repository
public interface FilmDao extends JpaRepository<Film, Integer>, AsimioJpaSpecificationExecutor<Film> {
@EntityGraph(
type = EntityGraphType.FETCH,
attributePaths = {
"language",
"filmActors", "filmActors.actor",
"filmCategories", "filmCategories.category"
}
)
List<Film> findAll(@Nullable NamedQueryParametersSpecification<Film> specification);
...
A few things going on here:
- @Repository-annotated interface extends from AsimioJpaSpecificationExecutor interface.
- Defines
findAll(NamedQueryParametersSpecification<Film> specification)method. - Annotates the method with @EntityGraph to prevent the N+1 queries problems.
This is not enough though. You still need to specify which JPA Repository class to use.
Application.java:
@SpringBootApplication
@EnableJpaRepositories(
repositoryBaseClass = AsimioSimpleJpaRepository.class
)
@EnableTransactionManagement
public class Application {
...
}
6. SERVICE CLASS
DefaultDvdRentalService.java:
@Service
@Transactional(readOnly = true)
public class DefaultDvdRentalService implements DvdRentalService {
private final FilmDao filmDao;
@Override
public List<Film> retrieveFilms(FilmSearchCriteria searchCriteria) {
FilmSpecificationsNamedParameters filmSpecifications = FilmSpecificationsNamedParameters.createFilmSpecifications(searchCriteria);
return this.filmDao.findAll(filmSpecifications);
}
...
retrieveFilms() instantiates a Film Specifications using named query parameters object used by FilmDao repository.
FilmSearchCriteria.java:
public class FilmSearchCriteria {
private Optional<BigDecimal> minRentalRate;
private Optional<BigDecimal> maxRentalRate;
private Optional<Long> releaseYear;
private Set<String> categories;
}FilmSearchCriteria is a wrapper class to hold the request parameters passed in the endpoint request.
7. SPRING DATA JPA SPECIFICATIONS
FilmSpecificationsNamedParameters.java:
public final class FilmSpecificationsNamedParameters extends AbstractNamedQueryParametersSpecification<Film> {
private static final String QUERY_PARAM_CATEGORIES = "filmCategories";
public static FilmSpecificationsNamedParameters createFilmSpecifications(FilmSearchCriteria searchCriteria) {
FilmSpecificationsNamedParameters result = new FilmSpecificationsNamedParameters();
result.specification = result.rentalRateBetween(searchCriteria.getMinRentalRate(), searchCriteria.getMaxRentalRate())
.and(result.releaseYearEqualTo(searchCriteria.getReleaseYear()))
.and(result.categoryIn(searchCriteria.getCategories()));
return result;
}
private Specification<Film> categoryIn(Set<String> categories) {
if (CollectionUtils.isEmpty(categories)) {
return null;
}
return (root, query, builder) -> {
Join<Film, FilmCategory> filmCategoryJoin = root.join(Film_.filmCategories);
Join<FilmCategory, Category> categoryJoin = filmCategoryJoin.join(FilmCategory_.category);
ParameterExpression<Set> queryParamCategories = this.createQueryParameter(
Set.class,
QUERY_PARAM_CATEGORIES,
categories,
builder
);
return categoryJoin.get(Category_.name).in(queryParamCategories);
};
}
}
As introduced in Stafeful Spring Data JPA Specification we’ll replace creating Specification statically with a new that approach that keeps state.
createFilmSpecifications() combines the other three Specifications using AND semantic. Also, there is no need to check for null when combining Specifications.
categoryIn() adds a couple of JOIN clauses and an IN predicate to the WHERE clause.
But this time we pass in a query parameter to the .in() Criteria method instead of a Collection of values.
The base class AbstractNamedQueryParametersSpecification provides the createQueryParameter() method to instantiate the ParameterExpression object the in() method uses.
8. PADDING IN PREDICATES IN ACTION
Let’s now send a couple of GET requests to /api/films and analyze the logs:
curl http://localhost:8080/api/films/?category=Action&category=Comedy&category=Horror&minRentalRate=0.99&maxRentalRate=4.99&releaseYear=2005
The application logs:
where
(
category2_.name in (
? , ? , ? , ?
)
)
with binding parameters:
binding parameter [1] as [VARCHAR] - [Action]
binding parameter [2] as [VARCHAR] - [Comedy]
binding parameter [3] as [VARCHAR] - [Horror]
binding parameter [4] as [VARCHAR] - [Horror]
Notice the Horror value is duplicated in the IN predicate. Hibernate added an extra query parameter instead of the three categories we included in the query string and build the Specifications from.
Let’s now send five categories in the request:
curl http://localhost:8080/api/films/?category=Action&category=Comedy&category=Horror&minRentalRate=0.99&maxRentalRate=4.99&releaseYear=2005&withNamedQueryParameters=true&category=blah&category=meh
The logs look like:
where
(
category2_.name in (
? , ? , ? , ? , ? , ? , ? , ?
)
)
binding parameter [1] as [VARCHAR] - [Action]
binding parameter [2] as [VARCHAR] - [Comedy]
binding parameter [3] as [VARCHAR] - [Horror]
binding parameter [4] as [VARCHAR] - [blah]
binding parameter [5] as [VARCHAR] - [meh]
binding parameter [6] as [VARCHAR] - [meh]
binding parameter [7] as [VARCHAR] - [meh]
binding parameter [8] as [VARCHAR] - [meh]
It duplicates meh four times.
This implementation and setting hibernate.query.in_clause_parameter_padding=true pads the IN predicate’s query parameters until the next power of 2 number.
The query plan cache entry keys now looks like:
Partial cache key
Number of values Hibernate renders in the IN predicate
… ( generatedAlias2.name in (:param3) )
1
… ( generatedAlias2.name in (:param3, :param4) )
2
… ( generatedAlias2.name in (:param3, :param4, :param5, :param6) )
3, 4
… ( generatedAlias2.name in (:param3, :param4, :param5, :param6, :param7, :param8, :param9, :param10) )
5 through 8
The number of entries QueryPlanCache are reduced because the same entry is reused for similar queries with a variable number of values in the IN predicates.
Next, let’s run a load test, take and analyze a heap dump.
Reusing a previous JMeter test plan and twenty minutes into the load we got:
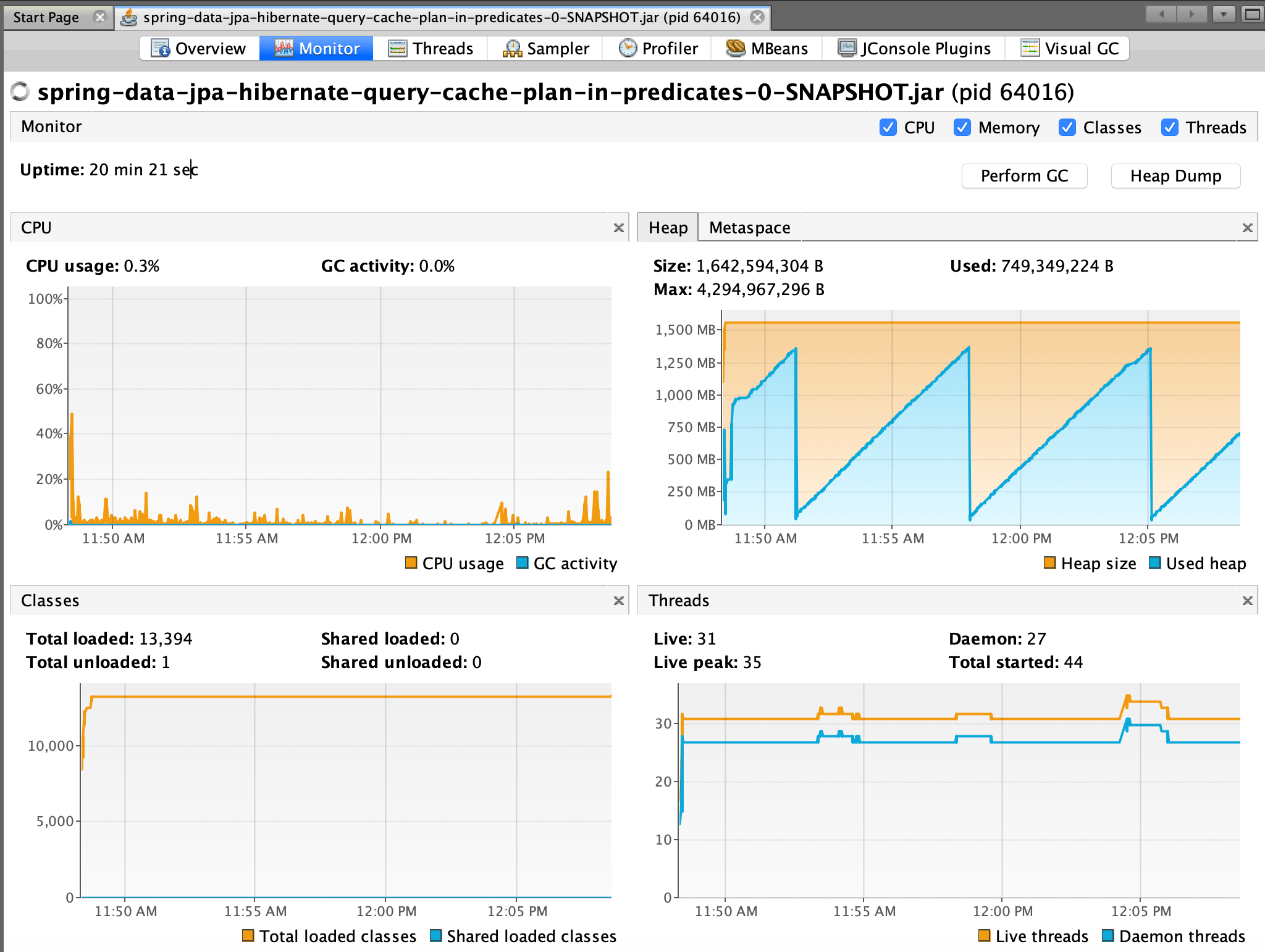
Nice peaks and drops.
Contrast this outcome with the one included when troubleshooting Spring Data JPA Specification and Criteria queries impact on Hibernate QueryPlanCache:
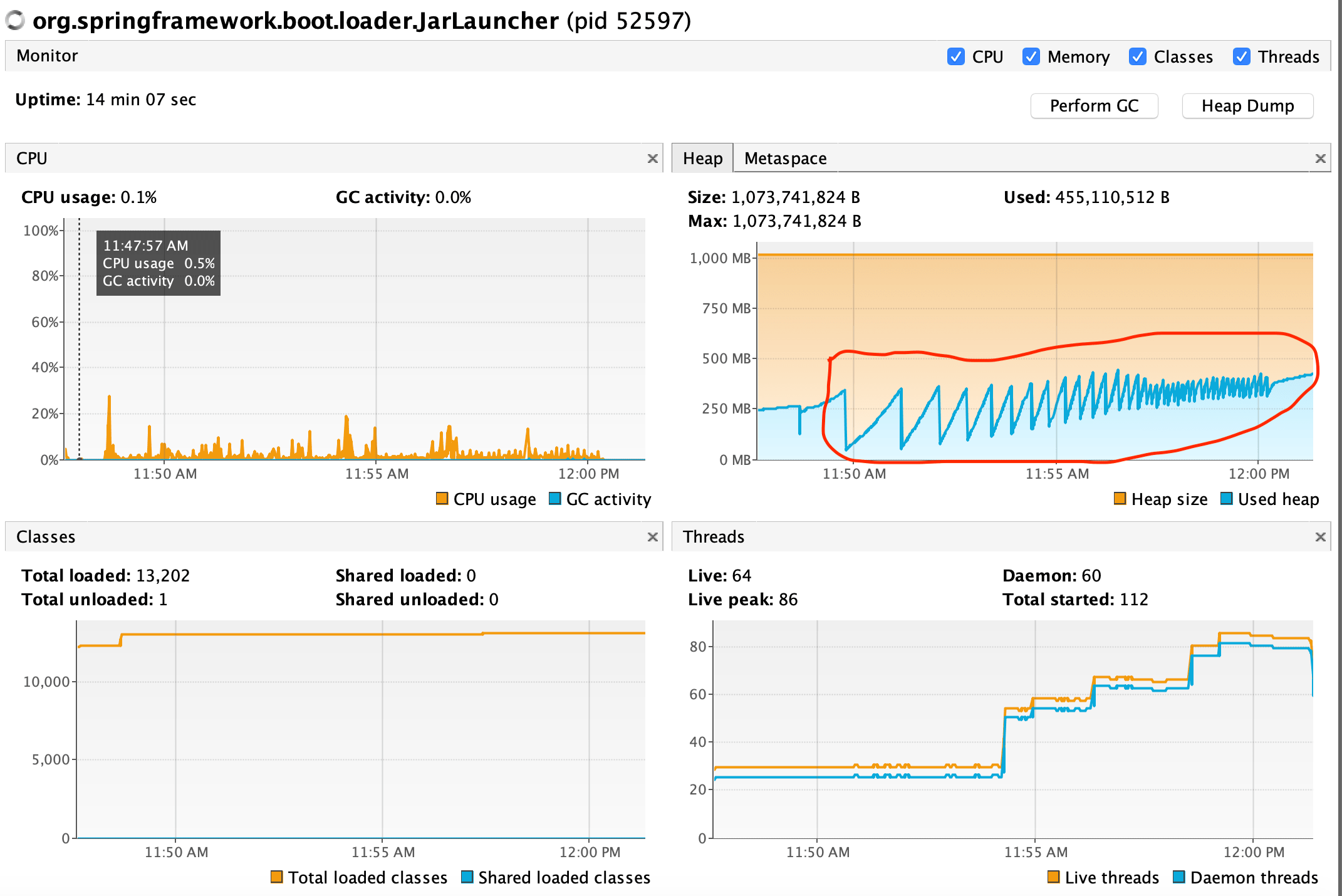
9. CONCLUSION
Padding IN predicates is a solution to reuse and reduce the number of entries in Hibernate’s QueryPlanCache.
The QueryPlanCache is known for increasing garbage collection activity and throwing OutOfMemoryError exceptions when Hibernate is not configured properly.
For some reason padding IN predicates is not working out-of-the-box when using Spring Data JPA Specification.
This blog post helps you to implement an approach to pad IN predicates using Criteria queries, named query parameters, and in_clause_parameter_padding configuration property.
Thanks for reading and as always, feedback is very much appreciated. If you found this post helpful and would like to receive updates when content like this gets published, sign up to the newsletter.
10. SOURCE CODE
Accompanying source code for this blog post can be found at:
11. REFERENCES
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK