

对话交互:封闭域任务型与开放域闲聊算法技术
source link: https://my.oschina.net/u/4273516/blog/4991445
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

前不久,OPPO旗下的人工智能助手“小布助手”月度活跃用户数突破一亿,成为国内首个月活用户数破亿的手机语音助手。
经过2年多的成长,小布助手在能力上实现大幅升级,也融入了我们身边便捷的服务功能。小布团队亦克服了诸多技术难点,为用户带来了更智能的服务。为此,小布团队撰写了一系列文章,详细介绍小布助手背后的技术支撑,本文是揭秘小布背后技术的第三篇。
第一篇:对话系统简介与小布助手的工程实践
1. 对话系统的基本架构
智能对话交互已逐步成为新一代的人机交互趋势,而OPPO研发的小布助手也已覆盖手机、手表、电视、耳机等多类终端设备,是一款集成任务型技能、知识问答、聊天、对话推荐、主动对话等综合能力的智能助理。
小布助手功能可分为五类:
系统应用类:确定的命令需求,如系统设置、时间技能、应用技能等
信息查询类:客观知识的查询/搜索需求,如“今天天气怎么样”等
泛娱乐类:满足用户娱乐需求,包括听歌、看电影等
生活服务:满足用户日常生活需求,包括导航、打车、订餐等
聊天类:主观类的闲聊需求,包括人设问答、闲聊问答、话题多轮等
小布助手架构是融合了任务型、知识问答型、聊天对话型的综合对话系统。
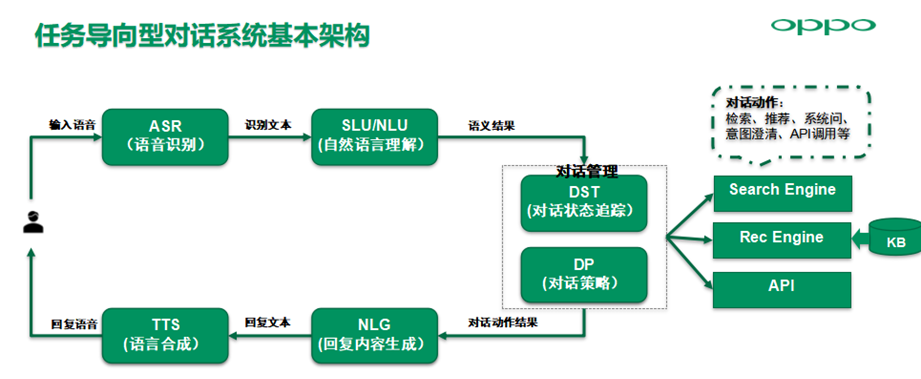
对于任务型对话系统,由用户输入语音,首先经过ASR模块识别为文本,下发到NLU服务进行自然语言语义模块,生成语义表征结果,如领域Domain+意图Intent+槽位Slot,然后下发给DM对话管理模块,然后对话状态跟踪更新上下文的对话状态,通常为词槽表征的对话状态。
对话策略模块基于当前对话状态选择最佳的回应action,下游不同BOT的action可能涉及到检索、推荐、系统问、意图澄清以及API调用;对话action的结果经过NLG模块生成合适的自然语言,最后经过TTS语音合成输出回复语音。
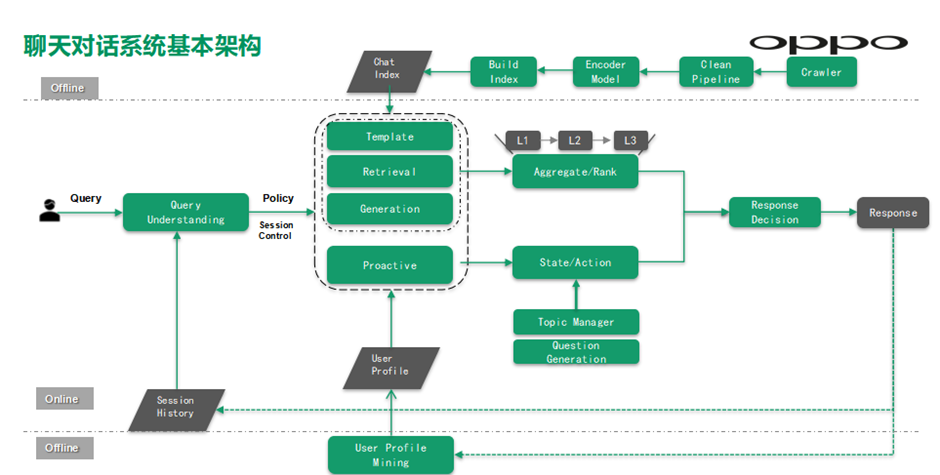
聊天对话系统主要包括以下几层。
Offline闲聊知识库索引层:主要负责基于离线训练好的语义编码模型得到所有问题Query的语义向量,然后基于高维向量索引工具生成语义索引,同时基于分词生成文本索引,最后服务于线上服务;
Online在线服务层:主要是Query话题识别情感识别等处理后,下发给应答引擎包括模板应答、检索式应答、生成式应答,以及主动对话引擎,然后融合排序模块基于应答模块输出的候选回复进行深度语义排序最终输出最佳回复,回复更新到对话上下文辅助Query理解;
另外最下面的Offline离线的用户兴趣挖掘层,主要基于用户query挖掘用户兴趣主题,最后服务于主动对话引擎,用来发起新话题吸引用户长程交互。
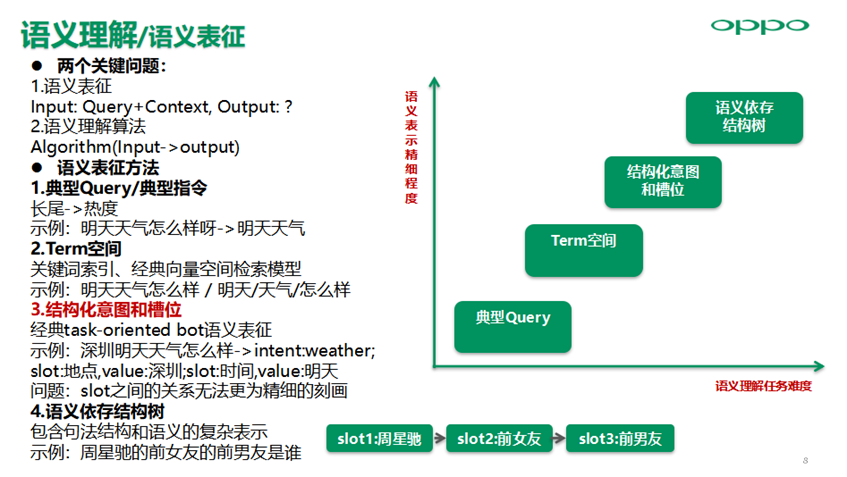
2. 任务型语义理解
语义理解中存在两个关键问题:
语义表征Input: Query+Context, Output: ?
语义理解算法Algorithm(Input->output)
语义表征方法主要包括典型Query/典型指令、Term空间、结构化意图和槽位、语义依存结构树四种。目前对话系统基本采用这种Semantic Frame意图+槽位的语义结果表征方法,意图槽位表征也存在slot之间的关系无法更为精细刻画的问题,所以对于多跳图谱问答等复杂语义依赖的场景,需要通过语义依存结构树的表征方法作为补充增强,同时语义理解任务复杂度随着语义表征精细程度会越复杂。
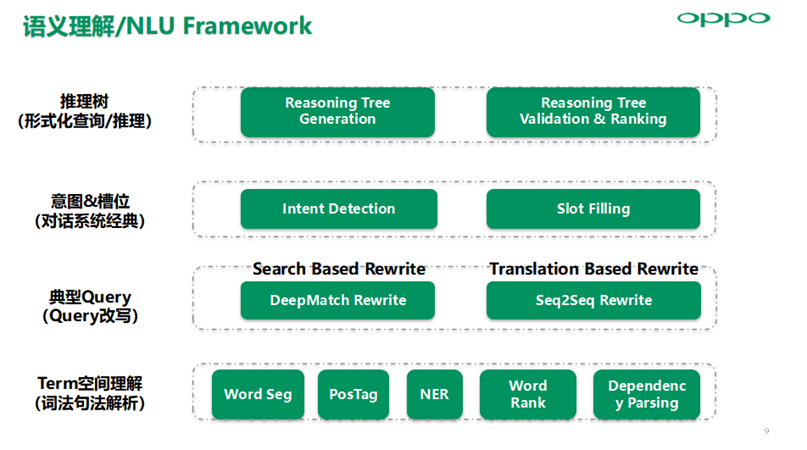
实际在一个好的工业界AI系统中,根据不同阶段和不同领域的需求差异,综合运用四个层次的NLU技术来实现,小布助手目前以意图槽位体系的语义理解为主,在信息查询百科、聊天等领域运用Query改写以及语义检索技术,来实现开放域多样且无边界的query的意图理解,在垂域问答采用查询推理树来表征语义结果。
对于意图识别算法架构,主要分为语义检索架构和分类模型架构。
语义检索的优点是偏差小在意图样本少时效果好,同时意图不用固定,可通过意图知识库任意扩展,所以扩展性强。缺点是方差大,且结果容易受噪声样本的影响,只能进行意图识别,词槽抽取无法多任务并行。适用场景是:百科问答/聊天类意图非固化且句式灵活多样的场景。
分类模型架构的优点是方差小,泛化能力强,与槽位填充可多任务并行处理。缺点则是偏差大,训练数据集少则效果不好,意图类别必须固定。适用场景是:意图类别固定的场景,如系统操控等指令类技能。

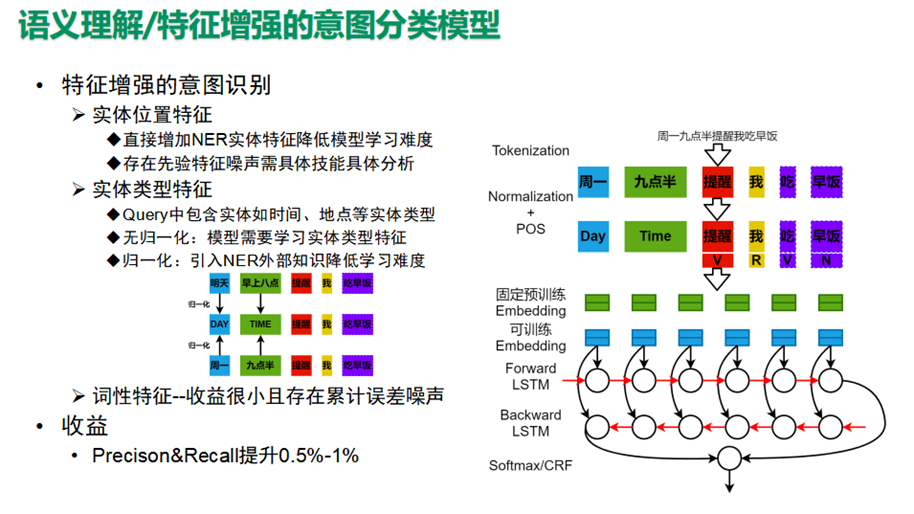
常用的意图识别算法主要是各种分类模型CNN/LSTM/Transformer。这里重点说明一下特征增强的意图识别或引入外部知识的意图识别,包括引入实体位置特征、实体类型特征、词性特征等。
实体位置特征直接增加NER实体特征降低模型学习难度,但可能存在先验特征噪声需具体技能具体分析,实体类型特征主要是引入如时间、地点等实体类型特征增强模型学习效果,准召提升均有0.5-1个点左右提升
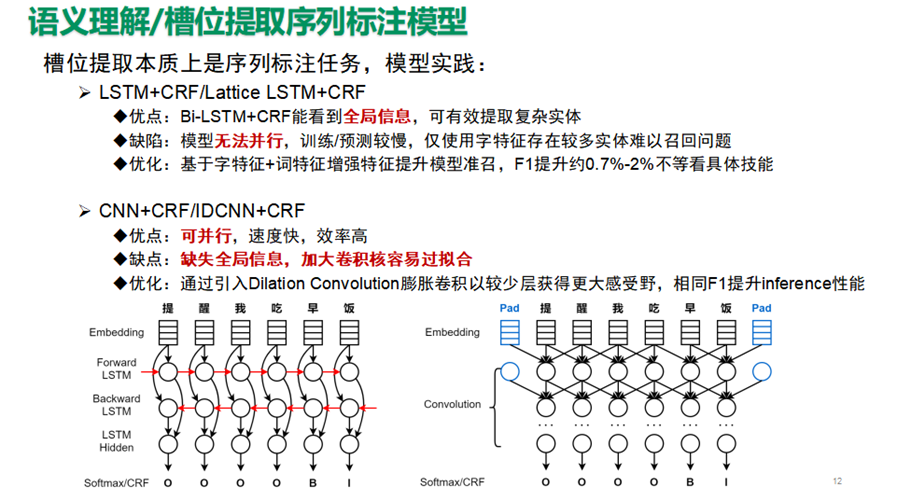
槽位提取本质上是序列标注任务,模型实践主要包括LSTM+CRF/Lattice LSTM+CRF,CNN+CRF/IDCNN+CRF,Lattice LSTM基于字特征+词特征增强特征提升模型准召,F1提升约0.7%-2%不等看具体技能,IDCNN通过引入Dilation Convolution膨胀卷积以较少层获得更大感受野,相同F1提升inference性能。
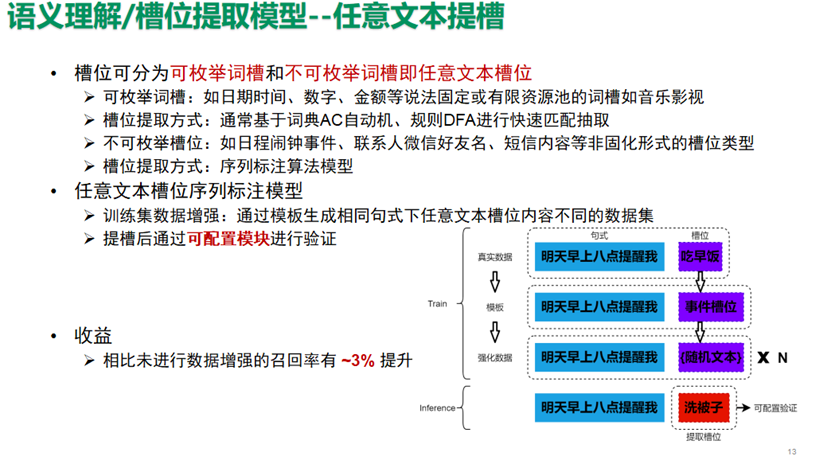
槽位可分为可枚举词槽,和不可枚举词槽,即任意文本槽位。
可枚举词槽:如日期时间、数字、金额等说法固定,或有限资源池的词槽,如音乐影视。槽位提取方式通常基于词典AC自动机、规则DFA进行快速匹配抽取。
不可枚举槽位:如日程闹钟事件、联系人微信好友名、短信内容等非固化形式的槽位类型。槽位提取方式主要是序列标注算法模型。
任意文本提槽,比如短信微信技能里的给XX发送XX信息内容,我们基于词槽内容采用任意文本填充的方式来自动化数据增强,基于训练出的提槽序列标注模型提槽后,通过可配置模块进行验证,相比未进行数据增强的模型召回率有3%以上的提升。
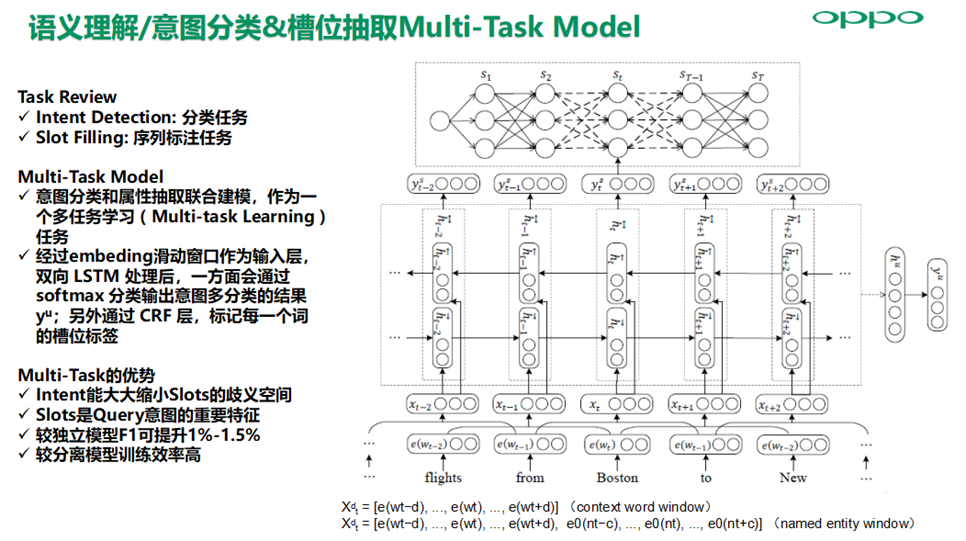
基于独立的意图识别和槽位提取模型,来进行语义理解会存在语义理解歧义问题,基于多任务联合建模可以有效缓解歧义问题, 其优势主要在于Intent能大大缩小Slots的歧义空间,因为Slots是Query意图的重要特征,较独立模型F1可提升1%-1.5%,较分离模型训练效率高。
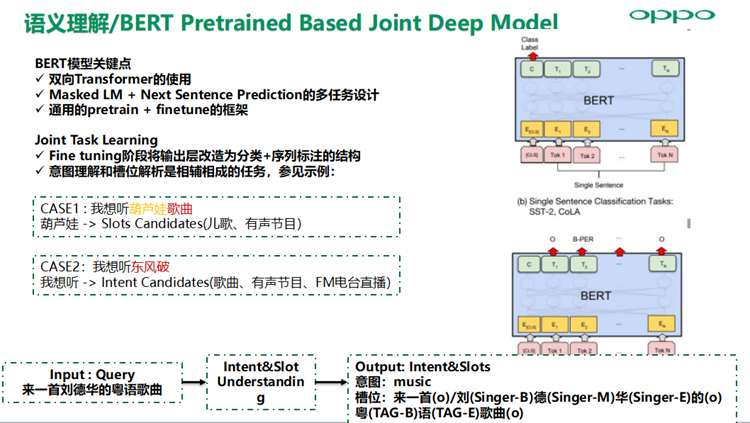
大规模预训练语言模型在由于模型容量巨大学习到丰富的知识分布,对于语料相对匮乏或提高轻量级模型效果的业务场景非常有效,基于BERT的Joint Task Learning在 Fine tuning阶段将输出层改造为分类+序列标注的结构,因为意图理解和槽位解析是相辅相成的任务,可以提升模型效果。
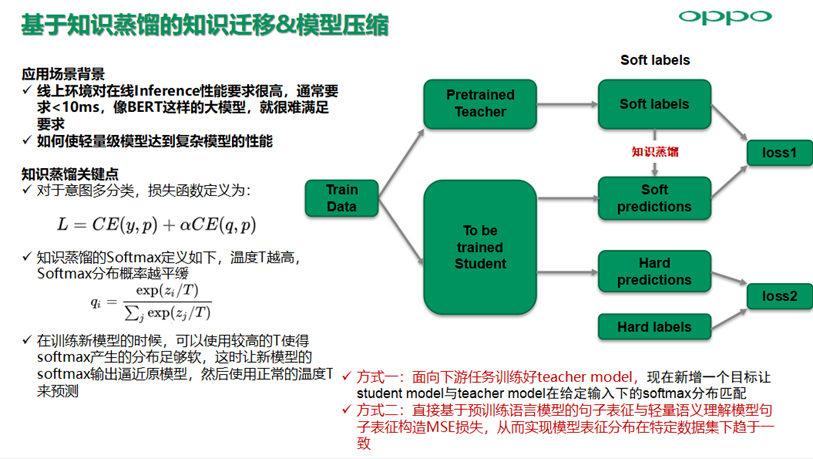
线上环境对在线Inference性能要求很高,通常要求<10ms,像BERT这样的大模型,就很难满足要求,如何使轻量级模型达到复杂模型的性能,可以通过知识蒸馏来是实现。
原来我们需要让student model的softmax分布与真实标签匹配,现在新增一个目标让student model与teacher model在给定输入下的softmax分布匹配。后者比前者具备优势,因为经过训练后的原模型,其softmax分布包含有一定的知识,真实标签只能告诉我们,某个Query是音乐意图,不是其他意图;而模型预测的softmax分布可能告诉我们,目标Query最可能是音乐意图,不大可能是电台意图,绝不可能是打开APP的意图;另外在预训练语言模型,知识蒸馏更多是想通过表征损失向轻量级模型注入更多的先验知识,在表征损失加上监督标签损失的基础上实现模型性能的提升。
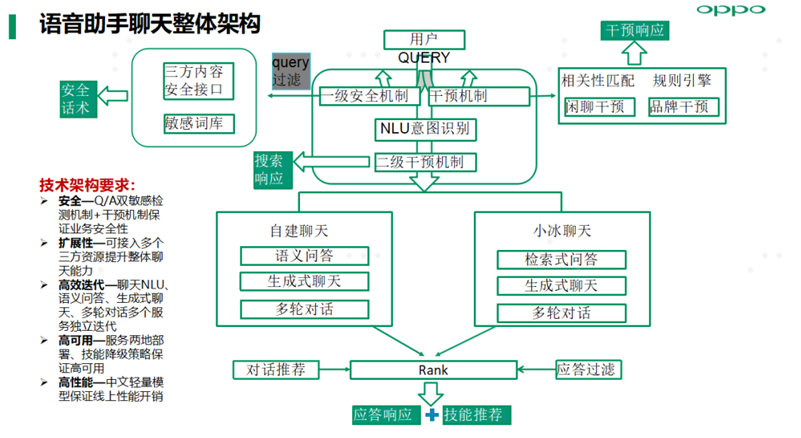
3. 开放域生成式聊天算法实践
小布助手聊天整体架构基于安全、扩展性、高效迭代、服务高可用及算法模型高性能原则进行设计,同时自建闲聊占比85%。
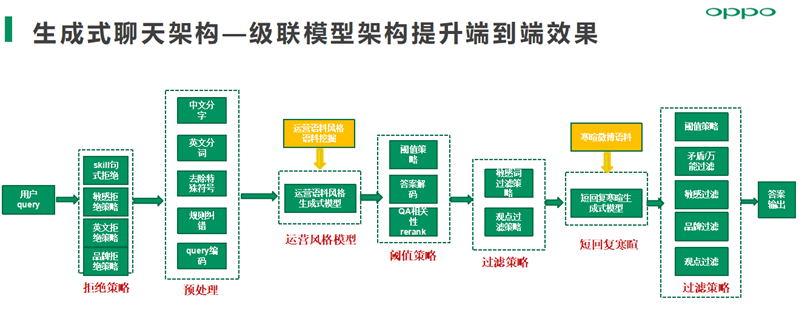
生成式聊天架构采用级联模型架构提升端到端效果,关键点如下:
拒绝策略层—提高服务性能并保证生成式回复的安全性
运营风格生成模型—基于自建闲聊知识库进行训练,尽量过拟合知识库并通过阈值策略实现结果优先
短回复寒暄生成式模型—兜底所有运营风格模型未能有效应答的部分
过滤策略层—敏感过滤、品牌过滤、强观点过滤及万能回复过滤保证回复安全与回复质量
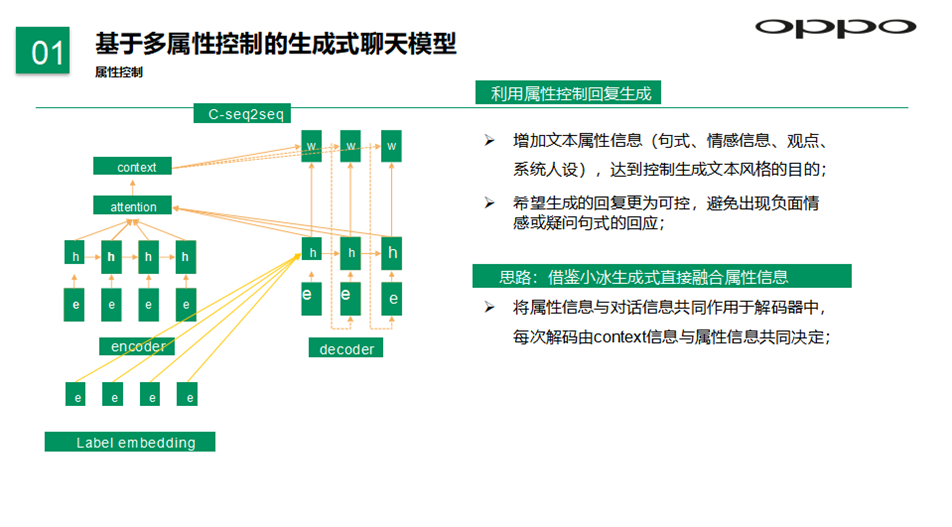
我们借鉴业内生成式直接融合属性信息,基于多属性控制的生成式模型利用属性控制回复生成,增加属性信息如句式、情感信息、观点、系统人设等,达到控制生成文本风格的目的,希望生成的回复更为可控,避免出现负面情感或疑问句式的回复。
单轮生成式闲聊模型分为运营风格和通用回复风格两种。运营风格生成式模型是基于运营同学编写的闲聊知识库来训练的,通用回复风格模型是基于开源微博单轮对话数据集来训练的,具体效果还是可以看到存在部分万能回复的问题,以及敏感QUERY和强观点型配对容易产生敏感问题。
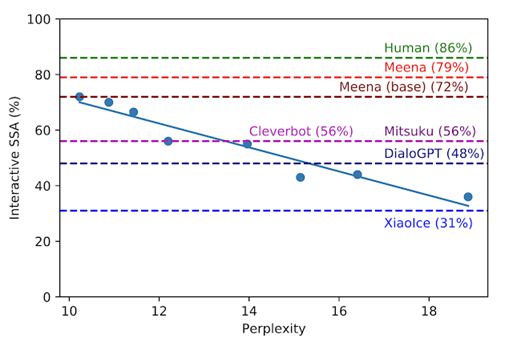
多轮生成式聊天业界主流方案如下,多轮聊天的人工评测标准主要是Google Meena率选提出SSA人工评测标准,SSA (Sensibleness and Specificity Average):Sensibleness -->合理性(敏感性), Specificity --> 针对性(特异度),同时也发现优化目标:Perplexity与SSA高相关,优化Perplexity即可提升SSA。
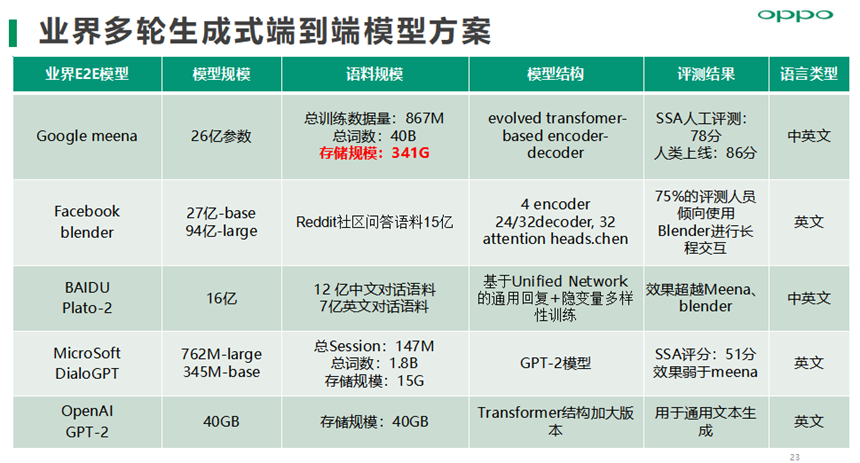
多轮生成式聊天算法模型方案,目前已经实践的有两种,一种是基于12层中文GPT2模型在多轮对话数据集上Finetune,另外一种是基于华为NEZHA语言模型+下三角Attention Mask变成单向语言模型,再在多轮对话数据集上Finetune。
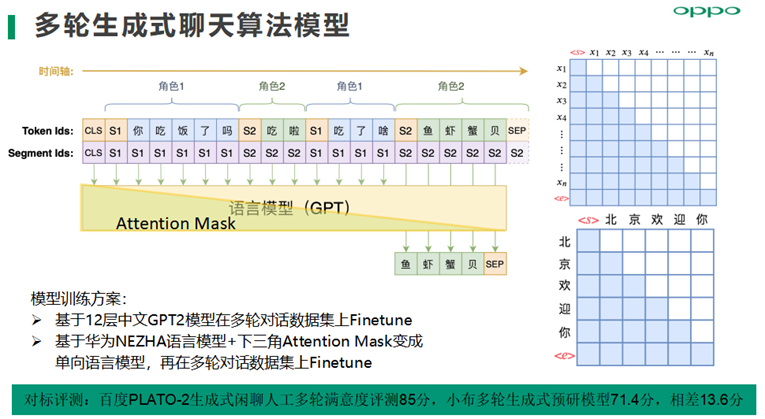
多轮生成式挑战主要是,受限于上下文记忆能力会出现回复自相矛盾、缺乏知识信息量、生成回复的可控性等问题。
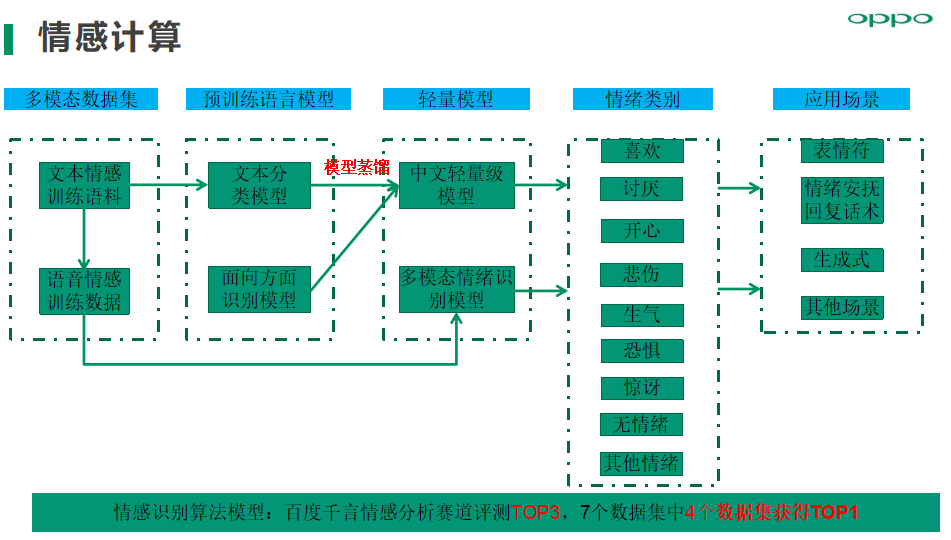
情感识别算法模型:我们在百度千言情感分析赛道评测TOP3,主要应用场景包括表情符,情绪安抚、生成式闲聊、其他待挖掘的情感化场景;目前情绪类别支持喜欢、讨厌、开心、悲伤、生气、恐惧、惊讶、无情绪、其他情绪9种情绪类别。
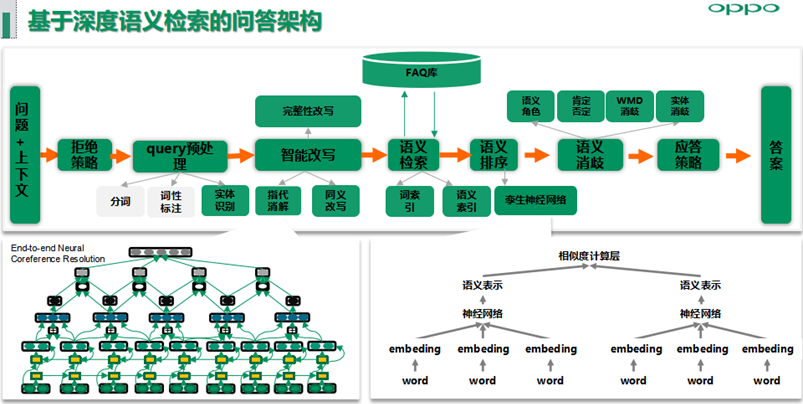
4. 深度语义问答FQA技术实践
语义匹配问答架构主要分为拒绝策略层、Query预处理、智能改写包括代词指代消解、同义词改写以及后续规划的语义递进或转折场景下的完整性改写、语义检索、语义排序、语义消歧等可配置模块,可配置的策略模块用于快速解决线上高优BADCASE问题,同时小布助手在百度语义匹配赛道冲击过第一名。
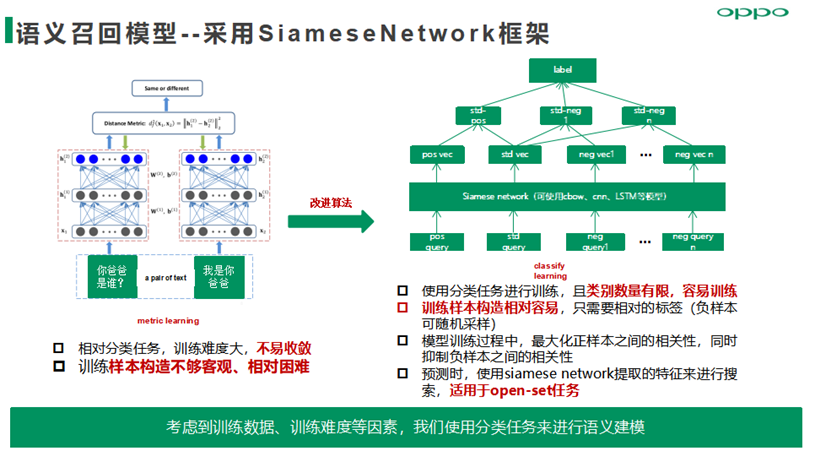
语义召回模型——采用SiameseNetwork框架,使用分类任务建模思路进行训练,且训练样本数据范式采用listwise范式,模型目标是最大化正样本之间的相关性,同时抑制负样本之间的相关性。
语义匹配模型实践方面,对于负样本采样策略优先使用标注的负样本,标注负样本不足情况下,通过卡字面相关性阈值策略进行负采样,以保证负样本有一定相关性,尽量构建semi-hard数据集用来加速模型收敛,同时提升模型语义表征精度;损失函数方面我们主要尝试hinge loss、Triplet Loss、AMSoftMax等。
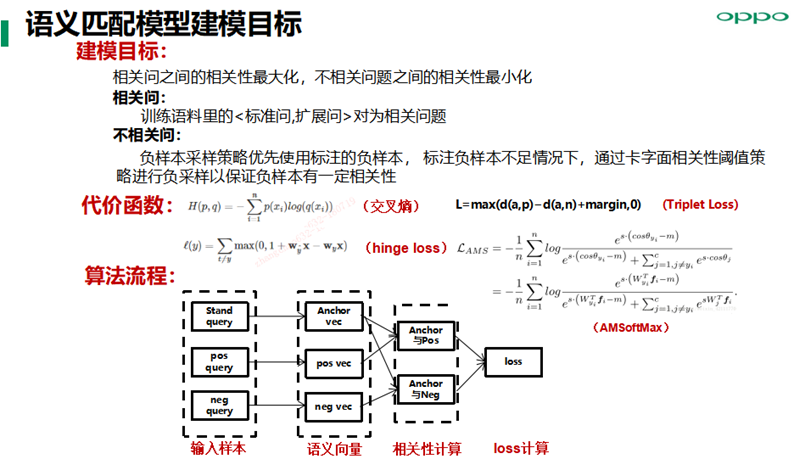
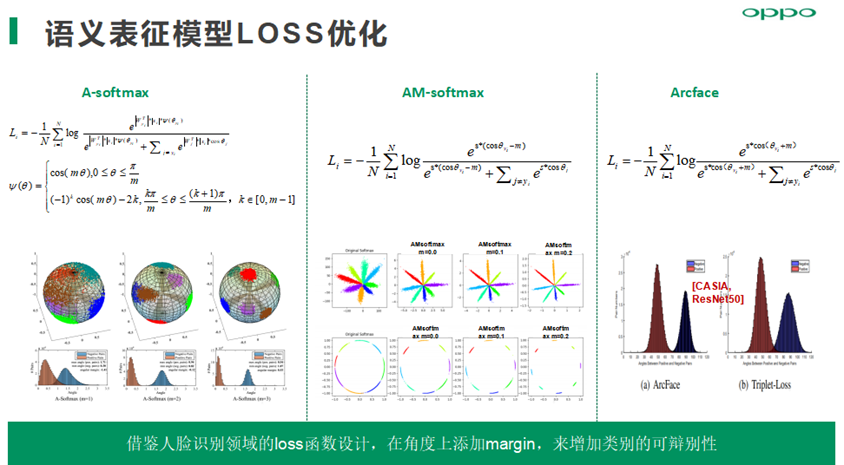
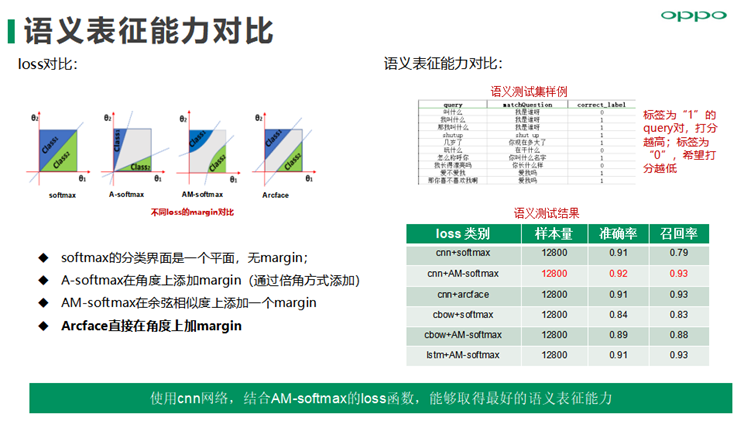
AM-softmax在余弦相似度上添加一个margin,可以提高类间可分及类别的可辨别性, 使用cnn网络,结合AM-softmax的loss函数,能够取得最好的语义表征能力,通用评测集下的准确率提升1%,同时召回提升明显。
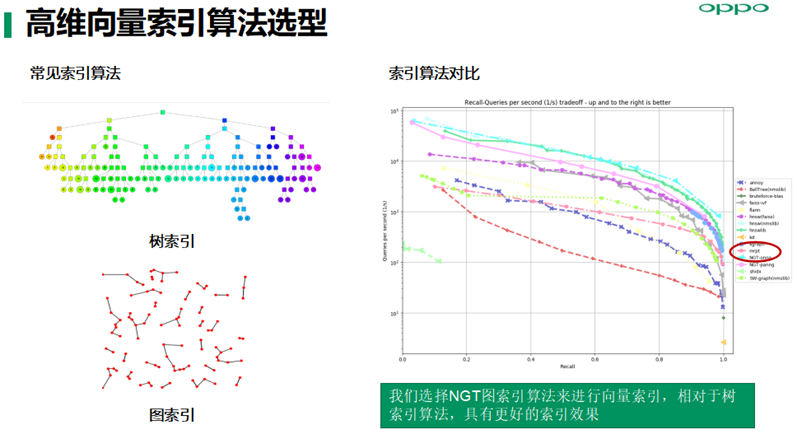
高纬数据索引算法主要有树索引和图索引两种,通过基于同等召回率的召回性能试验对比,我们选择NGT图索引算法来进行向量索引,相对于树索引算法,具有更好的索引效果及索引性能。
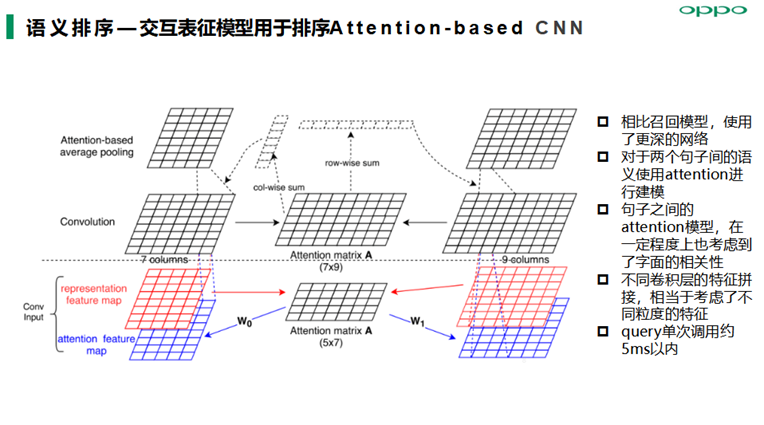
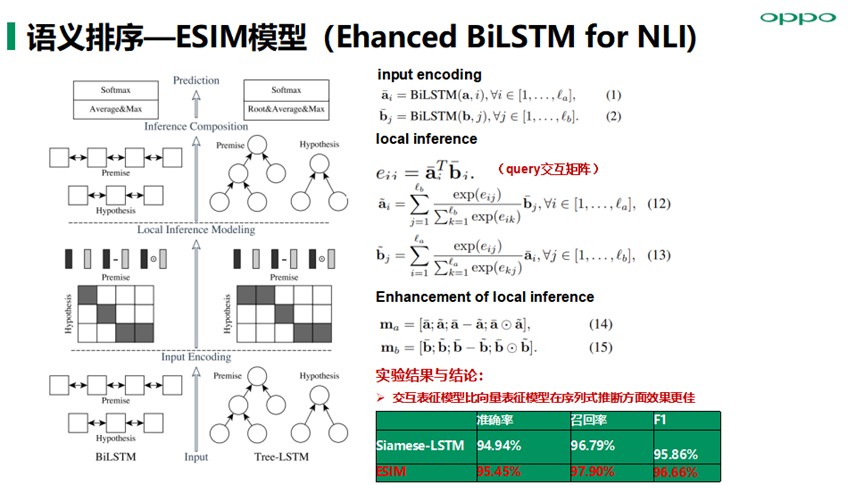
语义排序算法模型主要落地实践了交互表征模型Attention-based CNN、ESIM模型(Ehanced BiLSTM for NLI)以及Transformer模型等,在召回阶段我们得到的候选query集合,然后基于用户当前query与候选query进行交互式表征建模能提高语义表征精度从而提高语义匹配准确率;另外ESIM模型优点在于精细设计的序列式推断结构,考虑局部推断和全局推断的融合,准召效果相对也会高一些 。
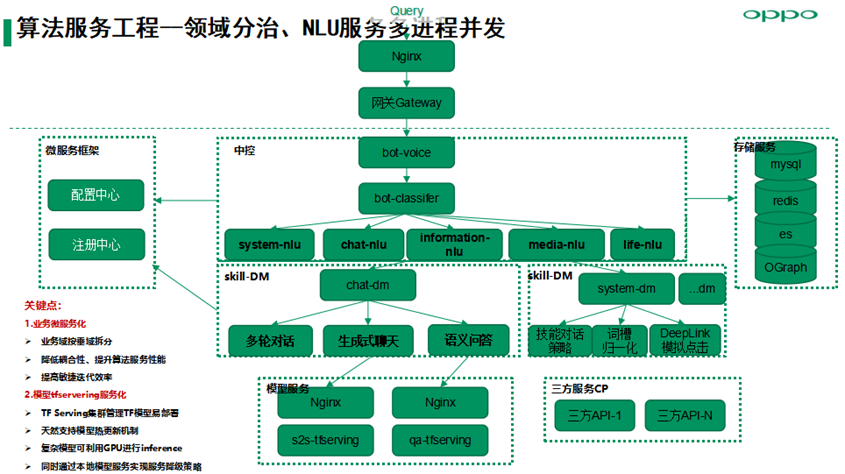
5. 算法服务工程
算法服务架构主要基于领域分治、NLU服务多进程并发高性能的原则进行设计。关键点:
业务微服务化,业务域按垂域拆分,降低耦合性、提升算法服务性能,提高敏捷迭代效率;
模型tfservering服务化,TF Serving集群管理TF模型易部署,天然支持模型热更新机制,复杂模型可利用GPU进行inference,同时通过本地模型服务实现服务降级策略。
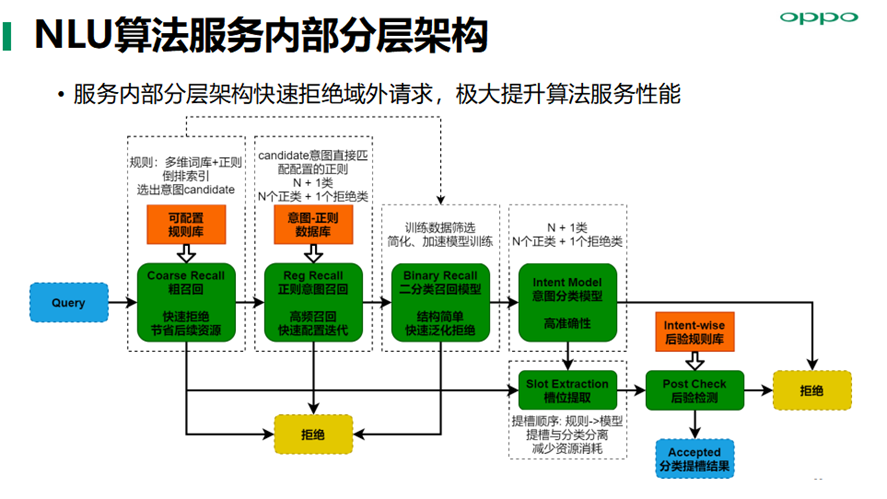
NLU算法服务内部分层架构,多层次拒绝/召回,域外粗召回到域外高召回再到域内高准确, 通过可配置模块高效解决Case类问题,避免引入破坏模型平衡的问题,模型分布收敛到线上数据分布后保持稳定。

服务内部分层架构快速拒绝域外请求,极大提升算法服务性能,保障小布助手端到端流畅度的性能体验。
6. 总结与展望
封闭域任务型对话技术关键挑战有多个,比如,语义理解模型的鲁棒性,特别是高频技能线上query分布变化快,如何保证线上模型泛化性是关键;对话能力更自然流畅的对话管理技术;上下文意图理解(当前已经具备人称/实体代词、部分零指代的指代消解能力,但泛化能力有限);融合设备渠道、LBS位置信息及客户端状态等场景特征+用户基本属性+用户兴趣画像的综合意图理解。
开放域对话技术方面,检索式聊天技术能解决高频头部query问题,但解决不了长尾问题以及开放域多轮对话问题。融合知识问答、闲聊、对话推荐为一体的端到端多轮生成式,是未来ChatBot的关键技术方向。
这里也存在不少技术挑战,包括保罗万象的知识问答、情绪感知的共情能力、融合系统画像与用户画像的回复生成、逻辑/观点/人设一致性、回合制被动问答向主动式对话演进、全双工的持续对话能力。
☆ END ☆
招聘信息OPPO互联网技术团队招聘一大波岗位,涵盖C++、Go、OpenJDK、Java、DevOps、Android、ElasticSearch等多个方向,请点击这里查看详细信息及JD。
你可能还喜欢
更多技术干货
OPPO互联网技术
 我就知道你“在看”
我就知道你“在看”

本文分享自微信公众号 - OPPO互联网技术(OPPO_tech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK