

记一次调用外网服务概率性失败问题的排查
source link: https://club.perfma.com/article/2322738
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

记一次调用外网服务概率性失败问题的排查
和外部联调一直是令人困扰的问题,尤其是一些基础环境配置导致的问题。笔者在一次偶然情况下解决了一个调用外网服务概率性失败的问题。在此将排查过程发出来,希望读者遇到此问题的时候,能够知道如何入手。
笔者的新系统上线,需要PE执行操作。但是负责操作的PE确和另一个开发在互相纠缠,让笔者等了半个小时之久。本着加速系统上线的想法,就想着能不能帮他们快速处理掉问题,好让笔者早点发完回去coding。一打听,这个问题竟然扯了3个月之久,问题现象如下:
每个client都会以将近1/2的概率失败,而且报错都为:
java.net.SocketTimeoutException: Read timed out
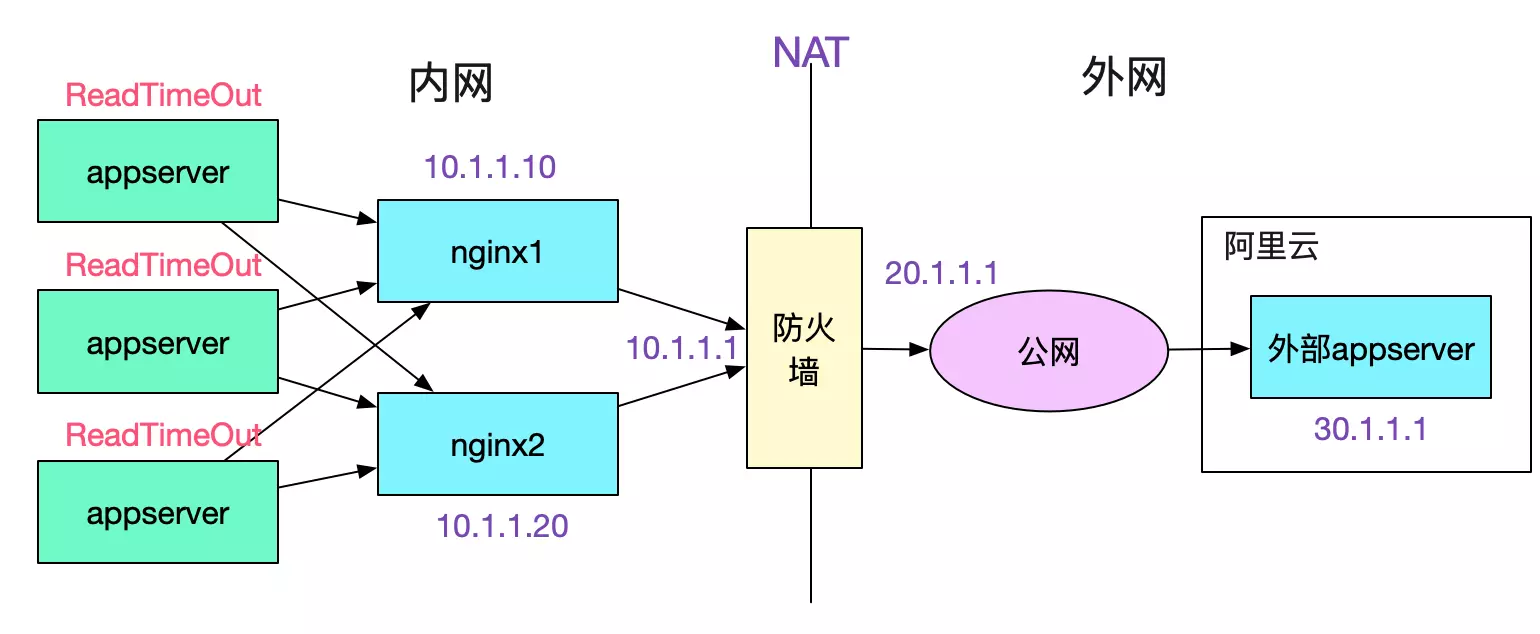
和appserver开发以及对应的PE交流发现,appserver和nginx之间是短连接,由于是socketTimeOutException,于是能够排除appserver和nginx建立连接之间的问题。去nginx上排查日志,发现一个奇异的现象,如下图所示:
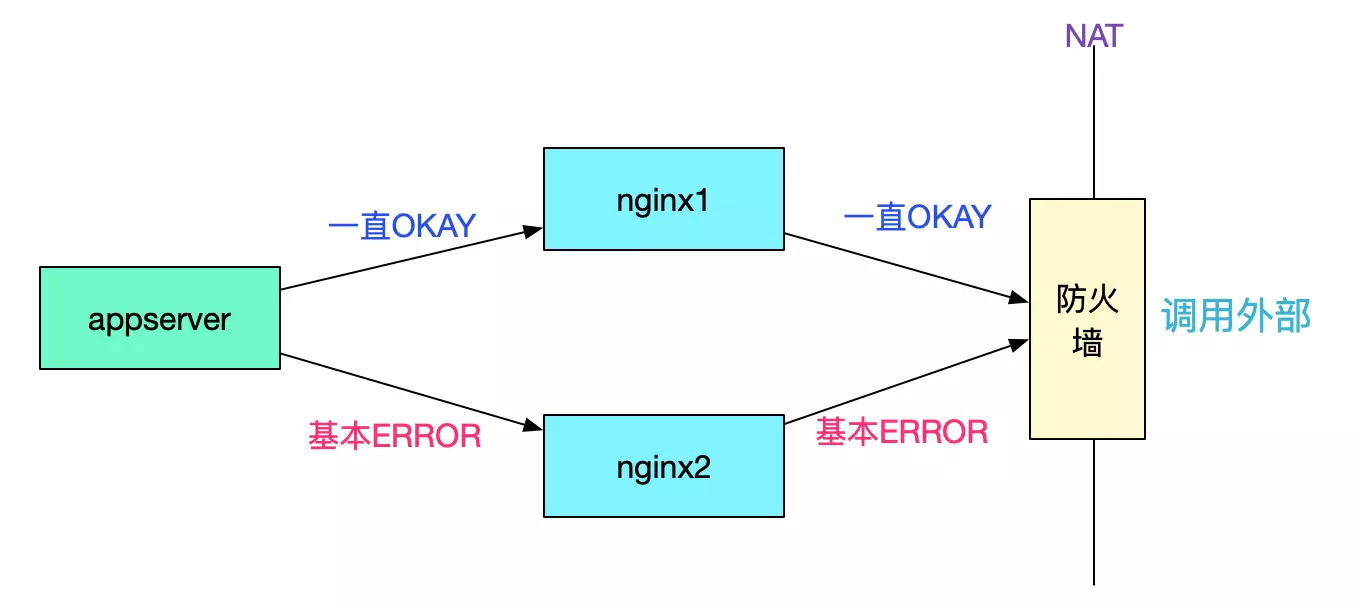
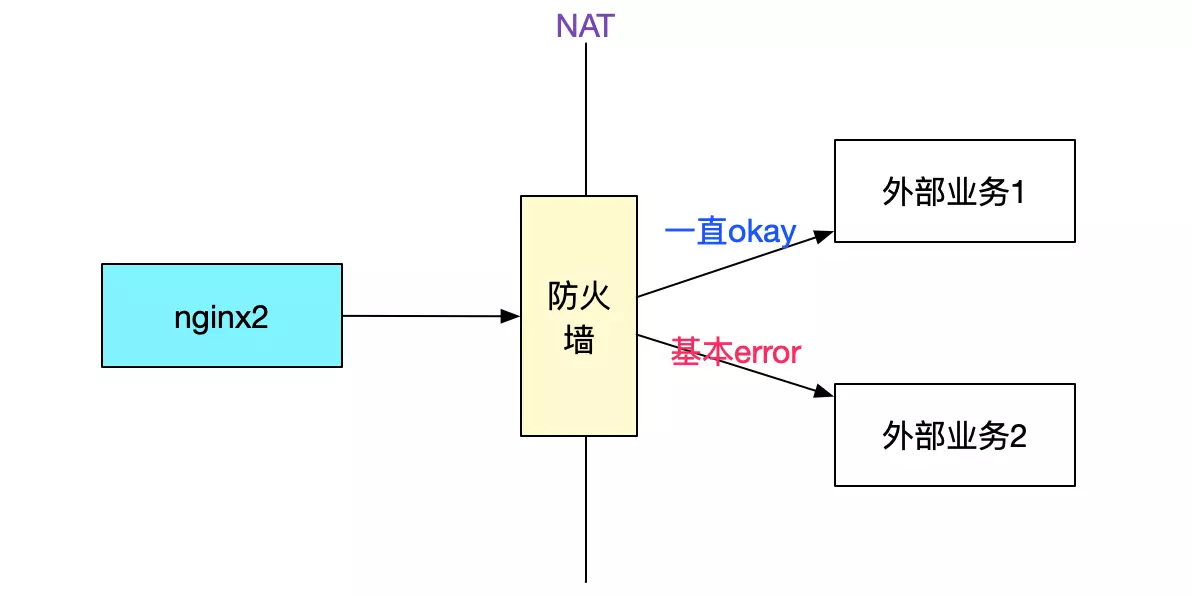
所有的appserver都是调用一台nginx一直成功,而调用另一台nginx大概率失败。而两台nginx机器的配置一模一样,还有一个奇怪的点是,只有在调用出问题的对端服务器时才会失败,其它业务没有任何影响,如下图所示:
由于这两个诡异的现象导致开发和PE争执不下,按照第一个现象一台nginx好一台nginx报错那么第二台nginx有问题是合理的推断,所以开发要求换nginx。按照第二个现象,只有调用这个业务才会出错,其它业务没有问题,那么肯定是对端业务服务器的问题,PE觉得应该不是nginx的锅。争执了半天后,初步拟定方案就是扩容nginx看看效果-_-!笔者觉得这个方案并不靠谱,盲目的扩容可能会引起反效果。还是先抓包看看情况吧。
其实笔者觉得nginx作为这么通用的组件不应该出现问题,问题应该出现在对端服务器上。而根据对端开发反应,他自己curl没问题,并现场在他自己的服务器上做了N次curl也没有任何问题(由于这个问题僵持不下,他被派到我们公司来协助排查)。于是找网工在防火墙外抓包,抓包结果如下:
由于appserver端设置的ReadTimeOut超时时间是3s,所以在2次syn重传后,对端就已经报错。如下图所示:
(注:nginx所在linux服务器设置的tcp_syn_retries是2)
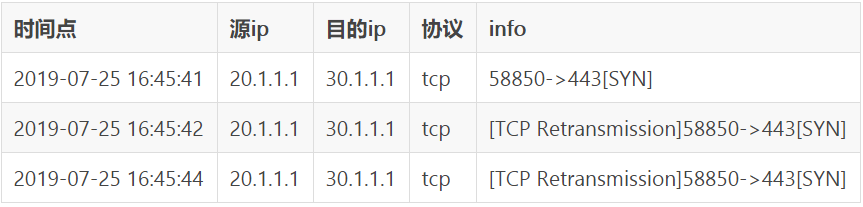
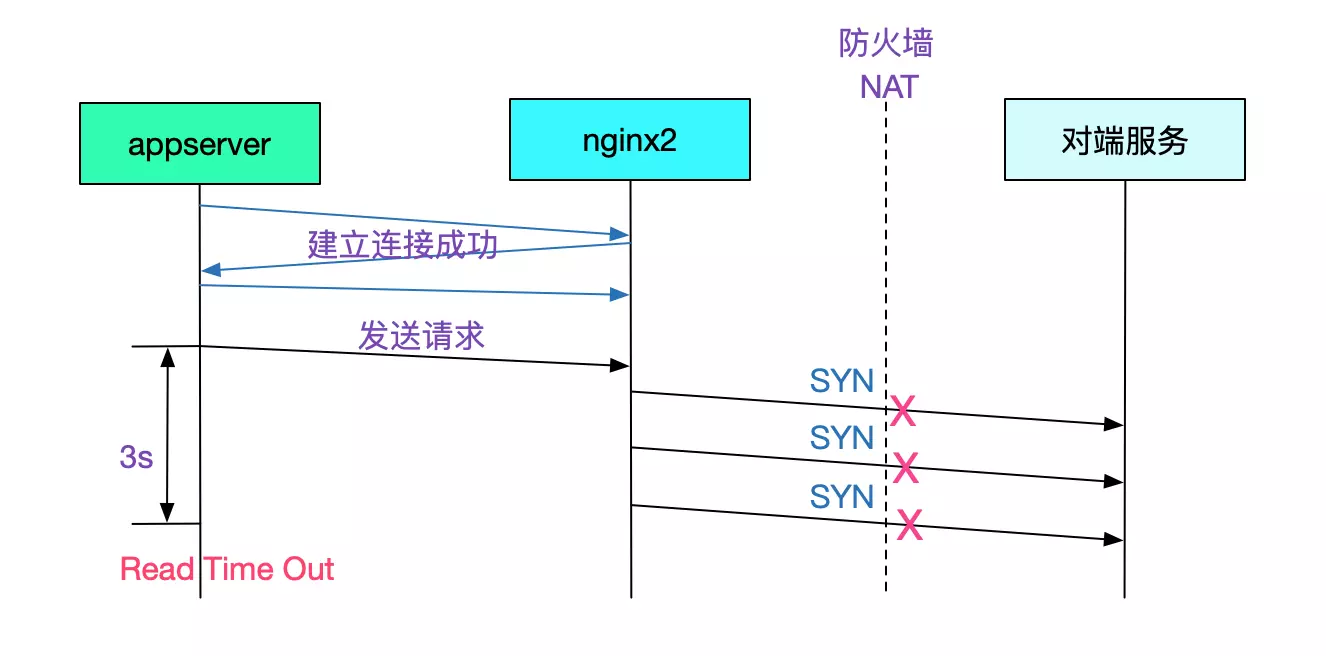
抓包结果分析
从抓包得出的数据来看,第二台nginx发送syn包给对端服务,对端服务没有任何响应,导致了nginx2创建连接超时,进而导致了appserver端的ReadTimeOut超时(appserver对nginx是短连接)。
按照正常推论,应该是防火墙外到对端服务的SYN丢失了。而阿里云作为一个非常稳定的服务商,应该不可能出现如此大概率的丢失现象。而从对端服务器用的是非常成熟的SpringBoot来看,也不应该出现这种bug。那么最有可能的就是对端服务器本身的设置有问题。
登陆对端服务器进行排查
由于对方的开发来到了现场,于是笔者就直接用他的电脑登录了服务所在的阿里云服务器。首先看了下dmesg,如下图所示,有一堆报错:
dmesg:
__ratelimit: 33491 callbacks suppressed
TCP: time wait bucket table overflow
TCP: time wait bucket table overflow
TCP: time wait bucket table overflow
......
感觉有点关联,但是仅靠这个信息无法定位问题。紧接着,笔者运行了下netstat -s:
netstat -s
......
16990 passive connections rejected because of time stamp
......
这条命令给出了非常关键的信息,翻译过来就是有16990个被动连接由于时间戳(time stamp)而拒绝!查了下资料发现这是由于设置了
tcp_timestamps == 1 && tcp_tw_recycle == 1
在NAT情况下将会导致这个被动拒绝连接的问题。而为解决上面的dmesg日志,网上给出的解决方案就是设置tcp_tw_recycle=1而tcp_timestamps默认就是1,同时我们的客户端调用也是从NAT出去的,符合了这个问题的所有特征。 于是笔者尝试着将他们的tcp_timestamps设为0,
echo '0' > /proc/sys/net/ipv4/tcp_timestamps
or
echo '0' > /proc/sys/net/ipv4/tcp_tw_recycle
又做了几十次调用,再也没有任何报错了!
linux源码分析
问题虽然解决了,但是笔者想从源码层面看一看这个问题到底是怎么回事,于是就开始研究对应的源码(基于linux-2.6.32源码)。 由于问题是发生在nginx与对端服务器第一次握手(即发送第一个syn)的时候,于是我们主要跟踪下这一处的相关源码:
// 三次握手第一个SYN kernel走的分支
tcp_v4_do_rcv
|->tcp_v4_hnd_req
|->tcp_rcv_state_process
/** case TCP_LISTEN && th->syn */
|->conn_request(tcp_v4_conn_request)
关于tcp_timestamps的代码就在tcp_v4_conn_request里面,我们继续追踪(以下代码忽略了其它不必要的逻辑):
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
......
/* VJ's idea. We save last timestamp seen
* from the destination in peer table, when entering
* state TIME-WAIT, and check against it before
* accepting new connection request.
* 注释大意为:
* 我们在进入TIME_WAIT状态的时候将最后的时间戳记录到peer tables中,
* 然后在新的连接请求进来的时候检查这个时间戳
*/
// 在tcp_timestamps和tcp_tw_recycle开启的情况下
if (tmp_opt.saw_tstamp &&
tcp_death_row.sysctl_tw_recycle &&
(dst = inet_csk_route_req(sk, req)) != NULL &&
(peer = rt_get_peer((struct rtable *)dst)) != NULL &&
peer->v4daddr == saddr) {
/** TCP_PAWS_MSL== 60 */
/** TCP_PAWS_WINDOW ==1 */
// 以下都是针对同一个对端ip
// tcp_ts_stamp 对端ip的连接进入time_wait状态后记录的本机时间戳
// 当前时间在上一次进入time_wait记录的实际戳后的一分钟之内
if (get_seconds() < peer->tcp_ts_stamp + TCP_PAWS_MSL &&
// tcp_ts 最近接收的那个数据包的时间戳(对端带过来的)
// 对端当前请求带过来的时间戳小于上次记录的进入time_wait状态后记录的对端时间戳
(s32)(peer->tcp_ts - req->ts_recent) >
TCP_PAWS_WINDOW) {
// 增加被动连接拒绝的统计信息
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_PAWSPASSIVEREJECTED);
// 进入丢弃和释放阶段
goto drop_and_release;
}
}
......
}
上述代码的核心意思即是在tcp_timestamps和tcp_tw_recycle开启的情况下,同样ip的连接,在上个连接进入time_wait状态的一分钟内,如果有新的连接进来,而且新的连接的时间戳小于上个进入time_wait状态的最后一个包的时间戳,则将这个syn丢弃,进入drop_and_release。我们继续跟踪drop_and_release:
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb){
......
drop_and_release:
dst_release(dst);
drop_and_free:
reqsk_free(req);
drop:
return 0;
}
我们继续看下如果tcp_v4_conn_request返回0的话,系统是什么表现:
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb,
struct tcphdr *th, unsigned len)
{
......
// 由于tcp_v4_conn_request所以不走下列分枝
if (icsk->icsk_af_ops->conn_request(sk, skb) < 0)
return 1
// 所以此处也返回0
kfree_skb(skb);
return 0;
}
// 再跳回tcp_v4_do_rcv
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
// 由于tcp_rcv_state_process这边返回的是0,所以不走reset的逻辑
if (tcp_rcv_state_process(sk, skb, tcp_hdr(skb), skb->len)) {
rsk = sk;
goto reset;
}
// 走到这边之后,不发送reset包,不给对端任何响应
TCP_CHECK_TIMER(sk);
return 0;
}
从源码的跟踪可以看出,出现此种情况直接丢弃对应的syn包,对端无法获得任何响应从而进行syn重传,这点和抓包结果一致。
和问题表象一一验证
为什么会出现一台nginx一直okay,一台nginx失败的情况
由于tcp的时间戳是指的并不是当前本机用date命令给出的时间戳。这个时间戳的计算规则就在这里不展开了,只需要知道每台机器的时间戳都不相同即可(而且相差可能极大)。由于我们调用对端采用的是NAT,所以两台nginx在对端服务器看来是同一个ip,那么这两台的时间戳发送到对端服务器的时候就会混乱。nginx1的时间戳比nginx2的时间戳大,所以在一分钟之内,只要出现nginx1的连接请求(短连接),那么之后的nginx2的连接请求就会一直被丢弃。如下图所示:
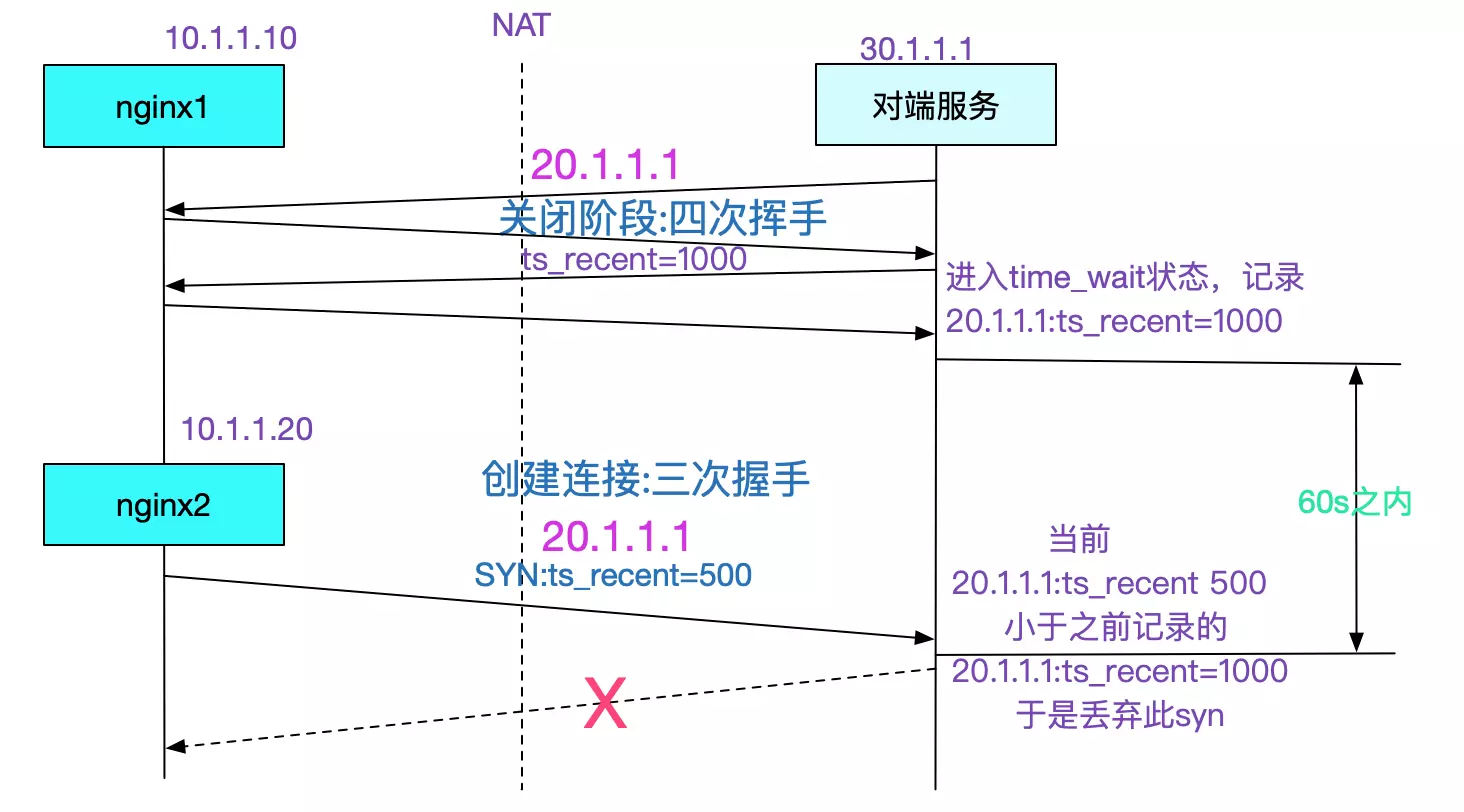
为什么对端自测一直正常
因为本机调用本机的时时间戳是一台机器(本机)上的,所以不会出现混乱。
为什么nginx2调用其它服务是正常的
因为其它外部服务所在服务器并没有开启tcp_tw_recycle。这个问题事实上将tcp_tw_recycle置为0也可以解决。另外,高版本的linux内核已经去掉了tcp_tw_recycle这个参数。
由于当前ip地址紧缺和DNS报文大小的限制(512字节),大部分网络架构都是采用NAT的方式去和外部交互,所以设置了tcp_tw_recycle为1基本都会出现问题。一般这种问题需要对tcp协议有一定的了解才能够顺藤摸瓜找到最终的根源。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK