

拥抱 Agent,“0” 代码玩转 Trace 之 OpenTelemetry 系列第二弹!
source link: https://my.oschina.net/u/4587289/blog/5001108
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.



导读
OpenTelemetry 兼容 OpenTracing,概念上也有很多类似。OpenTracing 有点儿像 OpenTelemetry 的现在式,OpenTelemetry 是 OpenTracing 的未来时。由于 OpenTelemetry 包含了 Tracing,Logging 和 Metrics,又还在 SandBox 阶段,所以我们先来通过 OpenTracing 了解这个领域。
作者介绍
徐为
腾讯云微服务团队高级解决方案构架师
毕业于欧盟 Erasmus Mundus IMMIT,获得经济和IT管理硕士学位
自2006年以来,曾就职于SonyEricsson、SAP、Cloud等多家公司,历任软件开发工程师,数据开发工程师,解决方案架构师

首先从 Tracing 本身的数据结构来看,OpenTracing 和 OpenTelemetry 两者是非常类似的,这里我先用 OpenTracing 的结构举例说明(因为 OpenTelemetry 是承诺兼容 OpenTracing 的,plus OpenTelemetry 当前还是 SandBox 项目,后面的变化还可能会很多)。
Tracing 的基本数据结构
如下图所示,单一的 Tracing 链路可以用一个类似于树形的结构来表示,最上面是链路的发起端,然后下面就是所有在这条 Trace 下发生的 Span。Span 之间可以是父子的逻辑(如图 SpanB 和 SpanC 之于 SpanA 的关系,SpanB 和 SpanC 可以是顺序执行也可以是并行),还可以是旁挂(FollowsFrom)的逻辑(比如 SpanG 和 SpanF)
# ref: https://github.com/opentracing/specification/blob/master/specification.md#the-opentracing-data-modelCausal relationships between Spans in a single Trace[Span A] ←←←(the root span)|+------+------+| |[Span B] [Span C] ←←←(Span C is a `ChildOf` Span A)| |[Span D] +---+-------+| |[Span E] [Span F] >>> [Span G] >>> [Span H]↑↑↑(Span G `FollowsFrom` Span F)
再说的详细一些,FollowsFrom 就意味着,父 Span 不用等待子 Span 的返回而结束,很多场景是这个逻辑,比如下单成功等待商家确认 - 商家确认的流程是下单时候触发的,却不需要商家确认来完成下单。类似的场景很多,但是在 OpenTracing 里没有做更详细的划分。
如果从时间轴上来看,大约就是下图这个样子,每个服务从什么时候开始,到什么时候结束,上下的关系等都在 Web GUI 上有详细的显示。
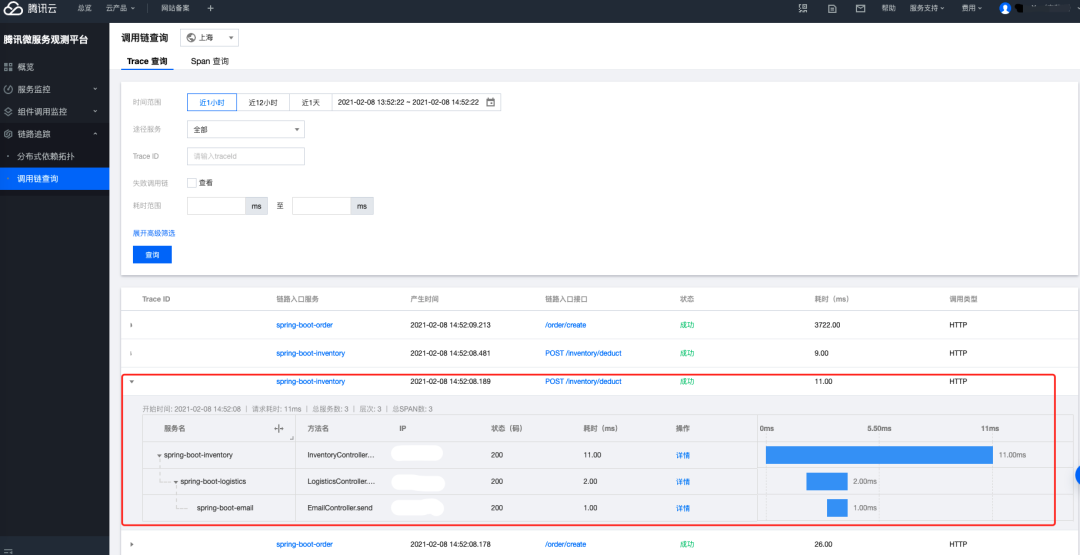
然后具体来说说这些 Span 是怎么被创建的,上下游都需要什么信息。很多组建都被集成到了框架里面,提供了免费的午餐,但是也屏蔽了数据结构的创建,所以我们用最基础的 OpenTracing SDK 来看一下这个创建流程。下面这个是最简单的 hello world 程序,用最简单的代码完成了一个全流程。
# Ref: https://opentracing.io/guides/javascript/const http = require('http');const opentracing = require('opentracing'); ## 这里是最上层的引用// NOTE: the default OpenTracing tracer does not record any tracing information.// Replace this line with the tracer implementation of your choice.const tracer = new opentracing.Tracer(); ## 然后创建出Tracer 对象,用来创建Spanconst span = tracer.startSpan('http_request'); ## 第一个和TraceID一起被创建出来的Spanconst opts = {host : 'example.com',method: 'GET',port : '80',path: '/',};http.request(opts, res => {res.setEncoding('utf8');res.on('error', err => {// assuming no retries, mark the span as failedspan.setTag(opentracing.Tags.ERROR, true); ## Span可以打Tagspan.log({'event': 'error', 'error.object': err, 'message': err.message, 'stack': err.stack}); ## Span也可以写logspan.finish();});res.on('data', chunk => {span.log({'event': 'data_received', 'chunk_length': chunk.length});});res.on('end', () => {span.log({'event': 'request_end'});span.finish();});}).end();
然后这位客官就要问了:那之后的服务如何拿到这些信息啊(TraceID),又如何发起下一段Span呢?于是就有了下面一段代码,专门用来解析 Ctx 和开启新的 Span。
// Use the inbound HTTP request's headers as a text map carrier.var headersCarrier = inboundHTTPReq.headers;var wireCtx = Tracer.extract(Tracer.FORMAT_HTTP_HEADERS, headersCarrier);var serverSpan = Tracer.startSpan('...', { childOf : wireCtx });
肯定还有不甘心的小伙伴会问:那 FollowsFrom 的那些呢?总不会给你机会在 Http Headers 里读取信息吧,那些可是存在标准的 Kafka 等组件里的 message 呀。这可难不倒业界的大牛们,请看下面的代码2段注释,完美诠释了如何传递信息的。
// from https://github.com/opentracing-contrib/java-kafka-client// Register tracer with GlobalTracer:GlobalTracer.register(tracer);// Add TracingProducerInterceptor to sender properties:senderProps.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,TracingProducerInterceptor.class.getName());// Instantiate KafkaProducerKafkaProducer<Integer, String> producer = new KafkaProducer<>(senderProps);// Sendproducer.send(...);// Add TracingConsumerInterceptor to consumer properties:consumerProps.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,TracingConsumerInterceptor.class.getName());// Instantiate KafkaConsumerKafkaConsumer<Integer, String> consumer = new KafkaConsumer<>(consumerProps);//Subscribeconsumer.subscribe(Collections.singletonList("messages"));// Get recordsConsumerRecords<Integer, String> records = consumer.poll(1000);// To retrieve SpanContext from polled record (Consumer side)ConsumerRecord<Integer, String> record = ...SpanContext spanContext = TracingKafkaUtils.extractSpanContext(record.headers(), tracer);
具体来说就是 interceptor 在 Producer 发送的时候会创建 Span,并且把 SpanContext 塞进 record Headers 里面。
// Class TracingKafkaUtilspublic static void inject(SpanContext spanContext, Headers headers,Tracer tracer) {tracer.inject(spanContext, Format.Builtin.TEXT_MAP, new HeadersMapInjectAdapter(headers));}
然后等 Consumer 读取的时候关闭这个 Span,于是整个周期就完美结束了。
// TracingConsumerInterceptor<K, V> implements ConsumerInterceptor<K, V>@Overridepublic ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records) {for (ConsumerRecord<K, V> record : records) {TracingKafkaUtils.buildAndFinishChildSpan(record, GlobalTracer.get());}return records;}
如果还有小朋友问:那..其他组件呢?比如Pulsar这类的MQ呢?结论是都一样,大部分开源组件早已经认识到了 Tracing 的重要性,并且提供了类似的功能。比如 pulsar-tracing 这个项目,专门给 pulsar 做了一套集成 opentracing 的免费午餐。
// https://github.com/streamnative/pulsar-tracing// Instantiate Producer with tracing interceptor.Producer<String> producer = client.newProducer(Schema.STRING).intercept(new TracingProducerInterceptor()).topic("your-topic").create();// Send messages.producer.send("Hello OpenTracing!");// Instantiate Consumer with tracing interceptor.Consumer<String> consumer = client.newConsumer(Schema.STRING).topic("your-topic").intercept(new TracingConsumerInterceptor<>()).subscriptionName("your-sub").subscribe();// Receive messages.Message<String> message = consumer.receive();// To retrieve SpanContext from the message(Consumer side).SpanContext spanContext = TracingPulsarUtils.extractSpanContext(message, tracer);
如果说清楚了 OpenTracing 传递信息的逻辑,我们来看看,最后显示到界面的 Span 的信息都有啥?
如下图所示,各种信息提供给我们在遇到问题的时候进行分析和处理。大部分的信息都是经过很多年的沉淀之后,大家发现是解决问题所必须的。这些属性都被开源项目所采纳和集成。如果有些还没有集成进去,欢迎大家积极贡献。
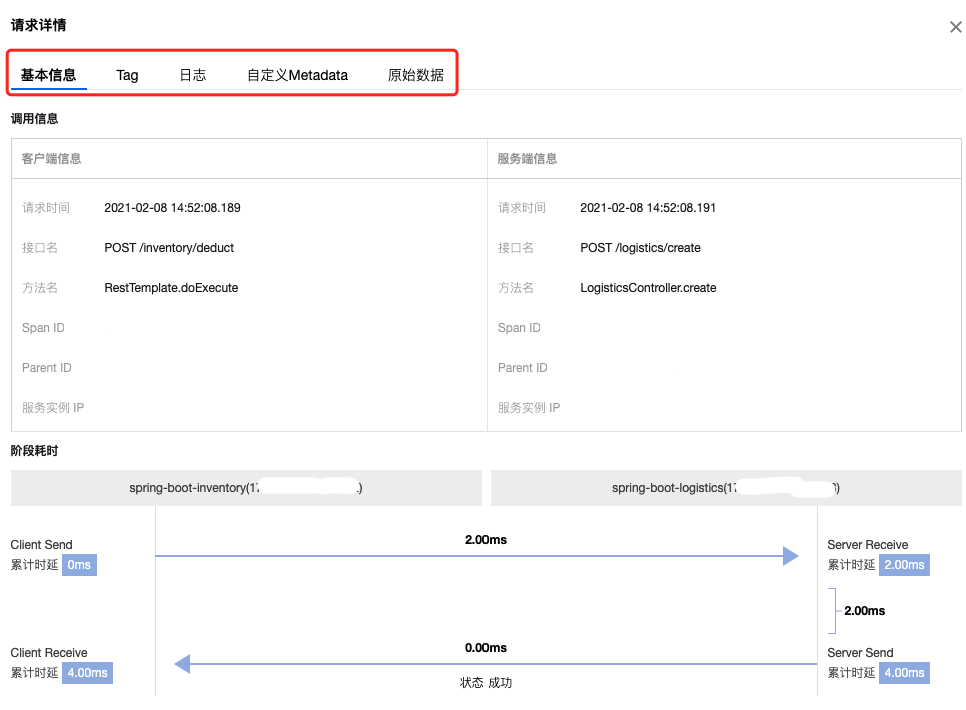
然后是原始信息
上面说过 Span 分三种(新的 TraceID 下的 Root Span,Child Span 和 FollowsFrom),下面的代码具体来演示,3中形式的 Span 都是怎么创建的(演示代码 javascript)
// Start a new (parentless) root Span:var parent = Tracer.startSpan('DoWork');// Start a new (child) Span:var child = Tracer.startSpan('load-from-db', {childOf: parent.context(),});// Start a new async (FollowsFrom) Span:var child = Tracer.startSpan('async-cache-write', {references: [opentracing.followsFrom(parent.context())],});
代码很简单,唯一就是 context 这部分需要额外说明。这里的 context 是 Span 里存的 SpanContext。这个组件存着 SpanID 和 TraceID,可以把整个调用链都串起来。
有了上面的了解,你已经基本了解怎么给自己的微服务(们)搞一搞 Tracing了~ 还等什么,开始写第一行代码吧?哦,不对!有些语言其实不需要写代码,比如 Java,比如 Nodejs,还比如 Python,都是利用 agent 的能力监听 Runtime 自动生成 Tracing 逻辑的。
我来整理一下需要和不需要写代码的东东们:
Skywalking:
https://github.com/apache/skywalking/blob/master/docs/en/setup/README.md

Agent 也不都一样,Java 是传递参数 javaagent,而 nodejs 和 python 需要启动一个额外的 process 作为 agent。有兴趣就点击进文档里看看吧,很有意思的。
# e.g. skywalking python agentfrom skywalking import agent, configconfig.init(collector='XXX.X.X.X:XXXXX', service='your awesome service')agent.start()
Openzipkin:
https://zipkin.io/pages/tracers_instrumentation
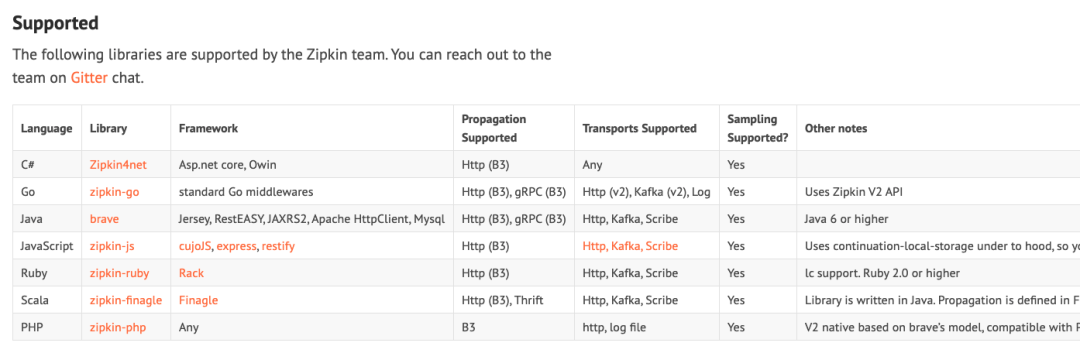
当前 Zipkin 主流的接入方式还是用语言和框架(framework)的 SDK 做集成,官网没有明确支持的 agent ,而 jaegertracing 则在 0.8 版本之后提供了一个标准的 agent 组件,作为无侵入的标准解决方案。什么时候需要用,什么时候不需要,可以看官网的文档:
https://www.jaegertracing.io/docs/1.21/faq/#do-i-need-to-run-jaeger-agent
总的来说,agent 避免了在程序里设置 tracing 相关的配置,避免了产生过多的网络链接,还可以自主抓取一些环境信息(zone/region 等)这些都是选择 agent 而不写代码的原因。
是不是突然觉得不写代码变得光明正大了呢?
往期

扫描下方二维码关注本公众号,
了解更多微服务、消息队列的相关信息!
解锁超多鹅厂周边!
 点亮在看,你最好看
点亮在看,你最好看
本文分享自微信公众号 - 腾讯云中间件(gh_6ea1bc2dd5fd)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK