

Kafka 源码阅读笔记
source link: https://zhuanlan.zhihu.com/p/358918515
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Kafka 源码阅读笔记
作者:guolonglin,腾讯 IEG 后台开发工程师
一、Kafka 总览
1)kafka 集群是由 broker 组成,每个 borker 拥有一个 controller,基于 zookeeper 做集群 controller leader 选举,以及存储集群核心元数据,leader controller 负责管理整个集群;
2)以 Topic->partition-> replication 来存储生产者数据,每个 partition 为一个 Log,log 分段存储于文件中;
3)kafka 集群管理消费者信息和消费者消费记录,这些信息也以内部 topic 形式存储;
4)Kafka Broker 结构。
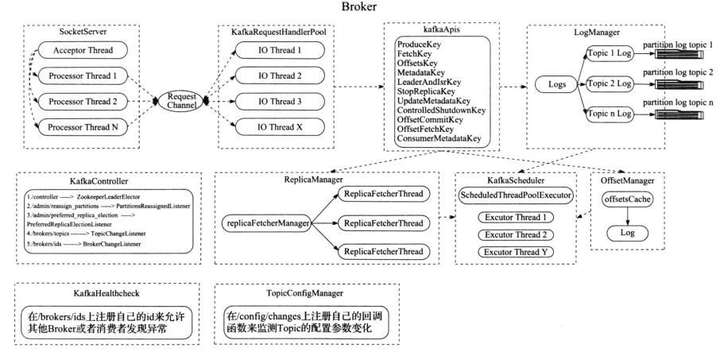
二、Broker 结构
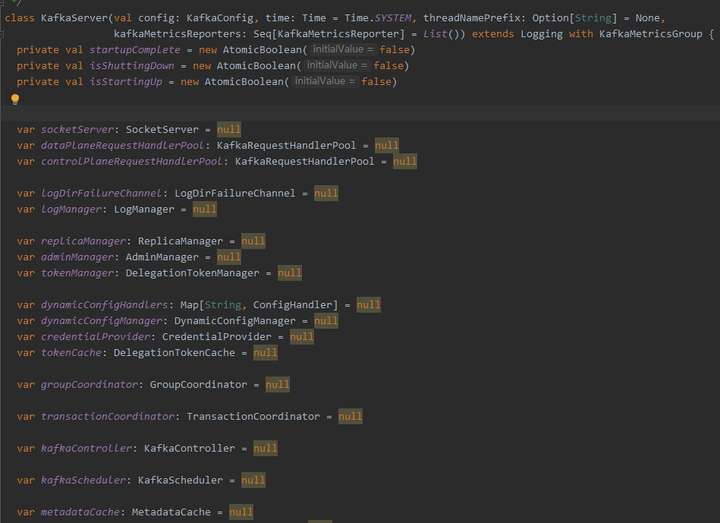
2)每个 borker 进程,都包含各个管理器,如 socketServer 网络处理,replicaManager 副本管理器,kafkaController 集群管理器,groupCoordinator 消息者数据管理器,LogManager 日志数据管理器,kafkaScheduler 定时器,zkClient 与 zookeeper 通信管理器,transactionCoordinator 事务协调器。
三、通信框架
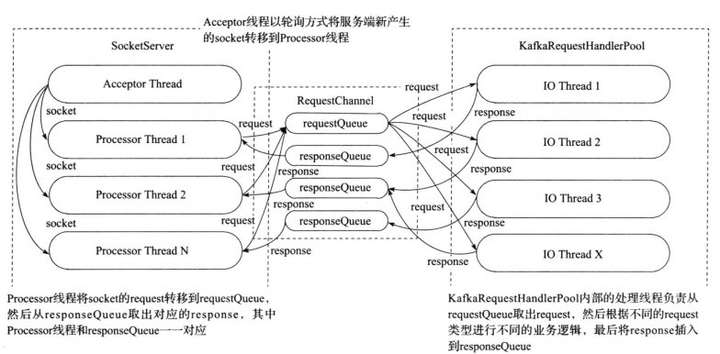
2)socketserver 会启动一个 acceptor 线程,用于接收和创建新 socket,并轮询安排给 processor thread 来处理后续的数据 io;
3)processor 接收到数据后包装成 request 请求放入单个 requestQueue 队列,并由多个 io 逻辑处理 thread 从 requestQueue 中取 request 处理;
4)根据 request 类型调用 kafkaapi 完成处理;
6)处理完请求后,封装成 reponse,根据 ProcessorID 放入对应的 responseQueue 由对应的 processor 线程完成回复。
四、log 结构
1)Topic、partition 和 replica 关系
3)每个 topic 由很多个 partition 组成,由 key hash 值分配到不同的 partition,每个 partition 拥有多个副本 replica 做主从,确保数据的安全性。
4)每个 partition 或者 replica 由 log 存储数据,log 由 logsegment 组成,每个 logsegment 由索引文件和数据文件组成。
7)当在 Log 中需要查找获取一条消息时,会根据偏移首先定位到处于哪个 logsegment 文件,再根据索引文件定位,Logsegment 是由跳跃表组成的,便于搜索,再从数据文件读取消息;
9)索引文件由 K,V 组成,K 是相对文件中第几条消息,V 是文件中的绝对位置,索引文件可以用来做二分查找,从索引文件中找到位置之后,再从数据文件中顺序查找,具体那条消息数据,为了避免索引文件太大,会相隔一定字节才写入一条索引;
10)每个 partition 会有多个 replica 进行同步,一个 Leader 多个 follower,这些副本主从地位是由 leader controller 负责处理,只有 leader replica 才能处理请求,其它 follower 同步数据。
五、Controller
1)每个 broker 都拥有一个 kafkacontroller,controller 主要负责管理整个集群,但是每个集群中都只有一个 leader controller 有资格来管理集群;
2)Leader controller 是借助 zookeeper 来选择的,每个 controller 初始化时都会向 zookeeper 注册竞争成为 leader 的路径的监听,第一个成功写入 zookeeper 的 controller 将会成为 leader,其它 controller 就会收到新 leader 的通知,将自己设为 follower;
3)当 controller 成为 leader 时,会向 zookeeper 注册相关监听; 4)
5)这些监听集群数据状态的变化,如 增加 topic partition replica 等,当监听到数据发生变化,leaderController 就会得到通知并处理,处理完成后会同步相关数据给其它 followerController;
6)controller 是以单工作线程形式运行的,其它请求通过封装为 job 投递到 controller 处理线程; 7)
8)borker 上下线、副本增加重分配、topic 增加等,通过 zookeeper 通知并创建 job 投入 job 队列等待工作线程处理;
9)集群所有的元数据是存放在 zookeeper 上,当 zookeeper 数据发生变化时,通过通知到 leaderController,controller 处理数据,并在内存中保存一份副本,做差值处理。
六、replica 管理
1)所有 partition 都有多个 replica 来管理,这样使数据更安全,不容易丢失;
2)replica 的 leader follower 地位是由 leaderController 来管理的;
3)replica 有三种类型:无效的、已分配的(正在同步但是还没达到一致状态)和在线副本(正常同步的);
4)replica 数据的同步是由 replicaManager 副本管理器来处理的,管理器会开启副本同步线程去 leader replica 抓取数据;
5)replica 下线时,leaderController 会收到 zookeeper 通知后会处理,如果是 leader replica 下线,则会重新选举,根据不同状态用不同选举策略选出新 Leader;
6)选 leader 有可能来自 replica 下线、需要改变 leader 或者为了负载均衡进行重分配。
七、groupCoordinator 消费数据管理
2)GroupCoordinator 提供访问消费者数据的接口,GroupMetadataManager 负责管理消费者组的数据,GroupMetadata 保存消费者组的数据,MemberMetadata 保存组里每个成员的数据;
3)Kafka 提供了两种存储消费者数据方式,一种是保存在 zookeeper 上,另一种是保存在 kafka log 系统中,由于 zookeeper 的频繁写性能不是很好,所以 kafka 提供保存的选择,也是默认选择;
4)用户需要访问消费者数据时,会通过 kafka client,随便找到一个比较空闲的 borker 通过其 GroupCoordinator,找到其 leader 副本所以在的地址,并返回给 client 去连接,只有 leader replica 才提供服务;
5)消费者数据是通过内置的一个写死的 topic 来管理,通过用户的(topic,partition,消费者组)做为内置的 topic 分区 hash 来保存到 log 中;
6)如用户加入、新增、删除消费者组信息时,会将创建消息保存致 Log 中,并在内存中运行生成数据存放于 2)中的数据结构。
八、生产者发送数据
1)生产者通过 topic 和 key 决定往哪个 partition 写入数据;
2)生产者需要携带 ack 用来决定应该什么时候回复,分别有 0,1,-1,当为 0 时说明不需要回复,当为 1 时表示集群接收了就回复,当为-1 时需要所有 isr(正常同步的)都接收确认了才能回复,接收数据后,会将这条消息存入延迟执行队列,当检测其它 isr 来抓取数据时,会更新并检查是否可以回复生产者。
九、transactionCoordinator 事务处理
1)kafka 支持事务操作,并支持消费者设定 read_commited 和 read_uncommited 读取级别;
2)用户提交的事务 log 会保存在内置写死的 topic 中,跟消费者数据相似的方法,依赖 replica 保证数据安全,执行的操作也会正常保存进消息 log(非事务 log),不过会有标志标示消息状态,如正在事务中还没提交,或者已经废弃还是提交了;
3)消费者数据中会记录当前已经完成事务处理的 Log 最大偏移量叫 LSO,即此偏移量前的数据要么是已经事务提交的,要么是事务放弃的;
4)通过 LSO 保证读已提交的消费者不会读到还没提交的事务数据;
5)kafka 当用户回滚事务时,会记录回滚信息至放弃 Log 跟事务 Log 一样由 replica 管理,这里面记录的信息是一个 log 偏移区域内的 produceid 集合(由 kafka 生成的全局唯一 ID),在消费者抓取数据时,携带过去,消费者可以利用这个数据过滤掉放弃的事务;
6)当用户提交事务时,事务协调器就会通知各个对应的 topic 所在的 borker 提交数据。
3月25日周四晚19:30 关注腾讯技术工程直播:
更多干货尽在腾讯技术,欢迎关注官方公众号:腾讯技术工程,交流群已建立,交流讨论可加QQ 群:160315980(备注腾讯技术) 。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK