
7

Lucene系列(12)索引格式之nvm文件
source link: http://huyan.couplecoders.tech/lucene/%E6%90%9C%E7%B4%A2%EF%BC%8C%E7%B4%A2%E5%BC%95%E6%96%87%E4%BB%B6/2021/03/17/lucene%E7%B3%BB%E5%88%97(12)%E7%B4%A2%E5%BC%95%E6%A0%BC%E5%BC%8F%E4%B9%8Bnvm%E6%96%87%E4%BB%B6/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
本文使用 Lucene 代码版本:8.7.0
本文学习一下。nvm 文件的格式与内容。
nvm 与 nvd 文件配合存储了索引中的标准化相关信息。其中 nvm 存储了元数据,nvd 文件存储了标准化后的值及相关 docId 信息。
.pay 文件整体结构
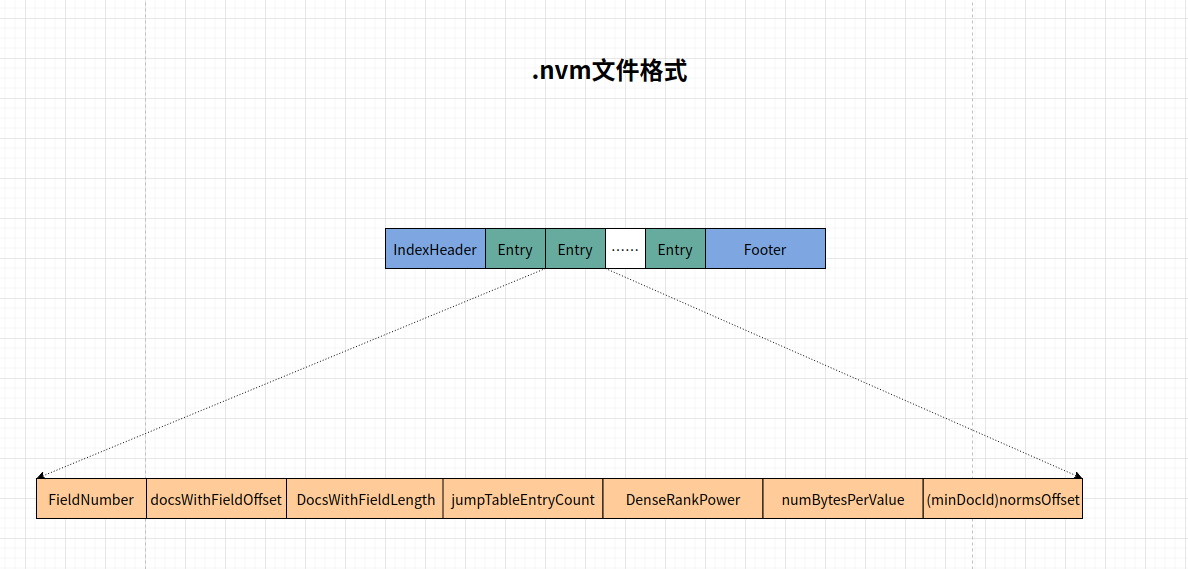
字段解释:
- Entry: 一个 field 的标准化信息
- FileNumber: 域的编号
- docsWithFieldOffset: 这个域有值的所有 docId, 在 nvd 文件中开始存储的文件指针,注意有两个特殊值。-1 代表每个文档在这个域都有值,-2 代表所有文档在这个域都没有值。
- docsWithFieldLength: 这个域有值的所有 docId,存储在 nvd 文件中的长度。如果 docsWithFieldOffset 为-1/-2 两个特殊值,那么这个值为 0.
- jumpTableEntryCount: 把这个域有值的所有 docId 存储为了多少个块。
- DenseRankPower: 存储所有的 docId 的时候,使用密集策略的话,存储的块的大小的是 2 的多少次幂。
- numBytesPerValue: 每一个值占用的字节数量,因此采用的增量编码,所以使用 docId 的最大最小值的差值,来决定使用 byte, short, int, long 的哪种。
- minDocId: 如果每一个值占用的字节数量为 0, 说明所有的 docId 是一样,也就是说只有一个 doc。在这里记录最小值,就意味着存储了所有的 docID.
- normsOffset: 如果不是所有 docId 都一样,也就是说有多个 docId。那么这里存一下所有的标准化值在 nvd 文件中存储的起始文件位置。
相关写入代码分析
nvm 及 nvd 文件的写入全部在org.apache.lucene.codecs.lucene80.Lucene80NormsConsumer类中。
在该类的构造函数中,进行了初始化及 Header 的写入。

addNormsField
在org.apache.lucene.codecs.lucene80.Lucene80NormsConsumer#addNormsField中进行了全部的内容写入。
具体内容都在注释里,不再赘述。
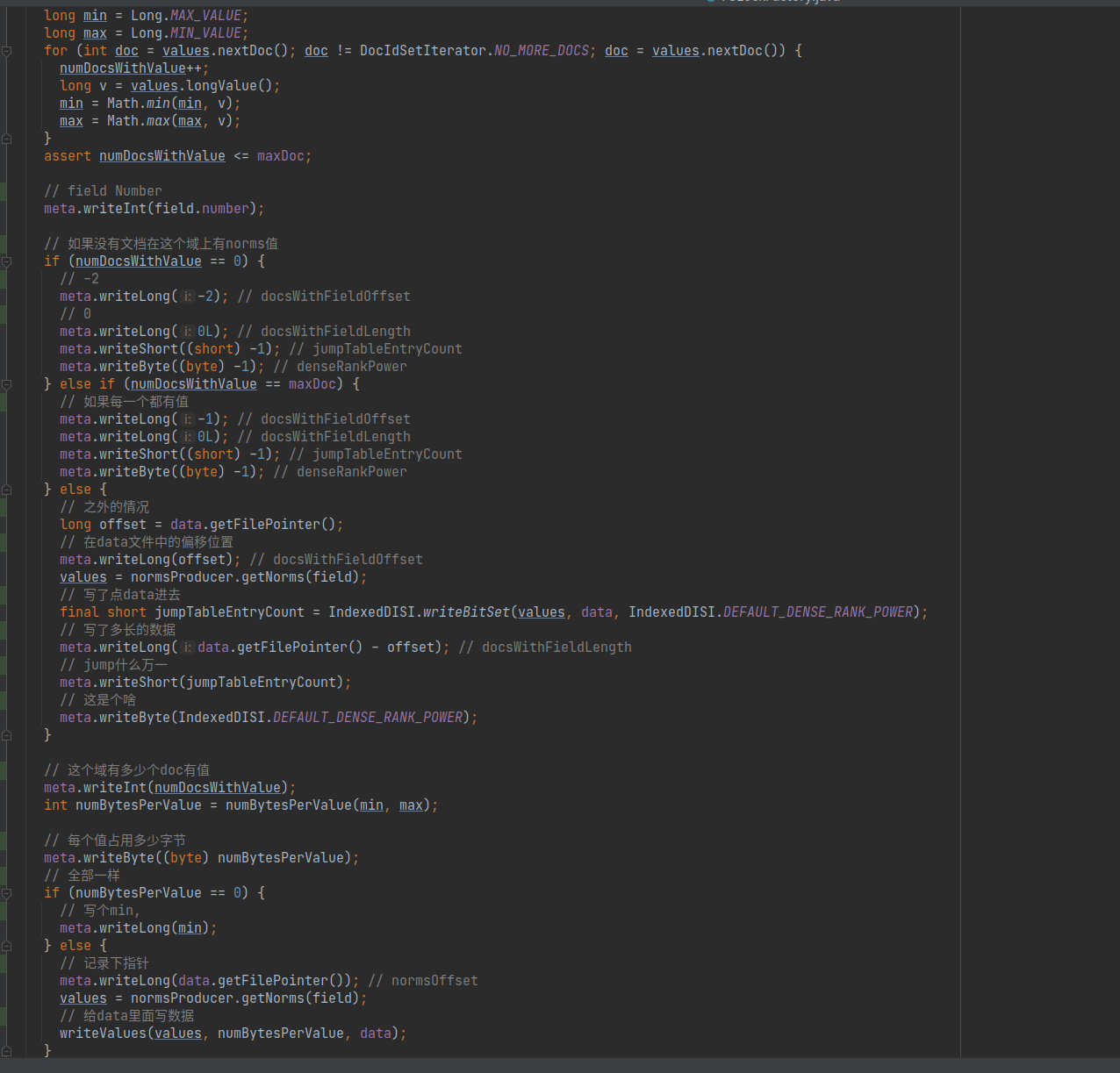
比较简单,罗列一下。
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。
也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。

以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
联系邮箱:[email protected]
更多学习笔记见个人博客或关注微信公众号 < 呼延十 >——>呼延十
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK