

硬核!一文学完Flink流计算常用算子(Flink算子大全)
source link: https://my.oschina.net/u/4789384/blog/4982721
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

直入正题!
Flink和Spark类似,也是一种一站式处理的框架;既可以进行批处理(DataSet),也可以进行实时处理(DataStream)。
所以下面将Flink的算子分为两大类:一类是DataSet,一类是DataStream。
DataSet
一、Source算子
1. fromCollection
fromCollection:从本地集合读取数据
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[String] = env.fromCollection(
List("1,张三", "2,李四", "3,王五", "4,赵六")
)
2. readTextFile
readTextFile:从文件中读取:
val textDataSet: DataSet[String] = env.readTextFile("/data/a.txt")
3. readTextFile:遍历目录
readTextFile可以对一个文件目录内的所有文件,包括所有子目录中的所有文件的遍历访问方式:
val parameters = new Configuration
// recursive.file.enumeration 开启递归
parameters.setBoolean("recursive.file.enumeration", true)
val file = env.readTextFile("/data").withParameters(parameters)
4. readTextFile:读取压缩文件
对于以下压缩类型,不需要指定任何额外的inputformat方法,flink可以自动识别并且解压。但是,压缩文件可能不会并行读取,可能是顺序读取的,这样可能会影响作业的可伸缩性。
压缩方法 文件扩展名 是否可并行读取 DEFLATE .deflate no GZip .gz .gzip no Bzip2 .bz2 no XZ .xz noval file = env.readTextFile("/data/file.gz")
二、Transform转换算子
因为Transform算子基于Source算子操作,所以首先构建Flink执行环境及Source算子,后续Transform算子操作基于此:
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[String] = env.fromCollection(
List("张三,1", "李四,2", "王五,3", "张三,4")
)
1. map
将DataSet中的每一个元素转换为另外一个元素:
// 使用map将List转换为一个Scala的样例类
case class User(name: String, id: String)
val userDataSet: DataSet[User] = textDataSet.map {
text =>
val fieldArr = text.split(",")
User(fieldArr(0), fieldArr(1))
}
userDataSet.print()
2. flatMap
将DataSet中的每一个元素转换为0...n个元素:
// 使用flatMap操作,将集合中的数据:
// 根据第一个元素,进行分组
// 根据第二个元素,进行聚合求值
val result = textDataSet.flatMap(line => line)
.groupBy(0) // 根据第一个元素,进行分组
.sum(1) // 根据第二个元素,进行聚合求值
result.print()
3. mapPartition
将一个分区中的元素转换为另一个元素:
// 使用mapPartition操作,将List转换为一个scala的样例类
case class User(name: String, id: String)
val result: DataSet[User] = textDataSet.mapPartition(line => {
line.map(index => User(index._1, index._2))
})
result.print()
4. filter
过滤出来一些符合条件的元素,返回boolean值为true的元素:
val source: DataSet[String] = env.fromElements("java", "scala", "java")
val filter:DataSet[String] = source.filter(line => line.contains("java"))//过滤出带java的数据
filter.print()
5. reduce
可以对一个dataset或者一个group来进行聚合计算,最终聚合成一个元素:
// 使用 fromElements 构建数据源
val source = env.fromElements(("java", 1), ("scala", 1), ("java", 1))
// 使用map转换成DataSet元组
val mapData: DataSet[(String, Int)] = source.map(line => line)
// 根据首个元素分组
val groupData = mapData.groupBy(_._1)
// 使用reduce聚合
val reduceData = groupData.reduce((x, y) => (x._1, x._2 + y._2))
// 打印测试
reduceData.print()
6. reduceGroup
将一个dataset或者一个group聚合成一个或多个元素。
reduceGroup是reduce的一种优化方案;
它会先分组reduce,然后在做整体的reduce;这样做的好处就是可以减少网络IO:
// 使用 fromElements 构建数据源
val source: DataSet[(String, Int)] = env.fromElements(("java", 1), ("scala", 1), ("java", 1))
// 根据首个元素分组
val groupData = source.groupBy(_._1)
// 使用reduceGroup聚合
val result: DataSet[(String, Int)] = groupData.reduceGroup {
(in: Iterator[(String, Int)], out: Collector[(String, Int)]) =>
val tuple = in.reduce((x, y) => (x._1, x._2 + y._2))
out.collect(tuple)
}
// 打印测试
result.print()
7. minBy和maxBy
选择具有最小值或最大值的元素:
// 使用minBy操作,求List中每个人的最小值
// List("张三,1", "李四,2", "王五,3", "张三,4")
case class User(name: String, id: String)
// 将List转换为一个scala的样例类
val text: DataSet[User] = textDataSet.mapPartition(line => {
line.map(index => User(index._1, index._2))
})
val result = text
.groupBy(0) // 按照姓名分组
.minBy(1) // 每个人的最小值
8. Aggregate
在数据集上进行聚合求最值(最大值、最小值):
val data = new mutable.MutableList[(Int, String, Double)]
data.+=((1, "yuwen", 89.0))
data.+=((2, "shuxue", 92.2))
data.+=((3, "yuwen", 89.99))
// 使用 fromElements 构建数据源
val input: DataSet[(Int, String, Double)] = env.fromCollection(data)
// 使用group执行分组操作
val value = input.groupBy(1)
// 使用aggregate求最大值元素
.aggregate(Aggregations.MAX, 2)
// 打印测试
value.print()
Aggregate只能作用于元组上
注意:
要使用aggregate,只能使用字段索引名或索引名称来进行分组groupBy(0),否则会报一下错误:
Exception in thread "main" java.lang.UnsupportedOperationException: Aggregate does not support grouping with KeySelector functions, yet.
9. distinct
去除重复的数据:
// 数据源使用上一题的
// 使用distinct操作,根据科目去除集合中重复的元组数据
val value: DataSet[(Int, String, Double)] = input.distinct(1)
value.print()
10. first
取前N个数:
input.first(2) // 取前两个数
11. join
将两个DataSet按照一定条件连接到一起,形成新的DataSet:
// s1 和 s2 数据集格式如下:
// DataSet[(Int, String,String, Double)]
val joinData = s1.join(s2) // s1数据集 join s2数据集
.where(0).equalTo(0) { // join的条件
(s1, s2) => (s1._1, s1._2, s2._2, s1._3)
}
12. leftOuterJoin
左外连接,左边的Dataset中的每一个元素,去连接右边的元素
此外还有:
rightOuterJoin:右外连接,左边的Dataset中的每一个元素,去连接左边的元素
fullOuterJoin:全外连接,左右两边的元素,全部连接
下面以 leftOuterJoin 进行示例:
val data1 = ListBuffer[Tuple2[Int,String]]()
data1.append((1,"zhangsan"))
data1.append((2,"lisi"))
data1.append((3,"wangwu"))
data1.append((4,"zhaoliu"))
val data2 = ListBuffer[Tuple2[Int,String]]()
data2.append((1,"beijing"))
data2.append((2,"shanghai"))
data2.append((4,"guangzhou"))
val text1 = env.fromCollection(data1)
val text2 = env.fromCollection(data2)
text1.leftOuterJoin(text2).where(0).equalTo(0).apply((first,second)=>{
if(second==null){
(first._1,first._2,"null")
}else{
(first._1,first._2,second._2)
}
}).print()
13. cross
交叉操作,通过形成这个数据集和其他数据集的笛卡尔积,创建一个新的数据集
和join类似,但是这种交叉操作会产生笛卡尔积,在数据比较大的时候,是非常消耗内存的操作:
val cross = input1.cross(input2){
(input1 , input2) => (input1._1,input1._2,input1._3,input2._2)
}
cross.print()
14. union
联合操作,创建包含来自该数据集和其他数据集的元素的新数据集,不会去重:
val unionData: DataSet[String] = elements1.union(elements2).union(elements3)
// 去除重复数据
val value = unionData.distinct(line => line)
15. rebalance
Flink也有数据倾斜的时候,比如当前有数据量大概10亿条数据需要处理,在处理过程中可能会发生如图所示的状况:
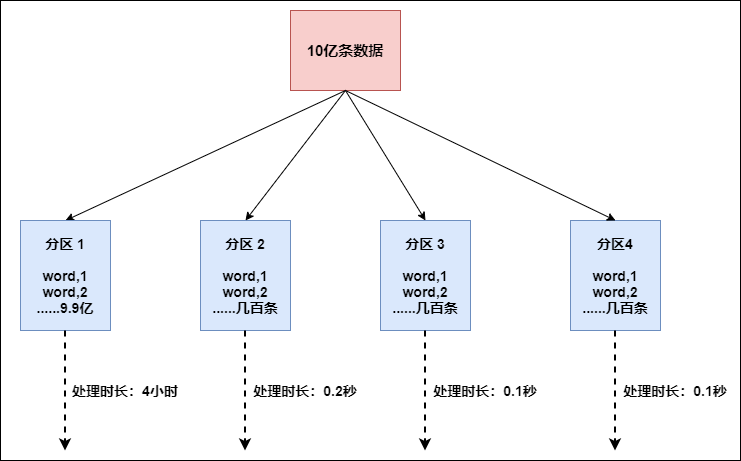
这个时候本来总体数据量只需要10分钟解决的问题,出现了数据倾斜,机器1上的任务需要4个小时才能完成,那么其他3台机器执行完毕也要等待机器1执行完毕后才算整体将任务完成;所以在实际的工作中,出现这种情况比较好的解决方案就是接下来要介绍的—rebalance(内部使用round robin方法将数据均匀打散。这对于数据倾斜时是很好的选择。)
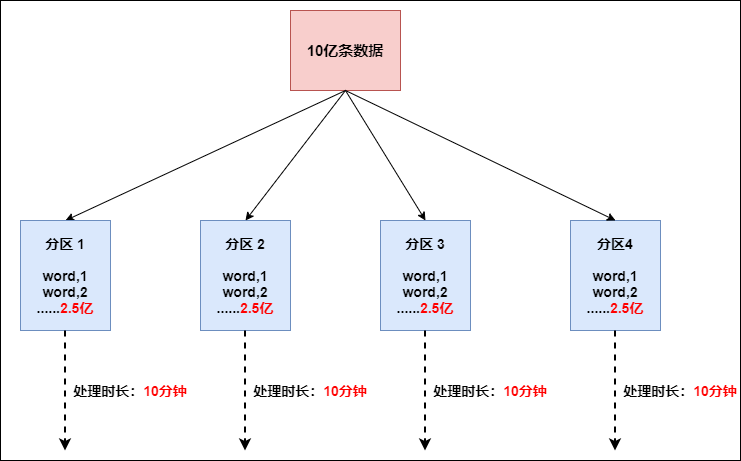
// 使用rebalance操作,避免数据倾斜
val rebalance = filterData.rebalance()
16. partitionByHash
按照指定的key进行hash分区:
val data = new mutable.MutableList[(Int, Long, String)]
data.+=((1, 1L, "Hi"))
data.+=((2, 2L, "Hello"))
data.+=((3, 2L, "Hello world"))
val collection = env.fromCollection(data)
val unique = collection.partitionByHash(1).mapPartition{
line =>
line.map(x => (x._1 , x._2 , x._3))
}
unique.writeAsText("hashPartition", WriteMode.NO_OVERWRITE)
env.execute()
17. partitionByRange
根据指定的key对数据集进行范围分区:
val data = new mutable.MutableList[(Int, Long, String)]
data.+=((1, 1L, "Hi"))
data.+=((2, 2L, "Hello"))
data.+=((3, 2L, "Hello world"))
data.+=((4, 3L, "Hello world, how are you?"))
val collection = env.fromCollection(data)
val unique = collection.partitionByRange(x => x._1).mapPartition(line => line.map{
x=>
(x._1 , x._2 , x._3)
})
unique.writeAsText("rangePartition", WriteMode.OVERWRITE)
env.execute()
18. sortPartition
根据指定的字段值进行分区的排序:
val data = new mutable.MutableList[(Int, Long, String)]
data.+=((1, 1L, "Hi"))
data.+=((2, 2L, "Hello"))
data.+=((3, 2L, "Hello world"))
data.+=((4, 3L, "Hello world, how are you?"))
val ds = env.fromCollection(data)
val result = ds
.map { x => x }.setParallelism(2)
.sortPartition(1, Order.DESCENDING)//第一个参数代表按照哪个字段进行分区
.mapPartition(line => line)
.collect()
println(result)
三、Sink算子
1. collect
将数据输出到本地集合:
result.collect()
2. writeAsText
将数据输出到文件
Flink支持多种存储设备上的文件,包括本地文件,hdfs文件等
Flink支持多种文件的存储格式,包括text文件,CSV文件等
// 将数据写入本地文件
result.writeAsText("/data/a", WriteMode.OVERWRITE)
// 将数据写入HDFS
result.writeAsText("hdfs://node01:9000/data/a", WriteMode.OVERWRITE)
DataStream
和DataSet一样,DataStream也包括一系列的Transformation操作。
一、Source算子
Flink可以使用 StreamExecutionEnvironment.addSource(source) 来为我们的程序添加数据来源。
Flink 已经提供了若干实现好了的 source functions,当然我们也可以通过实现 SourceFunction 来自定义非并行的source或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source。
Flink在流处理上的source和在批处理上的source基本一致。大致有4大类:
- 基于 本地集合的source(Collection-based-source)
- 基于 文件的source(File-based-source)- 读取文本文件,即符合 TextInputFormat 规范的文件,并将其作为字符串返回
- 基于 网络套接字的source(Socket-based-source)- 从 socket 读取。元素可以用分隔符切分。
- 自定义的source(Custom-source)
下面使用addSource将Kafka数据写入Flink为例:
如果需要外部数据源对接,可使用addSource,如将Kafka数据写入Flink, 先引入依赖:
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka-0.11 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.10.0</version>
</dependency>
将Kafka数据写入Flink:
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
val source = env.addSource(new FlinkKafkaConsumer011[String]("sensor", new SimpleStringSchema(), properties))
基于网络套接字的:
val source = env.socketTextStream("IP", PORT)
二、Transform转换算子
1. map
将DataSet中的每一个元素转换为另外一个元素:
dataStream.map { x => x * 2 }
2. FlatMap
采用一个数据元并生成零个,一个或多个数据元。将句子分割为单词的flatmap函数:
dataStream.flatMap { str => str.split(" ") }
3. Filter
计算每个数据元的布尔函数,并保存函数返回true的数据元。过滤掉零值的过滤器:
dataStream.filter { _ != 0 }
4. KeyBy
逻辑上将流分区为不相交的分区。具有相同Keys的所有记录都分配给同一分区。在内部,keyBy()是使用散列分区实现的。指定键有不同的方法。
此转换返回KeyedStream,其中包括使用被Keys化状态所需的KeyedStream:
dataStream.keyBy(0)
5. Reduce
被Keys化数据流上的“滚动”Reduce。将当前数据元与最后一个Reduce的值组合并发出新值:
keyedStream.reduce { _ + _ }
6. Fold
具有初始值的被Keys化数据流上的“滚动”折叠。将当前数据元与最后折叠的值组合并发出新值:
val result: DataStream[String] = keyedStream.fold("start")((str, i) => { str + "-" + i })
// 解释:当上述代码应用于序列(1,2,3,4,5)时,输出结果“start-1”,“start-1-2”,“start-1-2-3”,...
7. Aggregations
在被Keys化数据流上滚动聚合。min和minBy之间的差异是min返回最小值,而minBy返回该字段中具有最小值的数据元(max和maxBy相同):
keyedStream.sum(0);
keyedStream.min(0);
keyedStream.max(0);
keyedStream.minBy(0);
keyedStream.maxBy(0);
8. Window
可以在已经分区的KeyedStream上定义Windows。Windows根据某些特征(例如,在最后5秒内到达的数据)对每个Keys中的数据进行分组。这里不再对窗口进行详解,有关窗口的完整说明,请查看这篇文章:Flink 中极其重要的 Time 与 Window 详细解析
dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5)));
9. WindowAll
Windows可以在常规DataStream上定义。Windows根据某些特征(例如,在最后5秒内到达的数据)对所有流事件进行分组。
注意:在许多情况下,这是非并行转换。所有记录将收集在windowAll 算子的一个任务中。
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))
10. Window Apply
将一般函数应用于整个窗口。
注意:如果您正在使用windowAll转换,则需要使用AllWindowFunction。
下面是一个手动求和窗口数据元的函数:
windowedStream.apply { WindowFunction }
allWindowedStream.apply { AllWindowFunction }
11. Window Reduce
将函数缩减函数应用于窗口并返回缩小的值:
windowedStream.reduce { _ + _ }
12. Window Fold
将函数折叠函数应用于窗口并返回折叠值:
val result: DataStream[String] = windowedStream.fold("start", (str, i) => { str + "-" + i })
// 上述代码应用于序列(1,2,3,4,5)时,将序列折叠为字符串“start-1-2-3-4-5”
13. Union
两个或多个数据流的联合,创建包含来自所有流的所有数据元的新流。注意:如果将数据流与自身联合,则会在结果流中获取两次数据元:
dataStream.union(otherStream1, otherStream2, ...)
14. Window Join
在给定Keys和公共窗口上连接两个数据流:
dataStream.join(otherStream)
.where(<key selector>).equalTo(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new JoinFunction () {...})
15. Interval Join
在给定的时间间隔内使用公共Keys关联两个被Key化的数据流的两个数据元e1和e2,以便e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound
am.intervalJoin(otherKeyedStream)
.between(Time.milliseconds(-2), Time.milliseconds(2))
.upperBoundExclusive(true)
.lowerBoundExclusive(true)
.process(new IntervalJoinFunction() {...})
16. Window CoGroup
在给定Keys和公共窗口上对两个数据流进行Cogroup:
dataStream.coGroup(otherStream)
.where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new CoGroupFunction () {...})
17. Connect
“连接”两个保存其类型的数据流。连接允许两个流之间的共享状态:
DataStream<Integer> someStream = ... DataStream<String> otherStream = ... ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream)
// ... 代表省略中间操作
18. CoMap,CoFlatMap
类似于连接数据流上的map和flatMap:
connectedStreams.map(
(_ : Int) => true,
(_ : String) => false)connectedStreams.flatMap(
(_ : Int) => true,
(_ : String) => false)
19. Split
根据某些标准将流拆分为两个或更多个流:
val split = someDataStream.split(
(num: Int) =>
(num % 2) match {
case 0 => List("even")
case 1 => List("odd")
})
20. Select
从拆分流中选择一个或多个流:
SplitStream<Integer> split;DataStream<Integer> even = split.select("even");DataStream<Integer> odd = split.select("odd");DataStream<Integer> all = split.select("even","odd")
三、Sink算子
支持将数据输出到:
- 本地文件(参考批处理)
- 本地集合(参考批处理)
- HDFS(参考批处理)
除此之外,还支持:
- sink到kafka
- sink到mysql
- sink到redis
下面以sink到kafka为例:
val sinkTopic = "test"
//样例类
case class Student(id: Int, name: String, addr: String, sex: String)
val mapper: ObjectMapper = new ObjectMapper()
//将对象转换成字符串
def toJsonString(T: Object): String = {
mapper.registerModule(DefaultScalaModule)
mapper.writeValueAsString(T)
}
def main(args: Array[String]): Unit = {
//1.创建流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.准备数据
val dataStream: DataStream[Student] = env.fromElements(
Student(8, "xiaoming", "beijing biejing", "female")
)
//将student转换成字符串
val studentStream: DataStream[String] = dataStream.map(student =>
toJsonString(student) // 这里需要显示SerializerFeature中的某一个,否则会报同时匹配两个方法的错误
)
//studentStream.print()
val prop = new Properties()
prop.setProperty("bootstrap.servers", "node01:9092")
val myProducer = new FlinkKafkaProducer011[String](sinkTopic, new KeyedSerializationSchemaWrapper[String](new SimpleStringSchema()), prop)
studentStream.addSink(myProducer)
studentStream.print()
env.execute("Flink add sink")
}
--end--
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK