

Lucene系列(六)索引格式之fdt文件
source link: http://huyan.couplecoders.tech/lucene/%E6%90%9C%E7%B4%A2%EF%BC%8C%E7%B4%A2%E5%BC%95%E6%96%87%E4%BB%B6/2021/01/04/lucene%E7%B3%BB%E5%88%97(%E5%85%AD)%E7%B4%A2%E5%BC%95%E6%A0%BC%E5%BC%8F%E4%B9%8Bfdt%E6%96%87%E4%BB%B6/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
本文介绍一下。fdt 文件的存储格式。
fdt 文件,以正排的方式,存储了 field 的原始真实数据。也就是说,你添加到所有中的所有 field 内容。都会存储在此文件中。
.fdt 文件整体结构
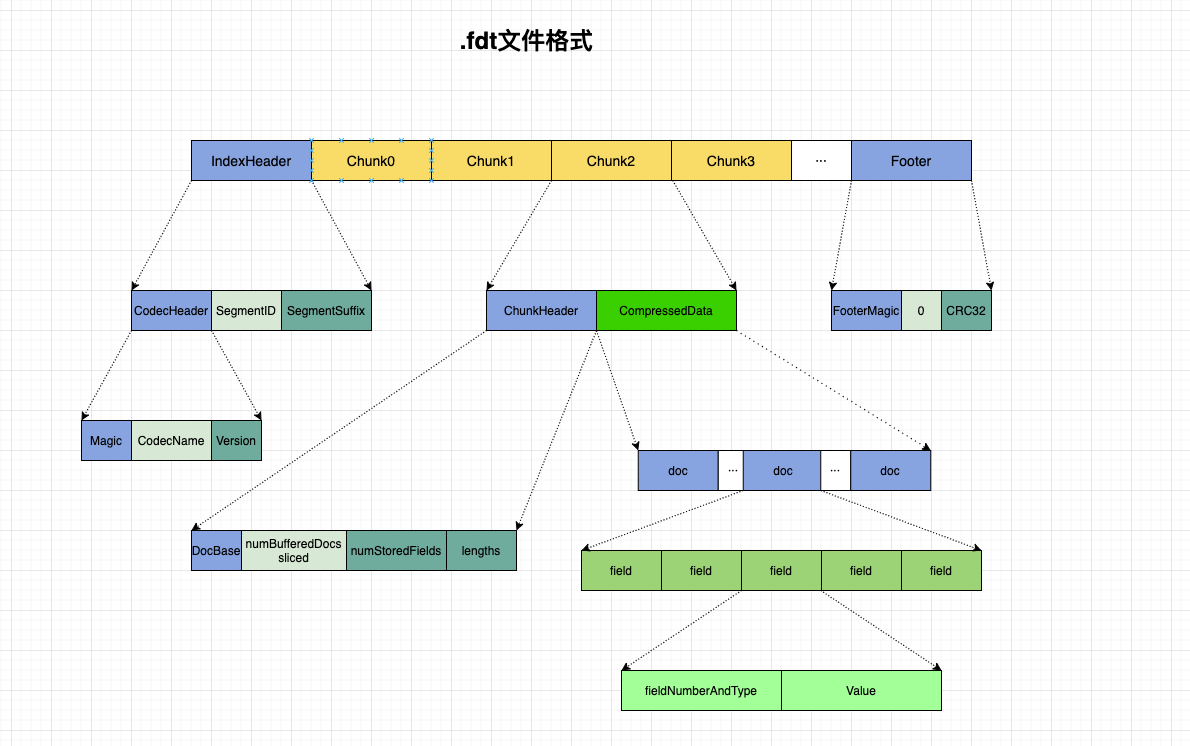
其中Header **和 Footer**, 与其中文件并无差别。详细字段解释可以看 Lucene 系列(二)索引格式之 fdm 文件
这里主要看一下以 chunk 为单位进行存储的 field 信息。也就是图中的这一部。
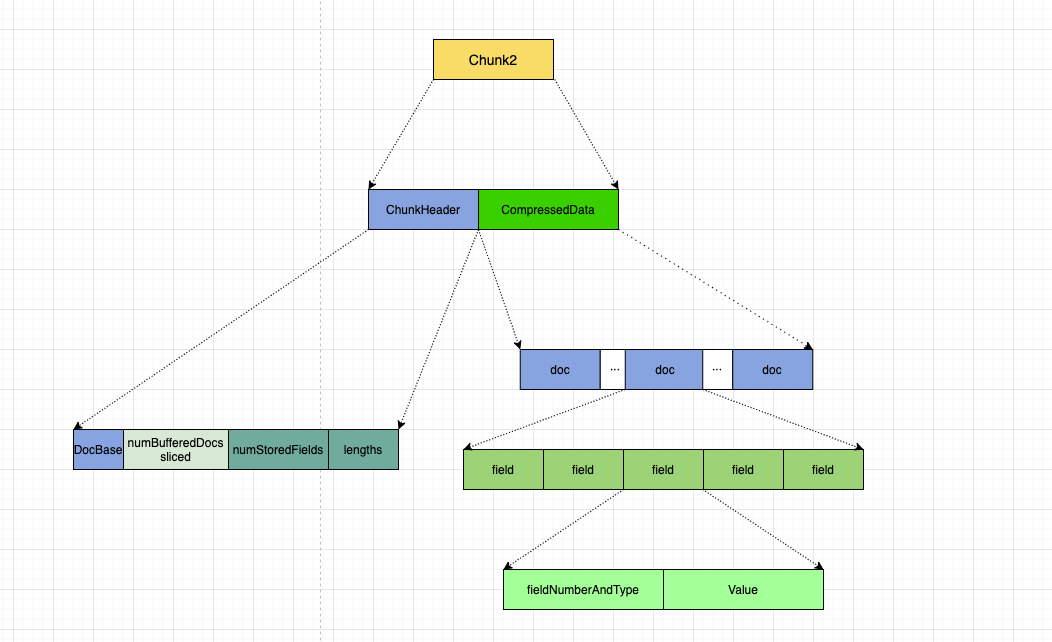
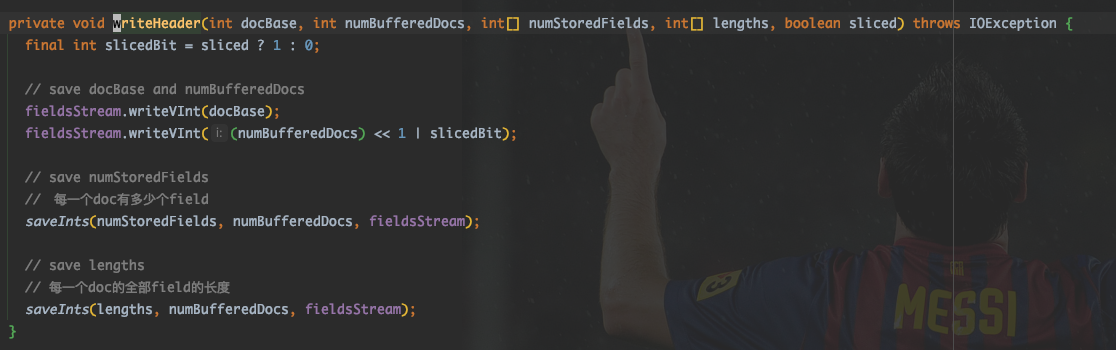
其中。对于每一个 chunk. 首先会存储一个 ChunkHeader:
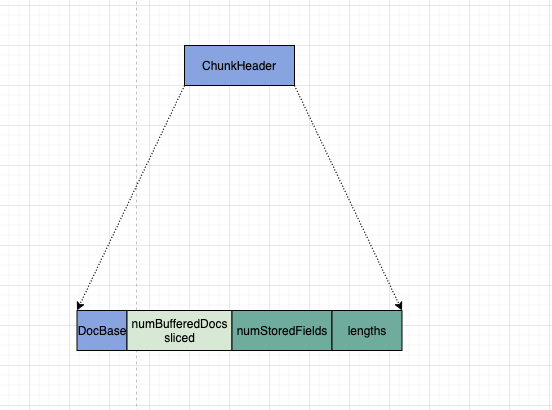
其中包括:
- docBase : 当前 chunk 里的第一个 docID.
-
numBufferedDocs « slice . 当前块里面缓冲了多少个 doc, 可以根据 docBase 及 num 来算出每一个 docId. 还以 bit 的方式存储了当前 chunk 是否分片。
- 存储每个文档有多少个 field. (数组)
- 存储每个文档的 field 信息长度(字节长度) (数组)
之后,会将当前 chunk 的所有 field 信息进行压缩存储。
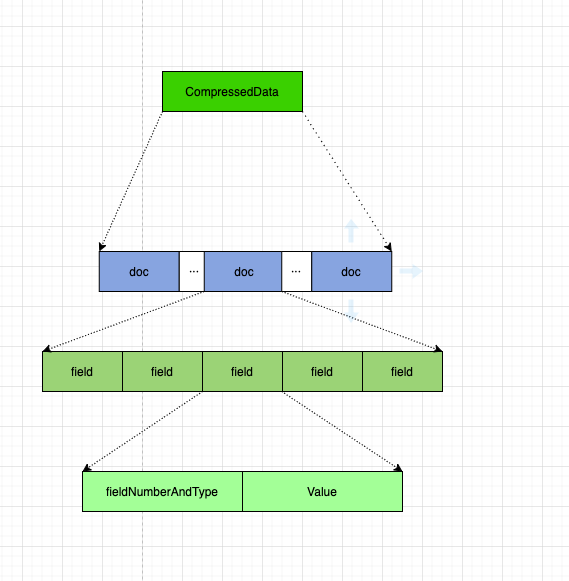
其中依次罗列了所有的 doc, 每个 doc 中罗列了所有的 field.
field 信息中,存储了:
- FieldNumberAndType: field 的编号及类型
- Value: 实际的值,根据不同类型 (int,long,string,bytes 等), 存储方法不同。
写入代码分析
对。fdt 文件的写入,主要是在CompressingStoredFieldsWriter类中进行。
首先是在构造函数中写入 IndexHeader.

之后在每次调用flush(), 即每次缓存够一个 Chunk 时,进行 field 信息的写入。
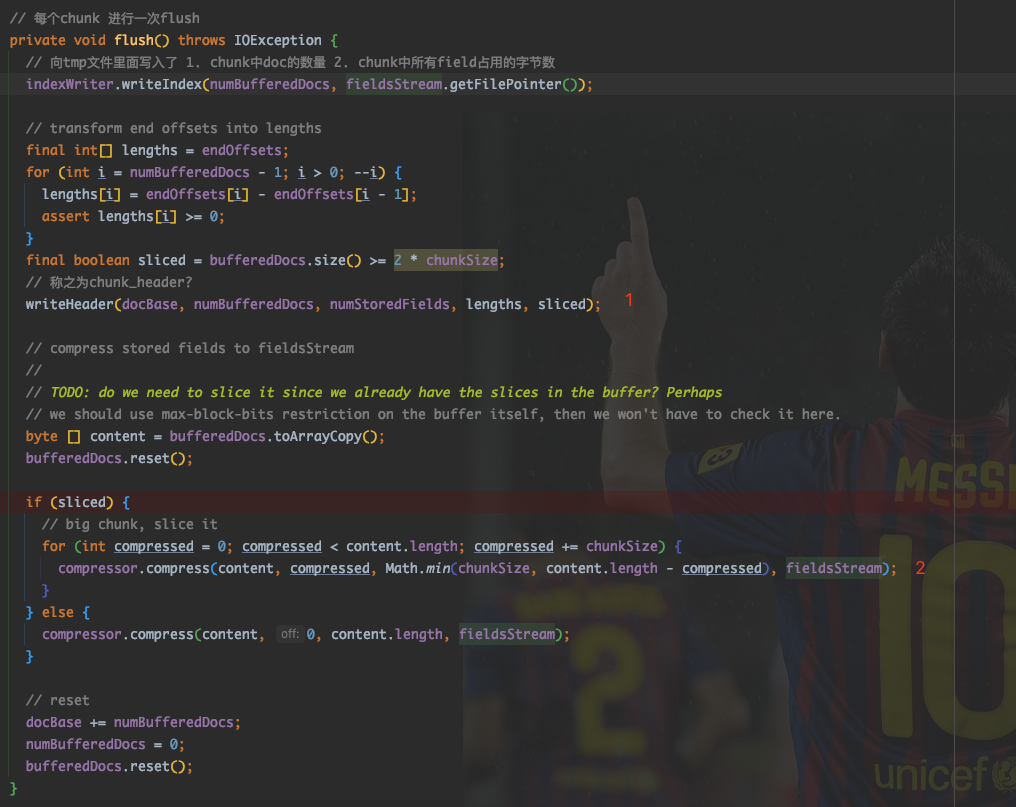
在图中 1 处,写入ChunkHeader.
按序写入了DocBase, numBufferedDocs|Sliced, NumStoredFields, lengths.
在图中 2 处,将当前缓冲的所有 field 信息进行压缩,写入。
内存中缓冲的 field 信息中包含哪些内容呢?这部分的写入在CompressingStoredFieldsWriter类的writeField()方法中。
/**
* 写了什么?
* 1.编号及类型
* 2. 内容
* 2.1 如果是基本类型,直接存储
* 2.2 如果是 bytes, 写长度和内容
* 2.3 如果是 string, 先写长度,然后写内容
*/
@Override
public void writeField(FieldInfo info, IndexableField field)
throws IOException {
// 计数+1
++numStoredFieldsInDoc;
int bits = 0;
final BytesRef bytes;
final String string;
Number number = field.numericValue();
if (number != null) {
if (number instanceof Byte || number instanceof Short || number instanceof Integer) {
bits = NUMERIC_INT;
} else if (number instanceof Long) {
bits = NUMERIC_LONG;
} else if (number instanceof Float) {
bits = NUMERIC_FLOAT;
} else if (number instanceof Double) {
bits = NUMERIC_DOUBLE;
} else {
throw new IllegalArgumentException("cannot store numeric type " + number.getClass());
}
string = null;
bytes = null;
} else {
bytes = field.binaryValue();
if (bytes != null) {
bits = BYTE_ARR;
string = null;
} else {
bits = STRING;
string = field.stringValue();
if (string == null) {
throw new IllegalArgumentException("field " + field.name() + " is stored but does not have binaryValue, stringValue nor numericValue");
}
}
}
// 存储了 field 的内部编号,以及当前 field 的类型,是四种数字呢,还是字符串,还是二进制串。
// number , 一个 int, 右边的 3 位是类型,左边的是编号
final long infoAndBits = (((long) info.number) << TYPE_BITS) | bits;
bufferedDocs.writeVLong(infoAndBits);
if (bytes != null) {
bufferedDocs.writeVInt(bytes.length);
bufferedDocs.writeBytes(bytes.bytes, bytes.offset, bytes.length);
} else if (string != null) {
bufferedDocs.writeString(string);
} else {
if (number instanceof Byte || number instanceof Short || number instanceof Integer) {
bufferedDocs.writeZInt(number.intValue());
} else if (number instanceof Long) {
writeTLong(bufferedDocs, number.longValue());
} else if (number instanceof Float) {
writeZFloat(bufferedDocs, number.floatValue());
} else if (number instanceof Double) {
writeZDouble(bufferedDocs, number.doubleValue());
} else {
throw new AssertionError("Cannot get here");
}
}
}
如代码所示,首先分析了要存储 field 的类型及编码,之后将类型及编号写入一个 long, 以及 field 的真实信息,根据不同的类型进行不同的编码,之后缓冲到内存里,等到一个 chunk 写入完成或者最终调用 finish 时,批量的进行写入。
对 field 原始信息的写入比较简单。在每次添加一个 Document 时,循环调用添加 field. 将对应的 field 编号,类型,内容缓冲到内存里,每次缓冲够一个 Chunk, 进行压缩写入。
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。
也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。

以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
联系邮箱:[email protected]
更多学习笔记见个人博客或关注微信公众号 < 呼延十 >——>呼延十
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK