

技术选型 | OLAP大数据技术哪家强?
source link: https://my.oschina.net/u/3658210/blog/4952043
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


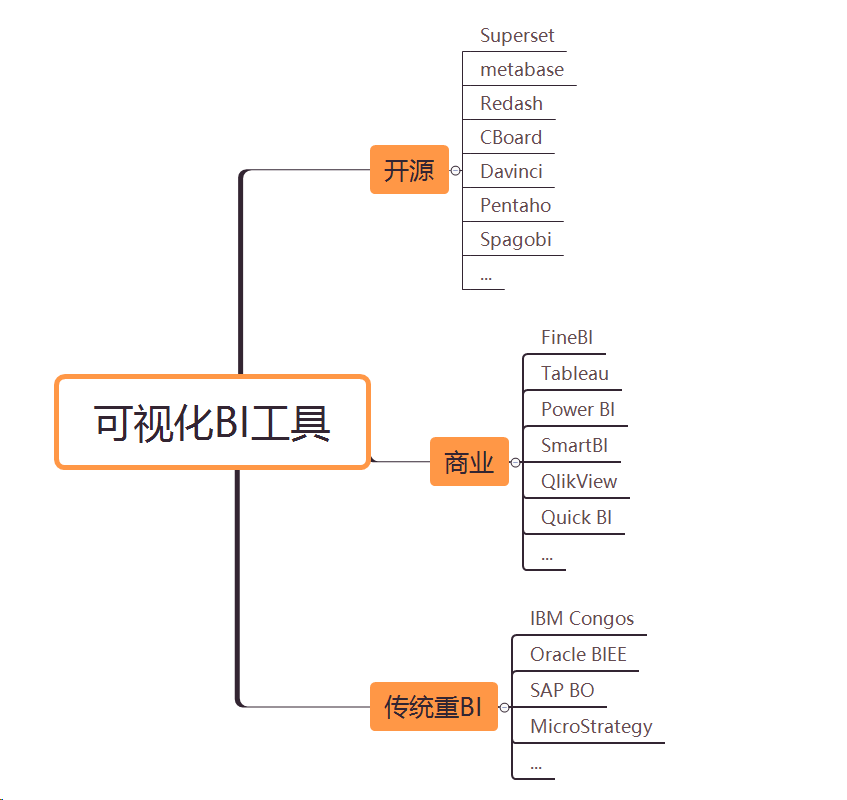
随着大数据组件越来越多,很多组件都是为OLAP数据服务的,什么组件或者组件组合最合适可能是我们关注的问题。本文大体分析业内常见的组件特点,给大家挑选组件提供借鉴。
OLAP提供的服务
Lambda架构的核心理念是“流批一体化”,因为随着机器性能和数据框架的不断完善,用户其实不关心底层是如何运行的,批处理也好,流式处理也罢,能按照统一的模型返回结果就可以了,这就是Lambda架构诞生的原因。现在很多应用,例如Spark和Flink,都支持这种结构,也就是数据进入平台后,可以选择批处理运行,也可以选择流式处理运行,但不管怎样,一致性都是相同的。
OLAP服务工具
01
01
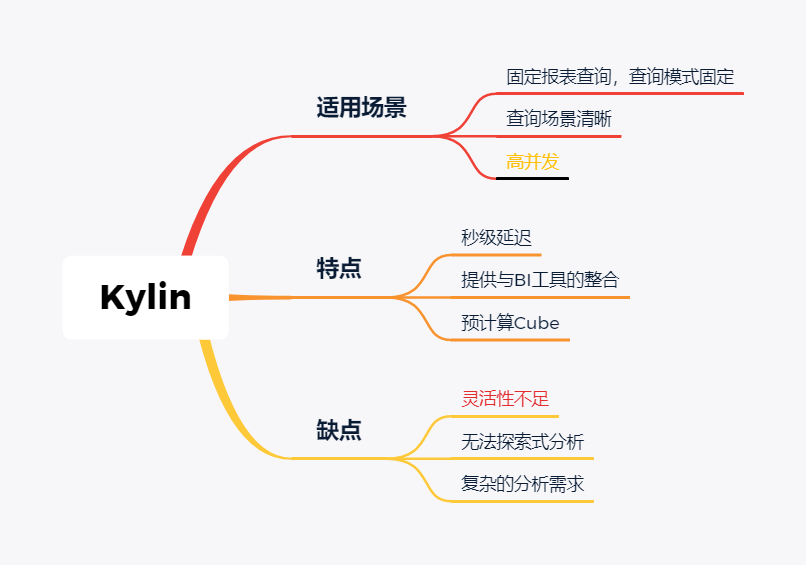
Kylin
Kylin的主要特点是预计算,提前计算好各个cube,这样的优点是查询快速,秒级延迟;缺点也非常明显,灵活性不足,无法做一些探索式的,关联性的数据分析。
适合的场景也是比较固定的,场景清晰的地方。
02
01
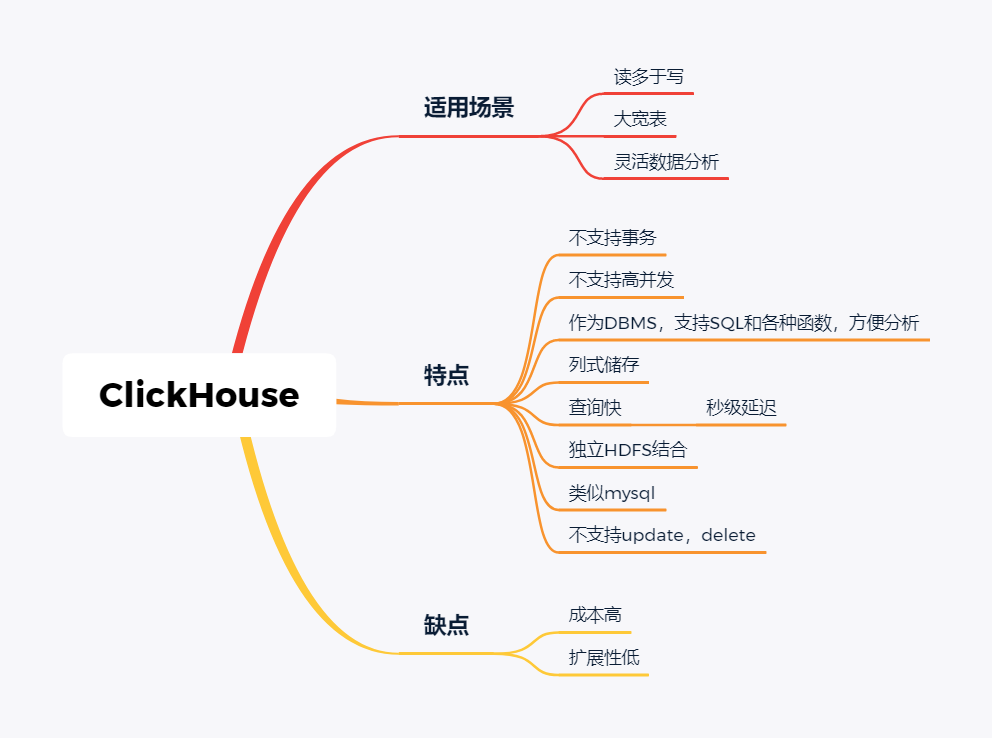
ClickHouse
Clickhouse由俄罗斯yandex公司开发。专为在线数据分析而设计。
Clickhouse最大的特点首先是快,为了快采用了列式储存,列式储存更好的支持压缩,压缩后的数据传输量变小,所以更快;同时支持分片,支持分布式执行,支持SQL。
ClickHouse很轻量级,支持数据压缩和最终数据一致性,其数据量级在PB级别。
另外Clickhouse不是为关联分析而生,所以多表关联支持的不太好。
同样Clickhouse不能修改或者删除数据,仅能用于批量删除或修改。没有完整的事务支持,不支持二级索引等等,缺点也非常明显。
与Kylin相比ClickHouse更加的灵活,sql支持的更好,但是相比Kylin,ClickHouse不支持大并发,也就是不能很多访问同时在线。
总之ClickHouse用于在线数据分析,支持功能简单。CPU 利用率高,速度极快。最好的场景用于行为统计分析。
03
01
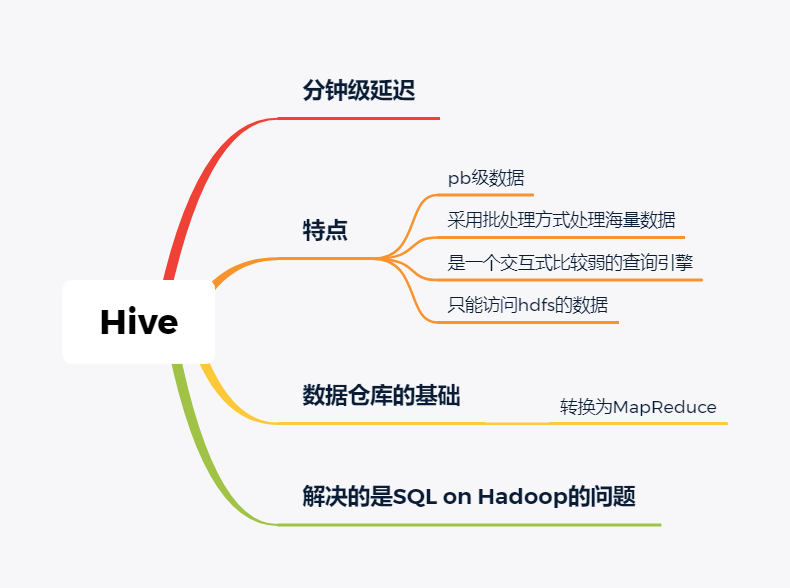
Hive
Hive这个工具,大家一定很熟悉,大数据仓库的首选工具。可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能。
主要功能是可以将sql语句转换为相对应的MapReduce任务进行运行,这样可能处理海量的数据批量,
Hive与HDFS结合紧密,在大数据开始初期,提供一种直接使用sql就能访问HDFS的方案,摆脱了写MapReduce任务的方式,极大的降低了大数据的门槛。
当然Hive的缺点非常明显,定义的是分钟级别的查询延迟,估计都是在比较理想的情况。但是作为数据仓库的每日批量工具,的确是一个稳定合格的产品。
04
01
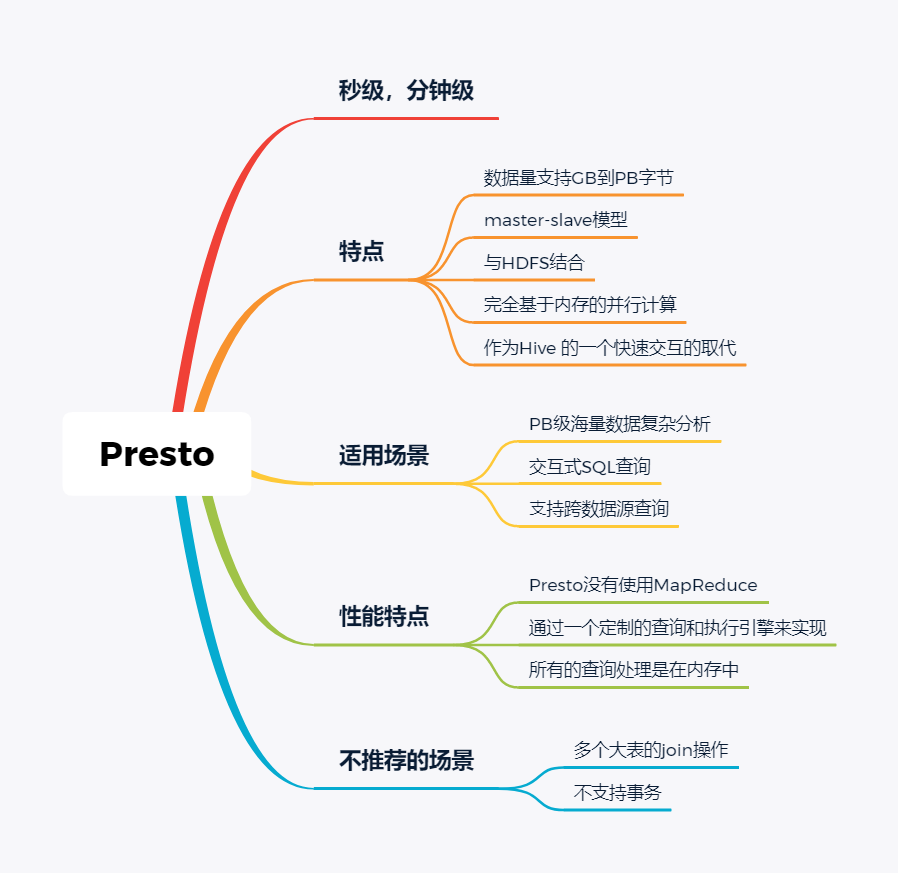
Presto
Presto极大的改进了Hive的查询速度,而且Presto 本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询,支持包括复杂查询、聚合、连接等等。
Presto没有使用MapReduce,它是通过一个定制的查询和执行引擎来完成的。它的所有的查询处理是在内存中,这也是它的性能很高的一个主要原因。
Presto由于是基于内存的,缺点可能是多张大表关联操作时易引起内存溢出错误。
另外Presto不支持OLTP的场景,所以不要把Presto当做数据库来使用。
Presto相比ClickHouse优点主要是多表join效果好。相比ClickHouse的支持功能简单,场景支持单一,Presto支持复杂的查询,应用范围更广。
05
01
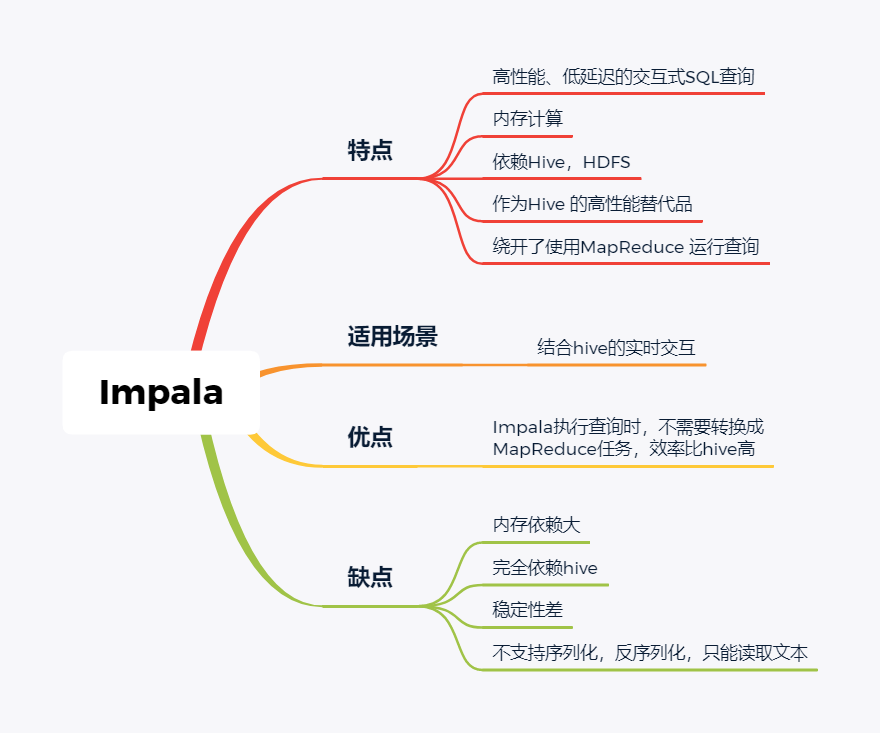
Impala
Impala是Cloudera 公司推出,提供对 HDFS、Hbase 数据的高性能、低延迟的交互式 SQL 查询功能。
Impala 使用 Hive的元数据, 完全在内存中计算。是CDH 平台首选的 PB 级大数据实时查询分析引擎。
Impala 的缺点也很明显,首先严重依赖Hive,而且稳定性也稍差,元数据需要单独的mysql/pgsql来存储,对数据源的支持比较少,很多nosql是不支持的。但是,估计是cloudera的国内市场推广做的不错,Impala在国内的市场不错。
06
01
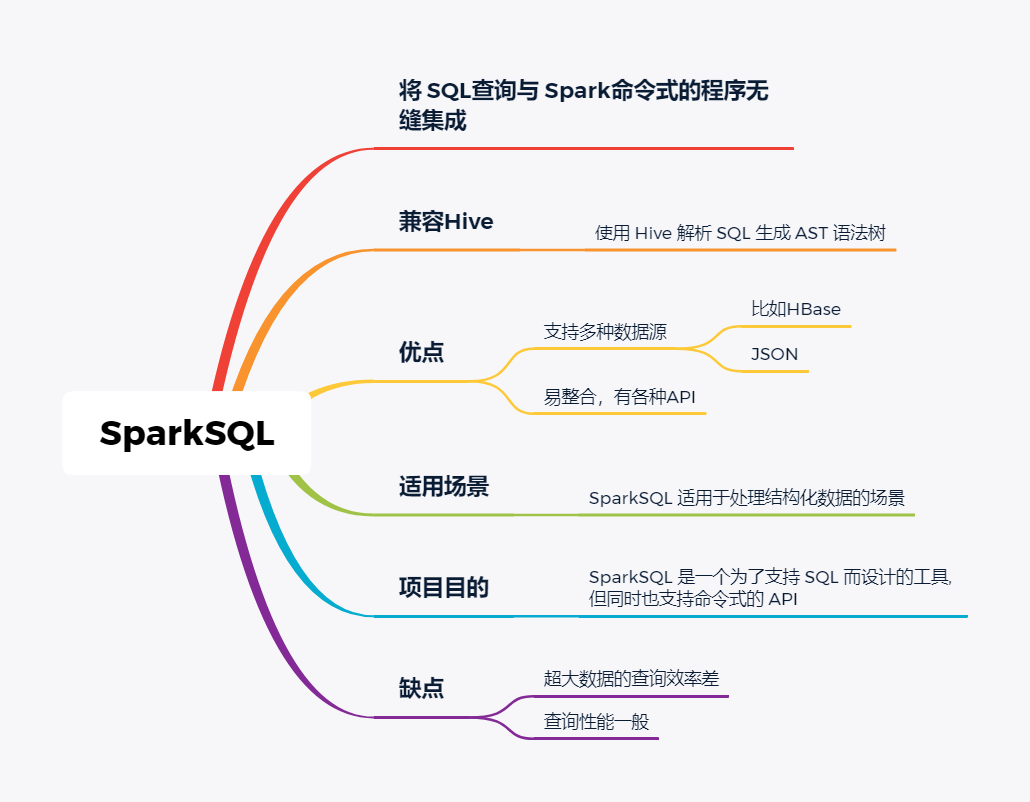
SparkSQL
SparkSQL的前身是Shark,它将 SQL 查询与 Spark 程序无缝集成,可以将结构化数据作为 Spark 的 RDD 进行查询。
SparkSQL后续不再受限于Hive,只是兼容Hive。
SparkSQL提供了sql访问和API访问的接口。
支持访问各式各样的数据源,包括Hive, Avro, Parquet, ORC, JSON, and JDBC。
07
01
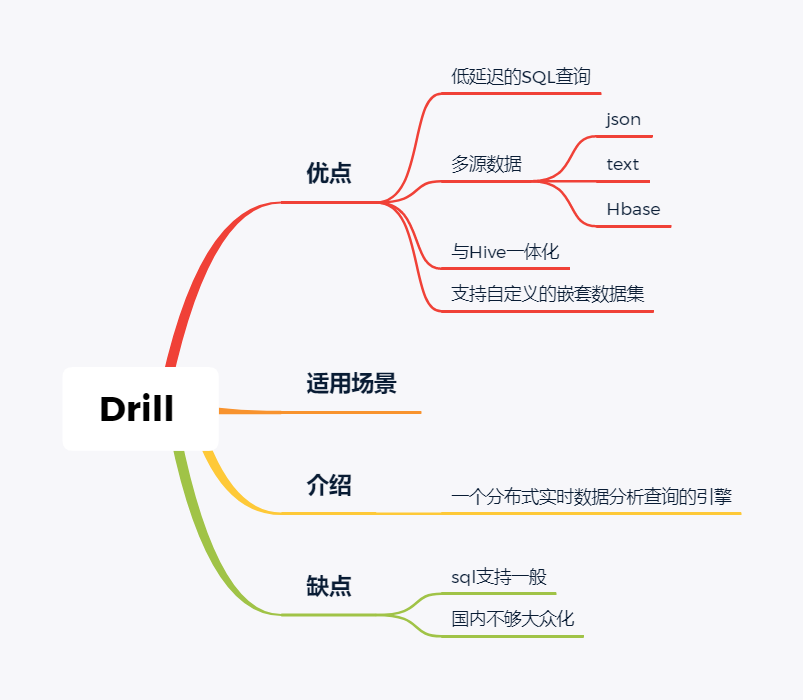
Drill
Drill好像国内使用的很少,根据定义,Drill是一个低延迟的分布式海量数据交互式查询引擎,支持多种数据源,包括hadoop,NoSQL存储等等。
除了支持多种的数据源,Drill跟BI工具集成比较好。
08
01
Druid
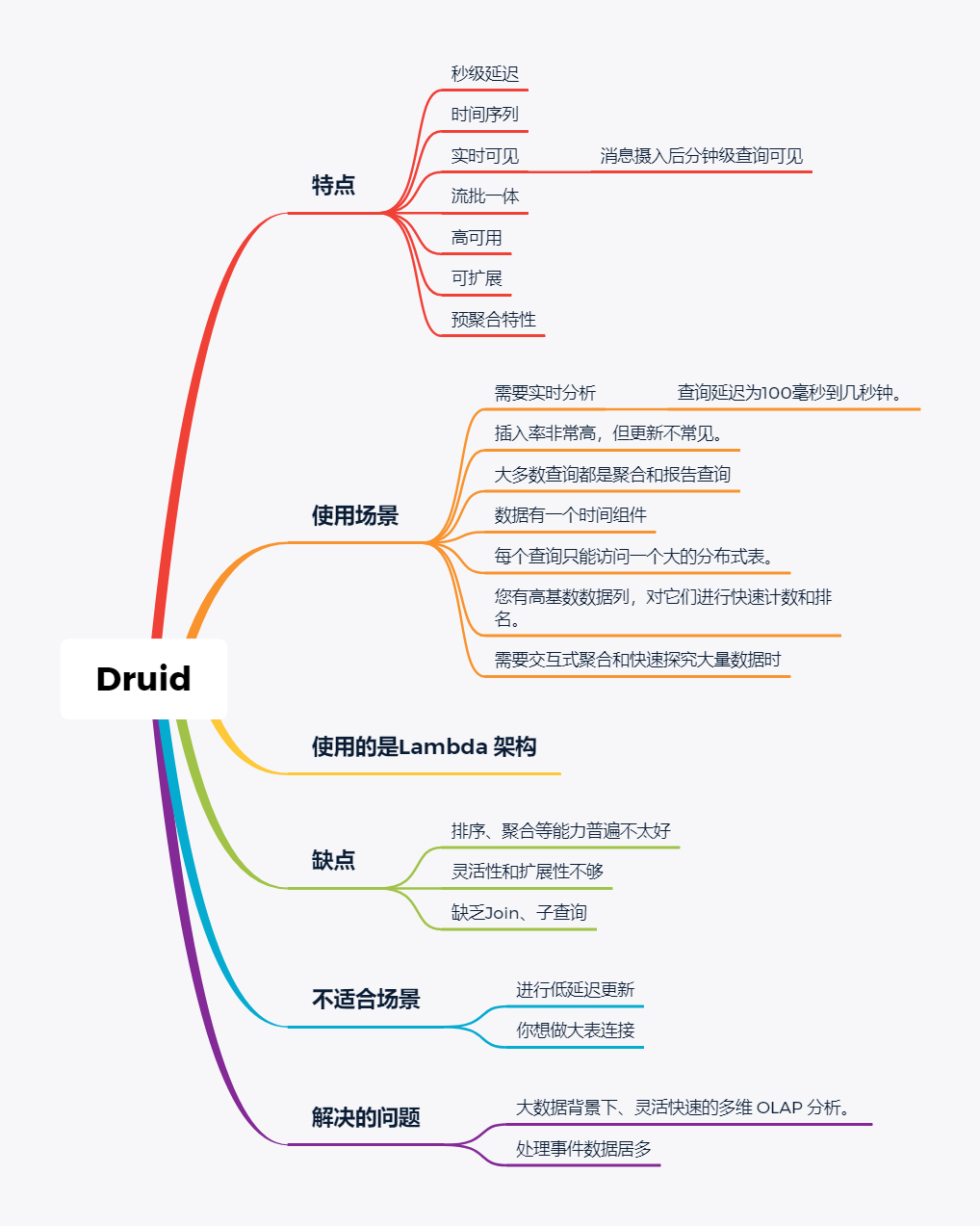
Druid是专为海量数据集上的做高性能 OLAP而设计的数据存储和分析系统。
Druid 的架构是 Lambda 架构,分成实时层和批处理层。
Druid的核心设计结合了数据仓库,时间序列数据库和搜索系统的思想,以创建一个统一的系统,用于针对各种用例的实时分析。Druid将这三个系统中每个系统的关键特征合并到其接收层,存储格式,查询层和核心体系结构中。
目前 Druid 的去重都是非精确的,Druid 适合处理星型模型的数据,不支持关联操作。也不支持数据的更新。
Druid最大的优点还是支持实时与查询功能,解约了很多开发工作。
09
01
Kudu
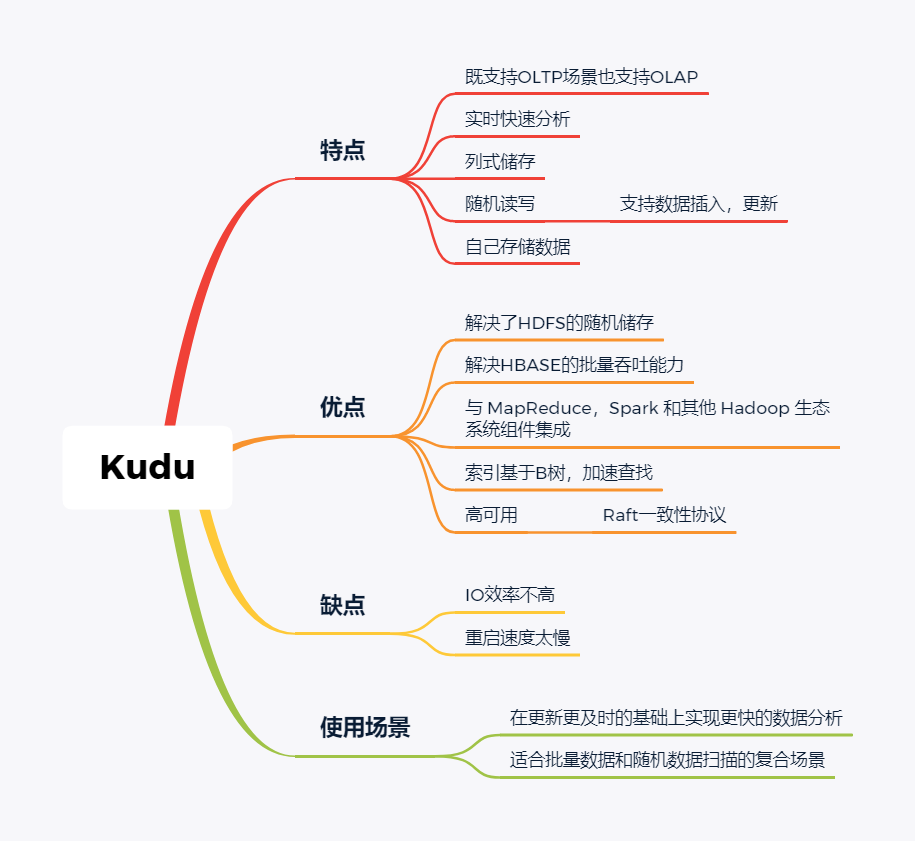
kudu是一套完全独立的分布式存储引擎,很多设计概念上借鉴了HBase,但是又跟HBase不同,不需要HDFS,通过raft做数据复制;分片策略支持keyrange和hash等多种。
数据格式在parquet基础上做了些修改,支持二级索引,更像一个列式存储,而不是HBase schema-free的kv方式。
kudu也是cloudera主导的项目,跟Impala结合比较好,通过impala可以支持update操作。
kudu相对于原有parquet和ORC格式主要还是做增量更新的。
10
01
Hbase
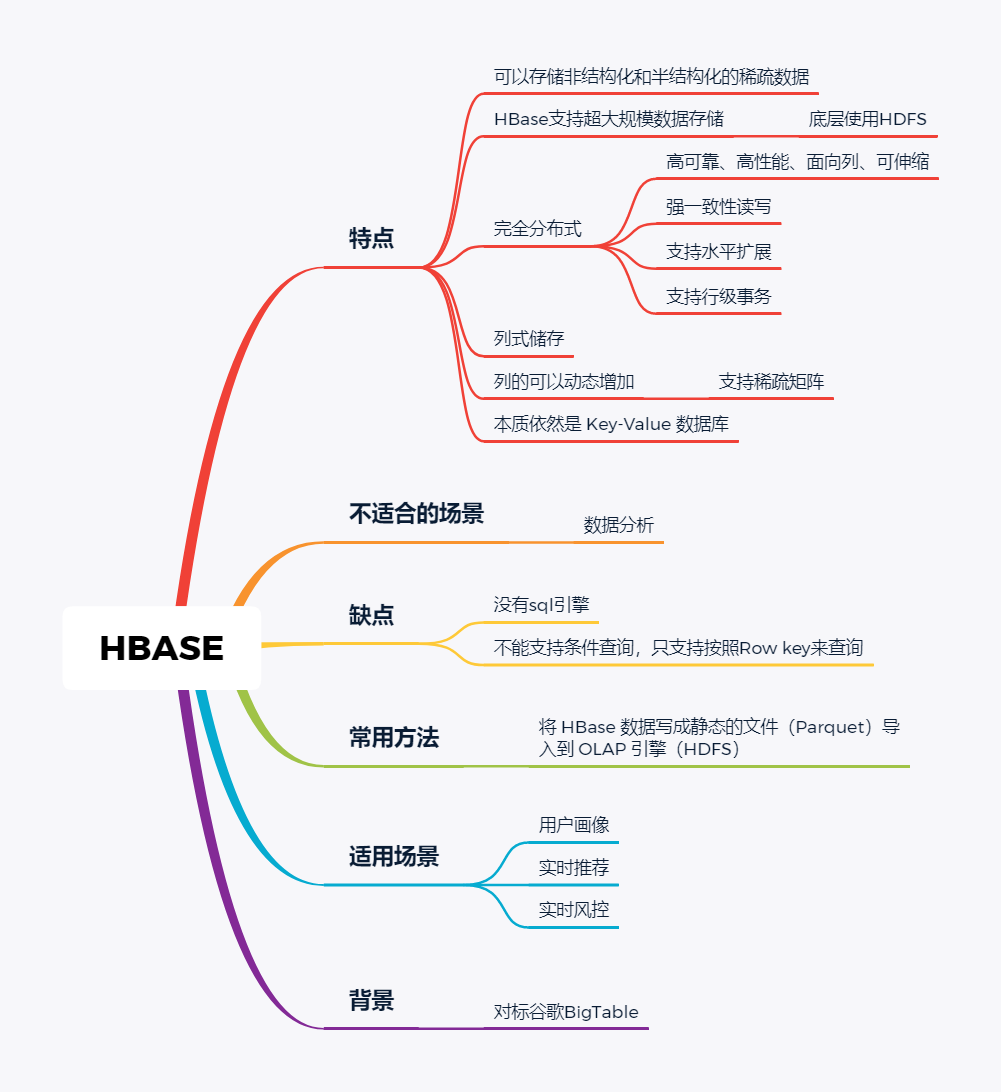
Hbase使用的很广,更多的是作为一个KV数据库来使用,查询的速度很快。
11
01
Hawq是一个Hadoop原生大规模并行SQL分析引擎,Hawq采用 MPP 架构,改进了针对 Hadoop 的基于成本的查询优化器。
除了能高效处理本身的内部数据,还可通过 PXF 访问 HDFS、Hive、HBase、JSON 等外部数据源。HAWQ全面兼容 SQL 标准,还可用 SQL 完成简单的数据挖掘和机器学习。无论是功能特性,还是性能表现,HAWQ 都比较适用于构建 Hadoop 分析型数据仓库应用。
加我微信:ddxygq,来一场朋友圈的点赞之交! 猜你喜欢数仓建模分层理论
数据湖是谁?那数据仓库又算什么?
数仓架构发展史
Hive整合Hbase
Hive中的锁的用法场景
数仓建模方法论
本文分享自微信公众号 - 数据分析挖掘与算法(ikeguang2)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK