

Data Wrangling Solutions — Dynamically Creating Variables When Slicing Dataframe...
source link: https://towardsdatascience.com/data-wrangling-solutions-dynamically-creating-variables-when-slicing-dataframes-fc5613c46831
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Data Wrangling Solutions — Dynamically Creating Variables When Slicing Dataframes
When working on a data science project, we spend more than 70% of our time adjusting data to our needs. While munging data, we encounter many scenarios for which ready-made solutions are not available in standard libraries like pandas.
One such scenario is when we have to create multiple dataframes from a single dataframe. We encounter this scenario when we have a categorical variable, and we want to split the dataframe based on the different values of this variable. A visual representation of this case is as below:

Given the scenario presented above, one can suggest splitting the dataframe manually. Yes, that is a possible solution, but only when the number of categories present in the variable is small. The problem gets challenging when the number of categorical values runs into tens or hundreds. In Python, we do not have any ready-to-use function for this problem. Therefore, we will provide a workaround solution to use the Python dictionaries. The keys in this dictionary will be the different categories of the variable. The value component of the dictionary will be the dataframe slice itself.
A step by step approach to implement this solution is detailed below:
Assumption and Recommendation
Being hands-on is the key to master programming. We recommend that you continue to implement the codes as you follow through with the tutorial. The sample data and the associated Jupiter notebook is available in the Scenario_1 folder of this GitHub link.
If you are new to GitHub, learn its basics from this tutorial. Also, to set up the Python environment on your system and learn the basics of Anaconda distribution, refer to this tutorial.
This tutorial assumes that the reader has at least an intermediate knowledge of working with Python and associated packages like Pandas and Numpy. Following is the list of Python concepts and pandas functions/ methods used in the tutorial:
Pandas functions
- Read_csv
- Groupby
Python Concepts
- Tuples
- Dictionaries
Solution
Step 1 — Keeping the data Ready
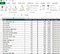
In this tutorial, we will be using the famous cars.csv data set. The data set has details like mileage, horsepower, weight on ~400 car models. Our objective is to split this dataframe into multiple dataframes based on the variable year. The dictionary for this data set and the sample data snapshot is as follows:
- Model— Name of car model
- Actual MPG— Mileage of the car model
- Cylinders— # of cylinders in the car model
- Horsepower— Power of the car model
- Weight— Weight of the car model
- Year— Year of manufacturing
- Origin — Country of manufacturing
Step 2 — Importing pandas package and the data set in Python
Once you have the data available, the next step is to import it to your Python environment.
#### Sample Code
#### Importing Pandas
import pandas as pd#### Importing Data File - Change the Windows Folder Location
imp_data = pd.read_csv("C:\\Ujjwal\\Analytics\\Git\\Data_Wrangling_Tips_Tricks\\Scenario_2\\cars.csv")
We have used Pandas’ ‘read_csv’ function to read the data in Python.
Step 3 — Creating the groupby object
Once we have read the data, apply the groupby method to the dataframe. Use the same column as the argument which wants to use to slice the dataframe.
#### Create a groupby object
groupby_df = imp_data.groupby("Year")
By default, a groupby object in Pandas has two major components:
- Group names — Theseare the unique values of the categorical variable used for grouping
- Grouped data — This is the slice of the dataframe itself corresponding to each group name
Step 4 — Converting the groupby object into a tuple
By converting the groupby object into a tuple, we intend to combine the categorical values and their associated dataframe. To achieve this, pass the groupby object as an argument to the Python function, tuple.
#### Sample Code
tuple_groupby_df = tuple(groupby_df)#### Checking the values of a tuple object created above
print(tuple_groupby_df[0])

Notice the two components of the tuple object. The first value, 70, is the year of manufacturing, and the second value is the sliced dataframe itself.
Step 5— Converting the tuple into a dictionary object
Finally, we will convert the tuple object into a dictionary using the python function dict.
#### Converting the tuple object to a dictionary
dictionary_tuple_groupby_df = dict(tuple_groupby_df)
The dictionary created in the last step is the workaround solution we were referring to in the tutorial. The only difference between this solution and the manual creation of actual variables is the variable names. To use the sliced data, rather than using the variable names, we can use the dictionary with the correct key value. Let us understand how:
#### Manual creation of variables (slicing cars data for year 70)
cars_70 = imp_data[imp_data["year"] == 70]#### Checking the shape of the sliced variable
cars_70.shape#### Output
(29, 7)#### Checking the shape using the dictionary we have created
dictionary_tuple_groupby_df[70].shape#### Output
(29, 7)
In the above code, when using the shape attribute, we used a dictionary object rather than using the specific variable names.
Closing note
Did you know that by having the data wrangling tips up in your sleeves, you can reduce your model building life cycle by more than 20%? I hope that the solution presented above was helpful.
Stay tuned for more data wrangling solutions in future tutorials.
HAPPY LEARNING ! ! ! !
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK