

前端异常监控 Sentry 的私有化部署和使用
source link: https://segmentfault.com/a/1190000038839629
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

前端异常监控 Sentry 的私有化部署和使用
Sentry 为一套开源的应用监控和错误追踪的解决方案。这套解决方案由对应各种语言的 SDK 和一套庞大的数据后台服务组成。应用需要通过与之绑定的 token 接入 Sentry SDK 完成数据上报的配置。通过 Sentry SDK 的配置,还可以上报错误关联的版本信息、发布环境。同时 Sentry SDK 会自动捕捉异常发生前的相关操作,便于后续异常追踪。异常数据上报到数据服务之后,会通过过滤、关键信息提取、归纳展示在数据后台的 Web 界面中。
在完成接入后我们就可以从管理系统中实时查看应用的异常,从而主动监控应用在客户端的运行情况。通过配置报警、分析异常发生趋势更主动的将异常扼杀在萌芽状态,影响更少的用户。通过异常详情分析、异常操作追踪,避免对客户端应用异常两眼一抹黑的状态,更高效的解决问题。
这篇文章也将会从一键部署服务开始,通过解决部署过程中遇到的问题,分享到完成前端应用监控和异常数据使用的整个详细过程,希望会对你的部署和使用中遇到的问题有所帮助。
快速部署 Sentry 服务
Sentry 的管理后台是基于 Python Django 开发的。这个管理后台由背后的 Postgres 数据库(管理后台默认的数据库,后续会以 Postgres 代指管理后台数据库并进行分享)、ClickHouse(存数据特征的数据库)、relay、kafka、redis 等一些基础服务或由 Sentry 官方维护的总共 23 个服务支撑运行。可见的是,如果独立的部署和维护这 23 个服务将是异常复杂和困难的。幸运的是,官方提供了基于 docker 镜像的一键部署实现 getsentry/onpremise。
这种部署方式依赖于 Docker 19.03.6+ 和 Compose 1.24.1+
Docker 是可以用来构建和容器化应用的开源容器化技术。
Compose 是用于配置和运行多 Docker 应用的工具,可以通过一个配置文件配置应用的所有服务,并一键创建和运行这些服务。
在准备好 linux 服务器之后,并按照官方文档安装好对应版本的 Docker 和 Compose 之后,将 onpremise 的源代码克隆到工作台目录:
git clone https://github.com/getsentry/onpremise.git
# 切换到 20.10.1 版本,后续的分享将会基于这个版本进行
git checkout release/20.10.1docker 镜像加速
在后续部署的过程中,需要拉取大量镜像,官方源拉取较慢,可以修改 docker 镜像源,修改或生成 /etc/docker/daemon.json 文件:
{
"registry-mirrors": ["镜像地址"]
}然后重新加载配置,并重启 docker 服务:
sudo systemctl daemon-reload
sudo systemctl restart docker在 onpremise 的根路径下有一个 install.sh 文件,只需要执行此脚本即可完成快速部署,脚本运行的过程中,大致会经历以下步骤:
- 生成服务配置
- docker volume 数据卷创建(可理解为 docker 运行的应用的数据存储路径的创建)
- 拉取和升级基础镜像
- 服务初始化
- 设置管理员账号(如果跳过此步,可手动创建)
在执行结束后,会提示创建完毕,运行 docker-compose up -d 启动服务。
在使用不添加 -d 参数运行 docker-compose up 命令后,我们可以看到服务的启动日志,需要等待内部 web、relay、snuba、kafka 等全部启动并联动初始化后,服务才算完全启动,此刻才可以使用默认端口访问管理端默认服务地址,此时可以进行域名配置,并将 80 端口解析到服务的默认端口上,便可以使用域名进行访问。

第一次访问管理后台,可以看到欢迎页面,完成必填项的配置,即可正式访问管理后台。
- Root URL:异常上报接口的公网根地址(在做网络解析配置时,后台服务可以配置到内网外网两个域名,只将上报接口的解析规则
/api/[id]/store/配置到公网环境,保证数据不会泄密)。 - Admin Email:在 install.sh 阶段创建的管理员账号。
- Outbound email:这部分内容为邮件服务配置,可以先不配置。
完成这部分工作后,对服务没有定制化需求的可以跳至前端接入和使用部分。
docker 数据存储位置修改
可以看到在服务运行的过程中,会在 docker volume 数据卷挂载位置存储数据,如 Postgres、运行日志等,docker volume 默认挂载在 /var 目录下,如果你的 /var 目录容量较小,随着服务的运行会很快占满,需要对 docker volume 挂载目录进行修改。
# 在容量最大的目录下创建文件夹
mkdir -p /data/var/lib/
# 停止 docker 服务
systemctl stop docker
# 将 docker 的默认数据复制到新路径下,删除旧数据并创建软连接,即使得存储实际占用磁盘为新路径
/bin/cp -a /var/lib/docker /data/var/lib/docker && rm -rf /var/lib/docker && ln -s /data/var/lib/docker /var/lib/docker
# 重启 docker 服务
systemctl start docker一键部署的 Sentry 服务总会有不符合我们使用和维护设计的地方,这个时候,就需要通过对部署配置的修改来满足自己的需求。
服务组成与运行机制
在通过 docker-compose 快速部署之后,我们先来观察下启动了哪些服务,并为后续的适配和修改分析下这些服务的作用,运行 docker 查看所有容器的命令:
docker ps可以看到现在启动的所有服务,并且一些服务是使用的同一个镜像通过不同的启动参数启动的,按照镜像区分并且通过笔者的研究推测,各个服务的作用如下:
nginx:1.16
- sentry_onpremise_nginx_1:进行服务间的网络配置
sentry-onpremise-local:以下服务使用同一个镜像,即使用同一套环境变量
sentry_onpremise_worker_1
- 可能是处理后台任务,邮件,报警相关
sentry_onpremise_cron_1
- 定时任务,不确定是什么定时任务,可能也是定时清理
sentry_onpremise_web_1
- web 服务(UI + web api)
- sentry_onpremise_post-process-forwarder_1
sentry_onpremise_ingest-consumer_1
- 处理 kafka 消息
sentry-cleanup-onpremise-local
sentry_onpremise_sentry-cleanup_1
- 数据清理,暂时不重要,但是应该和其他的 sentry 服务公用一些配置
sentry_onpremise_snuba-cleanup_1
- 数据清理,暂时不重要
getsentry/relay:20.10.1
sentry_onpremise_relay_1
- 来自应用上报的数据先到 relay,
- relay 直接返回响应状态
- 后在后台任务中继续处理数据
- 解析事件、格式调整、启用过滤规则等丢弃数据
- 数据写入 kafka
symbolicator-cleanup-onpremise-local
sentry_onpremise_symbolicator-cleanup_1
- 数据清理的,暂时不重要
getsentry/snuba:20.10.1
- 看起来是消费 kafka 消息,往 ClickHouse 写,用到了 redis,用途不明
sentry_onpremise_snuba-api_1
- snuba 的接口服务,好像没什么作用
sentry_onpremise_snuba-consumer_1
- 消费 Kafka 给 ClickHouse 提供事件
sentry_onpremise_snuba-outcomes-consumer_1
- 消费 Kafka 给 ClickHouse outcomes
sentry_onpremise_snuba-sessions-consumer_1
- 消费 Kafka 给 ClickHouse sessions
sentry_onpremise_snuba-replacer_1
- 看起来是转换老(或者别的转换功能)数据的,从kafka拿后写到kafka
tianon/exim4
sentry_onpremise_smtp_1
memcached:1.5-alpine
- sentry_onpremise_memcached_1
- 也许是用来降低数据存储的频次和冲突的
getsentry/symbolicator:bc041908c8259a0fd28d84f3f0b12daa066b49f6
sentry_onpremise_symbolicator_1
- 最基础的设施:解析(native)错误信息
postgres:9.6
sentry_onpremise_postgres_1
- 基础的设施,服务后台默认的数据库,存储异常数据
confluentinc/cp-kafka:5.5.0
sentry_onpremise_kafka_1
- 基础的设施,ClickHouse 和 pg 的数据肯定都是从 kafka 来的
redis:5.0-alpine
sentry_onpremise_redis_1
- 基础的设施,有一些拦截配置在这
confluentinc/cp-zookeeper:5.5.0
sentry_onpremise_zookeeper_1
- 基础的设施
yandex/ClickHouse-server:19.17
sentry_onpremise_ClickHouse_1
- 与pg不同的存储,存储是异常的关键信息,用于快速检索
同时,根据异常上报到服务后,日志的记录情况可知,运行机制大概如下:
- 异常数据通过 nginx 解析到 relay 服务。
- relay 通过 pg 获取最新的应用与 token 匹配关系,并验证数据中的 token,直接返回 403 或 200,并对数据进行拦截过滤。
- relay 将数据发送给 kafka 的不同 topic。
- sentry 订阅其中部分 topic,解析数据存入 Postgres,用做后续查看错误详情。
- snuba 订阅其他 topic,对数据打标签,提取关键特征,存入 ClickHouse,用来快速根据关键特征检索数据。
文件结构与作用
要对部署和运行进行修改的话,需要找到对应的配置文件,先看下 onpremise 部署实现的主要文件结构和作用:
- clickhouse/config.xml:clickhouse 配置文件
- cron/:定时任务的镜像构建配置和启动脚本
- nginx/nginx.conf:nginx 配置
- relay/config.example.yml:relay 服务配置文件
sentry/:sentry-onpremise-local 镜像的构建和基于此镜像启动的主服务的配置都在这个文件夹下
- Dockerfile:sentry-onpremise-local 的镜像构建配置,会以此启动很多服务
- requirements.example.txt:由此生成 requirements.txt,需要额外安装的 Django 插件需要被写在这里面
- .dockerignore:Docker 的忽略配置,初始忽略了 requirements.txt 之外的所有文件,如果构建新镜像时需要 COPY 新东西则需要修改此文件
- config.example.yml:由此生成 config.yml,一般放运行时不能通过管理后台修改的配置
- sentry.conf.example.py:由此生成 sentry.conf.py,为 python 代码,覆盖或合并至 sentry 服务中,从而影响 sentry 运行。
- .env:镜像版本、数据保留天数、端口等配置
- docker-compose.yml:Compose 工具配置,多 docker 的批量配置和启动设置
- install.sh:Sentry 一键部署流程脚本
同时需要注意的是,一旦部署过之后,install.sh 脚本就会根据 xx.example.xx 生成实际生效的文件,而且,再次执行 install.sh 脚本时会检测这些文件存不存在,存在则不会再次生成,所以需要修改配置后重新部署的情况下,我们最好将生成的文件删除,在 xx.example.xx 文件中修改配置。
根据服务组成和运行机制得知,主服务是基于 sentry-onpremise-local 镜像启动的,而 sentry-onpremise-local 镜像中的 sentry 配置会合并 sentry.conf.py,此文件又是由 sentry.conf.example.py 生成,所以后续定制化服务时,会重点修改 sentry.conf.example.py 配置模板文件。
使用独立数据库确保数据稳定性
在数据库单机化部署的情况下,一旦出现机器故障,数据会损坏丢失,而 onpremise 的一键部署就是以 docker 的形式单机运行的数据库服务,且数据库数据也存储在本地。
可以看到 Sentry 的数据库有两个,Postgres 和 ClickHouse。
虽然 Sentry 不是业务应用,在宕机后不影响业务正常运行,数据的稳定并不是特别重要,但是 Postgres 中存储了接入 Sentry 的业务应用的 id 和 token 与对应关系,在这些数据丢失后,业务应用必须要修改代码以修改 token 重新上线。为了避免这种影响,且公司有现成的可容灾和定期备份的 Postgres 数据库,所以将数据库切换为外部数据库。
修改 sentry.conf.example.py 文件中 DATABASES 变量即可:
DATABASES = {
'default': {
'ENGINE': 'sentry.db.postgres',
'NAME': '数据库名',
'USER': '数据库用户名',
'PASSWORD': '数据库密码',
'HOST': '数据库域名',
'PORT': '数据库端口号',
}
}由于不再需要以 Docker 启动 Postgres 数据库服务,所以将 Postgres 相关信息从 docker-compose.yml 文件中删除。删掉其中的 Postgres 相关配置即可。
depends_on:
- redis
- postgres # 删除
# ...
services:
# ...
# 删除开始
postgres:
<< : *restart_policy
image: 'postgres:9.6'
environment:
POSTGRES_HOST_AUTH_METHOD: 'trust'
volumes:
- 'sentry-postgres:/var/lib/postgresql/data'
# 删除结束
# ...
volumes:
sentry-data:
external: true
sentry-postgres: # 删除
external: true # 删除同时,由于 Sentry 在启动前,初始化数据库结构的使用会 pg/citext 扩展,创建函数,所以对数据库的用户权限有一定要求,也需要将扩展提前启用,否则会导致 install.sh 执行失败。
控制磁盘占用
随着数据的上报,服务器本地的磁盘占用和数据库大小会越来越大,在接入300万/日的流量后,磁盘总占用每天约增加 1.4G-2G,按照 Sentry 定时数据任务的配置保留 90 天来说,全量接入后磁盘占用会维持在一个比较大的值,同时这么大的数据量对数据的查询也是一个负担。为了减轻负担,需要从服务端和业务应用端同时入手。综合考虑我们将数据保留时长改为 7 天。修改 .env 文件即可:
SENTRY_EVENT_RETENTION_DAYS=7也可以直接修改 sentry.conf.example.py:
SENTRY_OPTIONS["system.event-retention-days"] = int(
env("SENTRY_EVENT_RETENTION_DAYS", "90")
)
# 改为
SENTRY_OPTIONS["system.event-retention-days"] = 7需要注意的是,定时任务使用 delete 语句删除过期数据,此时磁盘空间不会被释放,如果数据库没有定时回收的机制,则需要手动进行物理删除。
# 作为参考的回收语句
vacuumdb -U [用户名] -d [数据库名] -v -f --analyze单点登录 CAS 登录接入
Sentry 本身支持 SAML2、Auth0 等单点登录方式,但是我们需要支持 CAS3.0,Sentry 和 Django 没有对此有良好支持的插件,所以笔者组装了一个基本可用的插件 sentry_cas_ng。
使用时,需要进行插件的安装、注册和配置,插件使用 github 地址安装,需要一些前置的命令行工具,就不在 requirements.txt 文件中进行配置,直接修改 sentry/Dockerfile 文件进行安装,追加以下内容:
# 设置镜像源加速
RUN echo 'deb http://mirrors.aliyun.com/debian/ buster main non-free contrib \n\
deb http://mirrors.aliyun.com/debian/ buster-updates main non-free contrib \n\
deb http://mirrors.aliyun.com/debian/ buster-backports main non-free contrib \n\
deb http://mirrors.aliyun.com/debian-security/ buster/updates main non-free contrib \n\
deb-src http://mirrors.aliyun.com/debian/ buster main non-free contrib \n\
deb-src http://mirrors.aliyun.com/debian/ buster-updates main non-free contrib \n\
deb-src http://mirrors.aliyun.com/debian/ buster-backports main non-free contrib \n\
deb-src http://mirrors.aliyun.com/debian-security/ buster/updates main non-free contrib' > /etc/apt/sources.list
# 升级和安装前置工具
RUN apt-get update && apt-get -y build-dep gcc \
&& apt-get install -y -q libxslt1-dev libxml2-dev libpq-dev libldap2-dev libsasl2-dev libssl-dev sysvinit-utils procps
RUN apt-get install -y git
# 安装这个基本可用的 cas 登录插件
RUN pip install git+https://github.com/toBeTheLight/sentry_cas_ng.git同时修改 sentry.conf.example.py 文件,以进行插件的注册和配置项配置:
# 修改 session 库,解决 session 较长的问题
SESSION_ENGINE = 'django.contrib.sessions.backends.db'
# 在 django 中安装插件
INSTALLED_APPS = INSTALLED_APPS + (
'sentry_cas_ng',
)
# 注册插件中间件
MIDDLEWARE_CLASSES = MIDDLEWARE_CLASSES + (
'sentry_cas_ng.middleware.CASMiddleware',
)
# 注册插件数据管理端
AUTHENTICATION_BACKENDS = (
'sentry_cas_ng.backends.CASBackend',
) + AUTHENTICATION_BACKENDS
# 配置 CAS3.0 单点登录的登录地址
CAS_SERVER_URL = 'https://xxx.xxx.com/cas/'
# 配置 cas 版本信息
CAS_VERSION = '3'
# 因为插件是使用拦截登录页强制跳转至 SSO 页面的方式实现的
# 所以需要配置登录拦截做跳转 SSO 登录操作
# 需要将 pathReg 配置为你的项目的登录 url 的正则
# 同时,当页面带有 ?admin=true 参数时,不跳转至 SSO
def CAS_LOGIN_REQUEST_JUDGE(request):
import re
pathReg = r'.*/auth/login/.*'
return not request.GET.get('admin', None) and re.match(pathReg, request.path) is not None
# 配置登出拦截做登出操作
# 让插件识别当前为登出操作,销毁当前用户 session
# 为固定内容,不变
def CAS_LOGOUT_REQUEST_JUDGE(request):
import re
pathReg = r'.*/api/0/auth/.*'
return re.match(pathReg, request.path) is not None and request.method == 'DELETE'
# 是否自动关联 sso cas 信息至 sentry 用户
CAS_APPLY_ATTRIBUTES_TO_USER = True
# 登录后分配的默认组织名称,必须与管理端 UI 设置的组织名相同
AUTH_CAS_DEFAULT_SENTRY_ORGANIZATION = '[组织名]'
# 登录后默认的角色权限
AUTH_CAS_SENTRY_ORGANIZATION_ROLE_TYPE = 'member'
# 登录后默认的用户邮箱后缀,如 @163.com 中的 163.com
AUTH_CAS_DEFAULT_EMAIL_DOMAIN = '[邮箱后缀]'完成配置后,需要使用 Sentry 的默认组织名 sentry,访问 xxx/auth/login/sentry?admin=true,避过 CAS 插件拦截,以管理员身份登录,然后修改 Sentry 设置的组织名为插件中的配置的组织名变量 AUTH_CAS_DEFAULT_SENTRY_ORGANIZATION 的值。否则新用户通过 SSO 登录后会由于要分配的组织名和服务设置的组织名不匹配出现错误。
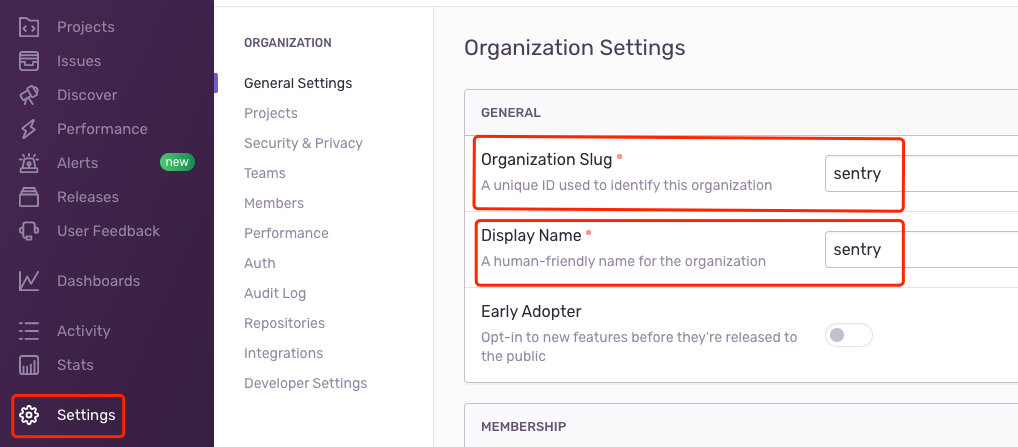
修改默认时区
在登录 Sentry 之后,可以发现异常的时间为 UTC 时间,每个用户都可以在设置中将时区改为本地时区:
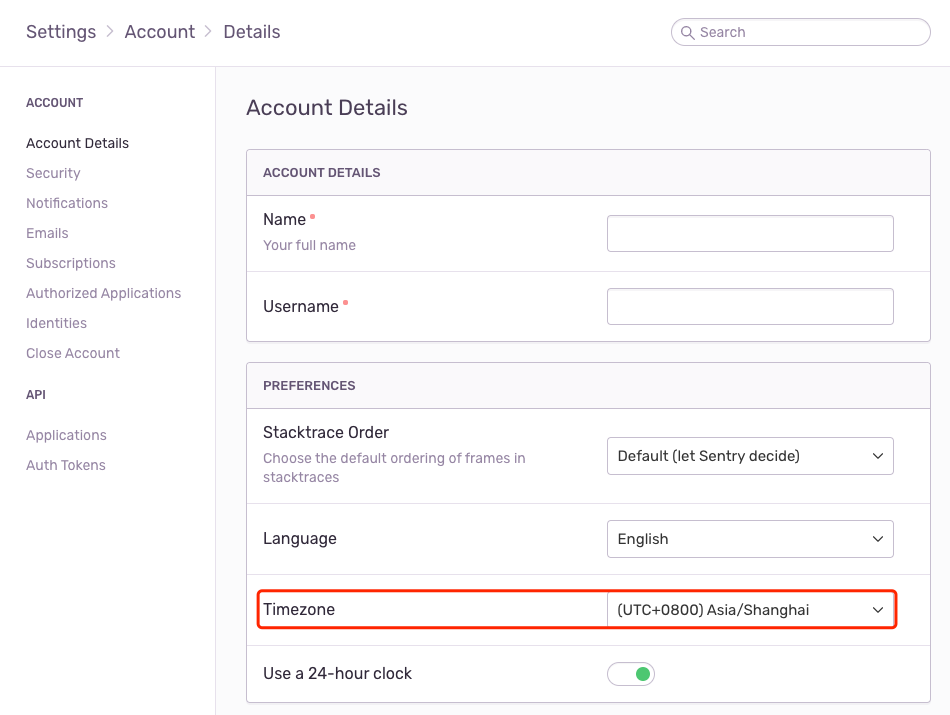
出于用户友好考虑,可以直接修改服务的默认时区,在 sentry.conf.example.py 文件中添加配置:
# http://en.wikipedia.org/wiki/List_of_tz_zones_by_name
SENTRY_DEFAULT_TIME_ZONE = 'Asia/Shanghai'获取真实 IP
Sentry 会获取请求头中 X-Forwarded-For (结构为ip1,ip2,ip3)的第一个 IP 为真实用户 IP,Sentry 一键部署启动的服务的最靠前的服务是一个 Nginx 服务,它的配置就是之前提到的 nginx/nginx.conf 文件,在其中可以看到一行 proxy_set_header X-Forwarded-For $remote_addr;,其中 $remote_addr 表示“客户端” IP,但是这个客户端是相对于 Nginx 服务的而言的,如果前面有其他的代理服务器,那么拿到的就是代理服务器的 IP。在我们的部署环境中,X-Forwarded-For 由前置的 Nginx 服务提供,且已经处理成需要的格式,所以删除此行即可。
角色权限修改
在 Sentry 的默认的角色权限系统中有以下名词,在信息结构按照包含关系有组织、团队、项目、事件。
在角色层面又具有:
- superuser:系统管理员(非常规角色),可删除用户账号,在 install.sh 脚本执行时创建的账号就是系统管理员。
- owner:组织管理员,在私有化部署的情况下只有一个组织,即可以修改服务配置之外的信息,可以控制组织及以下层面的配置、删除。
- manager:团队管理员,可从团队中移除用户,可创建删除所有项目,可创建删除所有团队。
- admin:可进行项目的设置(如报警、入站规则),批准用户加入团队,创建团队、删除所在团队,调整所在团队的工程的配置。
- member:可进行问题的处理。
且角色是跟随账号的,也就是说,一个 admin 会在他加入的所有的团队中都是 admin。
在我们的权限设计中,希望的是由 owner 创建团队和团队下的项目,然后给团队分配 admin。即 admin 角色管理团队下的权限配置,但是不能创建和删除团队和项目。在 Sentry 的现状下,最接近这套权限设计的情况中,只能取消 admin 对团队、项目的增删权限,而无法设置他只拥有某个团队的权限。
在 Sentry 的配置中是这么管理权限的:
SENTRY_ROLES = (
# 其他角色
# ...
{
'id': 'admin',
'name': 'Admin',
'desc': '省略'
'of.',
'scopes': set(
[
"org:read","org:integrations",
"team:read","team:write","team:admin",
"project:read", "project:write","project:admin","project:releases",
"member:read",
"event:read", "event:write","event:admin",
]),
}
)其中 read、write 为配置读写,admin 则是增删,我们只需要删掉 "team:admin" 和 "project:admin" 后在 sentry.conf.example.py 文件中复写 SENTRY_ROLES 变量即可。需要调整其他角色权限可以自行调整。
其他配置修改
至此,我们的定制化配置就完成了。
基本上所有的配置都可以通过在 sentry.conf.example.py 文件中重新赋值整个变量或某个字段的方式调整,有哪些配置项的话可以去源代码的 src/sentry/conf/server.py 文件中查询,有其他需求的话可以自行尝试修改。
前端接入和使用
后续的接入使用,我们以 Vue 项目示范。
SDK 接入
首先需要进行对应团队和项目的创建:

选取平台语言等信息后,可以创建团队和项目:

npm i @sentry/browser @sentry/integrations其中 @sentry/browser 为浏览器端的接入 sdk,需要注意的是,它只支持 ie11 及以上版本的浏览器的错误上报,低版本需要使用 raven.js,我们就不再介绍。
@sentry/integrations 包里是官方提供的针对前端各个框架的功能增强,后续会介绍。
在进行接入是,我们必须要知道的是和你当前项目绑定的 DSN(客户端秘钥),可在管理端由 Settings 进入具体项目的配置中查看。
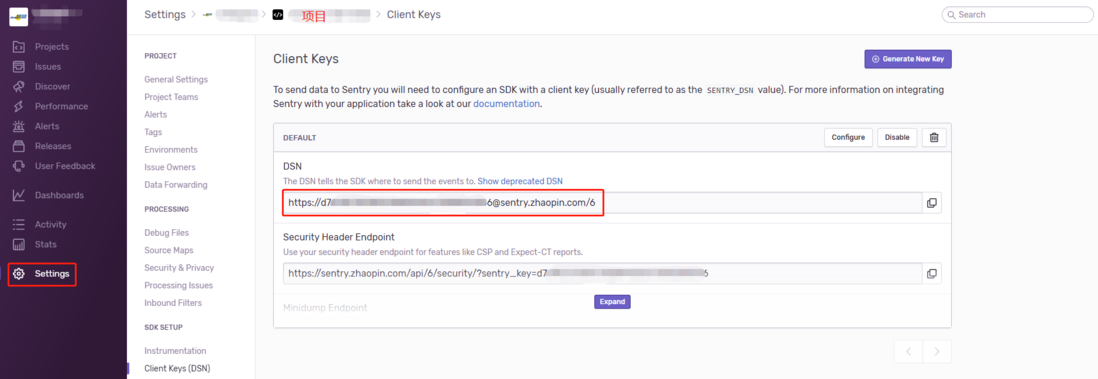
import * as Sentry from '@sentry/browser'
import { Vue as VueIntegration } from '@sentry/integrations'
import Vue from 'vue'
Sentry.init({
// 高访问量应用可以控制上报百分比
tracesSampleRate: 0.3,
// 不同的环境上报到不同的 environment 分类
environment: process.env.ENVIRONMENT,
// 当前项目的 dsn 配置
dsn: 'https://[clientKey]@sentry.xxx.com/[id]',
// 追踪 vue 错误,上报 props,保留控制台错误输出
integrations: [new VueIntegration({ Vue, attachProps: true, logErrors: true })]
})可以看到的是 VueIntegration 增强上报了 Vue 组件的 props,同时我们还可以额外上报构建的版本信息 release。此时,Sentry 已经开始上报 console.error、ajax error、uncatch promise 等信息。同时,我们还可以进行主动上报、关联用户。
Sentry.captureException(err)
Sentry.setUser({ id: user.id })Sentry 还提供了基于 Webpack 的 plugin:webpack-sentry-plugin 帮助完成接入,就不再做介绍。
如何使用监控数据
进入某个具体的项目后,可以看到 Sentry 根据错误的 message、stack、发生位置进行归纳分类后的 Issue 列表:
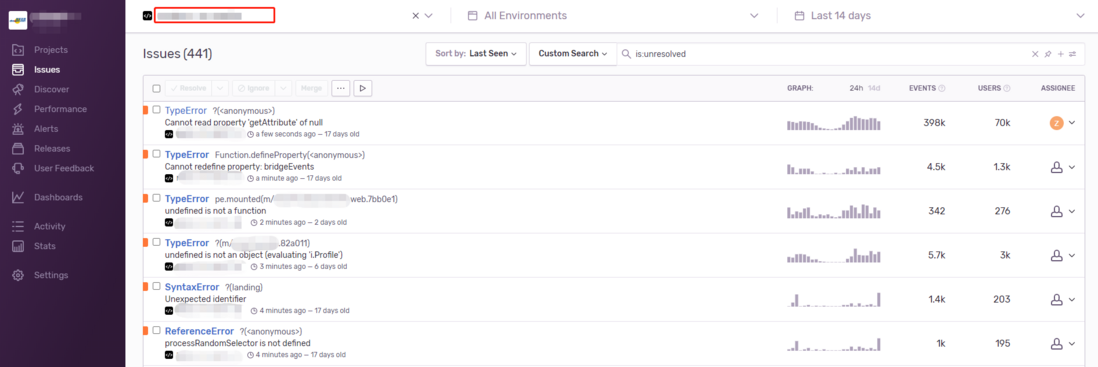
在右侧,可以看到每个错误的发生趋势、发生次数、影响用户数和指派给谁解决这个问题的按钮。我们可以通过这些指标进行错误处理的优先级分配和指派。
通过发展趋势,我们也可以观察到是否与某次上线有关,还可以通过左侧的 Discover 创建自定义的趋势看板,更有针对性的进行观察。
点击进入每个 issue 后,可以看到详细信息:

从上到下,可以看到错误的名称,发生的主要环境信息,Sentry 提取的错误特征,错误堆栈,在最下面的 BREADCRUMBS 中可以看到异常发生前的前置操作有哪些,可以帮助你进行问题操作步骤的还原,协助进行问题排查。
Sentry 的入门使用到此为止。其他的功能,如报警配置、性能监控可以自行探索。
作为智联招聘的前端架构团队,我们一直在寻找志同道合的前后端架构师和高级工程师,如果您也和我们一样热爱技术、热爱学习、热爱探索,就请加入我们吧!请将简历请发送至邮箱[email protected],或者微信扫码沟通。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK