

微服务化后的按需精细化资源控制
source link: http://servicecomb.apache.org/cn/docs/autoscale-on-company/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

微服务化后的按需精细化资源控制
少于 1 分钟 阅读
上文 介绍了在K8S上快速部署Company示例,本文将继续在K8S上演示使用K8S的弹性伸缩能力进行Company示例的按需精细化资源控制,以此体验微服务化给大家带来的好处。
K8S环境准备:
为使K8S具备弹性伸缩能力,需要先在K8S中安装监控器Heapster和Grafana:
具体读者踩了坑后更新的heapster的安装脚本作者放在:heapster,可直接获取下载获取,需要调整一个参数,后直接运行kube.sh脚本进行安装。
vi LinuxCon-Beijing-WorkShop/kubernetes/heapster/deploy/kube-config/influxdb/heapster.yaml
spec:
replicas: 1
template:
metadata:
labels:
task: monitoring
k8s-app: heapster
spec:
serviceAccountName: heapster
containers:
- name: heapster
image: gcr.io/google_containers/heapster-amd64:v1.4.1
imagePullPolicy: IfNotPresent
command:
- /heapster
#集群内安装直接使用kubernetes
- --source=kubernetes
#集群外安装请直接将下面的服务地址替换为k8s api server地址
# - --source=kubernetes:http://10.229.43.65:6443?inClusterConfig=false
- --sink=influxdb:http://monitoring-influxdb:8086
启动Company:
下载Comany支持弹性伸缩的代码:
git clone https://github.com/ServiceComb/ServiceComb-Company-WorkShop.git
cd LinuxCon-Beijing-WorkShop/kubernetes/
bash start-autoscale.sh
在Company的deployment.yaml中, 增加了如下限定资源的字段,这将限制每个pod被限制在200mill-core(1000毫core == 1 core)的cpu使用率以内。
resources:
limits:
cpu: 200m
在 start-autoscale.sh 中,对每个deployment创建HPA(pod水平弹性伸缩器)资源,限定每个pod的副本数弹性伸缩时控制在1到10之间,并限定每个pod的cpu占用率小于50%,结合前面限定了200mcore,故,每个pod的的平均cpu占用率会被HPA通过弹性伸缩能力控制在100mcore以内。
# Create Horizontal Pod Autoscaler
kubectl autoscale deployment zipkin --cpu-percent=50 --min=1 --max=10
kubectl autoscale deployment company-bulletin-board --cpu-percent=50 --min=1 --max=10
kubectl autoscale deployment company-worker --cpu-percent=50 --min=1 --max=10
kubectl autoscale deployment company-doorman --cpu-percent=50 --min=1 --max=10
kubectl autoscale deployment company-manager --cpu-percent=50 --min=1 --max=10
kubectl autoscale deployment company-beekeeper --cpu-percent=50 --min=1 --max=10
当运行start-autoscale.sh之后,具备弹性伸缩器的company已经被创建,可通过下面指令进行HPA的查询:
kubectl get hpa
启动压测:
export $HOST=<heapster-ip>:<heapster-port>
bash LinuxCon-Beijing-WorkShop/kubernetes/stress-test.sh
该脚本不断循环执行 1s内向Company请求计算 fibonacci 数值200次,对Company造成请求压力:
FIBONA_NUM=`curl -s -H "Authorization: $Authorization" -XGET "http://$HOST/worker/fibonacci/term?n=6"`
测试过程与结果
分别查看HPA状态以及Grafana,如下:
 图1 启动阶段
图1 启动阶段
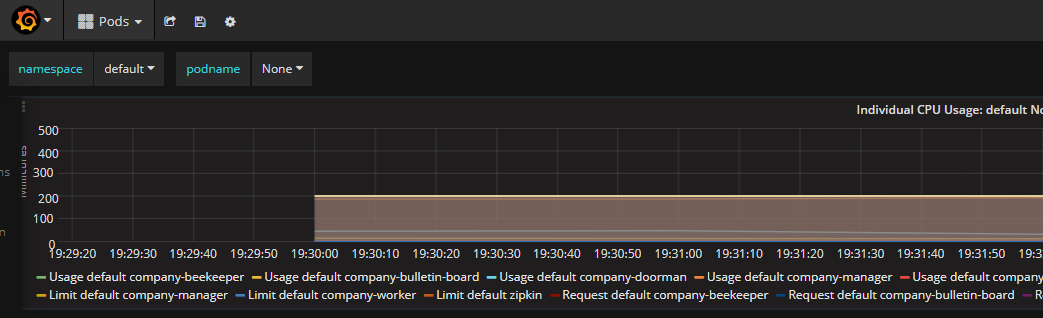 图2 启动阶段
图2 启动阶段
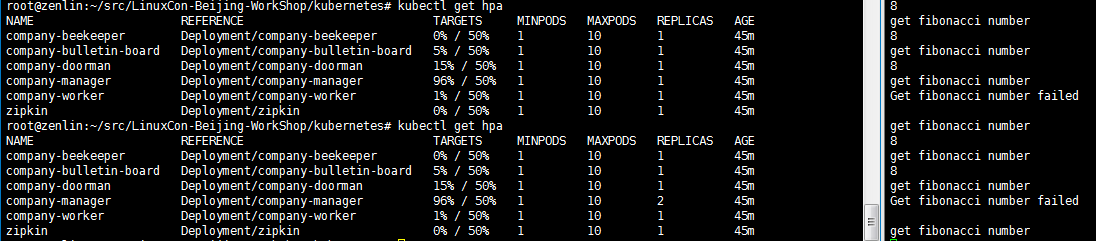 图3 过程
图3 过程
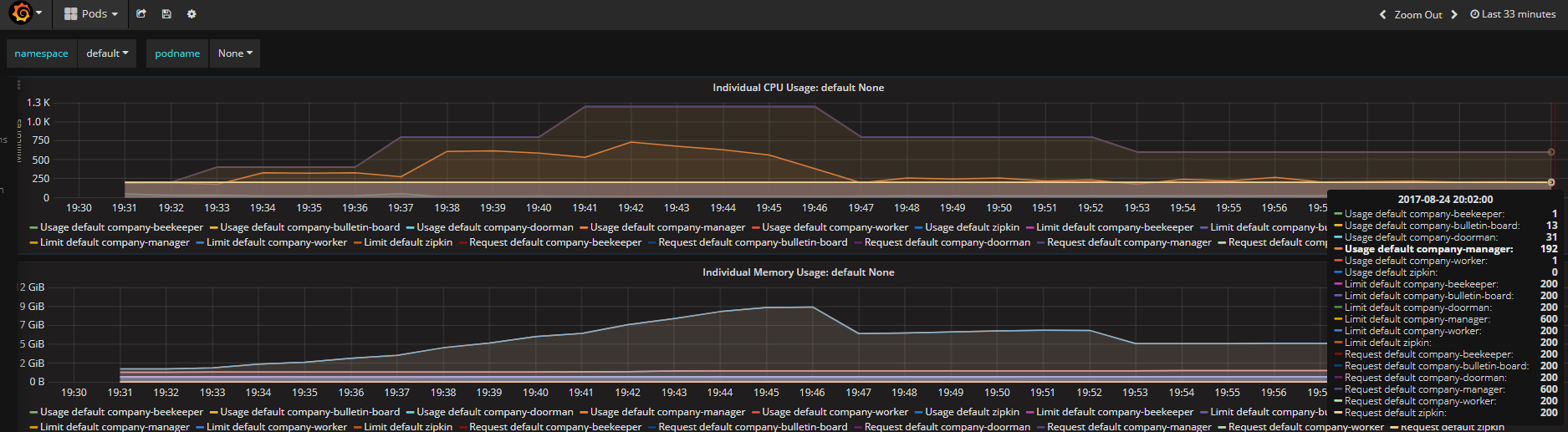 图4 结果
图4 结果
 图5 结果
图5 结果
从以上过程可以分析出,以下几点:
1. 压力主要集中在company-manager这个pod上,K8S的autoscaler通过弹性增加该pod的副本数量,最终达到目标:每个pod的cpu占用率低于限定值的50%(图5,Usage default company-manager/Request default company-manager = 192/600 约等于图4中的33%),并保持稳定。
2. 在弹性伸缩过程中,在还没稳定前可能造成丢包,如图3。
3. Company启动会导致系统资源负载暂时性加大,故Grafana上看到的cpu占用率曲线会呈现波峰状,但随着系统稳定运行后,HPA会按照系统的稳定资源消耗准确找到匹配的副本数。图3中副本数已超过实际所需3个,但随着系统稳定,最终还是稳定维持在3个副本。
4. 在HPA以及Grafana可以看到缩放和报告数据都会有延迟,按照官方文档说法,只有在最近3分钟内没有重新缩放的情况下,才会进行放大。 从最后一次重新缩放,缩小比例将等待5分钟。 而且,只有在avg/ Target降低到0.9以下或者增加到1.1以上(10%容差)的情况下,才可能会进行缩放。
以上,就是本次对Compan示例弹性伸缩的全过程,Martin Fowler 在2014年3月的文章中提到:
微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。系统中的各个微服务可被独立部署,各个微服务之间是松耦合的。每个微服务仅关注于完成一件任务并很好地完成该任务。在所有情况下,每个任务代表着一个小的业务能力。
国内实践微服务的先行者王磊先生也在《微服务架构与实践》一书中进行了全面论述。
Company使用ServiceComb进行微服务化改造后,具备了微服务的属性,故可以对单个负载较大的company-manager这个微服务进行精细化的控制,达到按需的目的,相比传统单体架构来讲,这将大大帮助准确有效地化解应用瓶颈,提高资源的利用效率。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK