

数据资产治理-元数据采集那点事
source link: https://tech.youzan.com/zi-chan-zhi-li-yuan-shu-ju-cai-ji-na-dian-shi/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

数据资产治理-元数据采集那点事
数据资产治理(详情见:数据资产,赞之治理)的前提要有数据。它要求数据类型全、量大,并尽可能多地覆盖数据流转的各个环节。元数据采集就变得尤其重要,它是数据资产治理的核心底座。
在早期的采集系统,我们主要面向数仓,通过“API直连方式”采集Hive/Mysql表的元数据。随着业务的快速发展,数据运营、成本治理的需求越来越强烈。元数据需要覆盖到数据全链路,包括离线计算平台、实时计算平台、内部工具,任务元数据等。 采集元数据的过程中,我们遇到以下困难:
数据类别多
需要采集组件的基础元数据、趋势数据、资源数据、任务数据和血缘数据。平台组件多
大数据平台组件:Hive/Hbase/Kafka/Druid/Flume/Flink/Presto,内部工具:BI报表系统/指标库/OneService等。采集周期长
接入新的数据类型周期长,需要经过需求评审、开发、测试、联调、数据核对、上线。
接入效率低,采集稳定性
接入每种数据类型需要和业务方对接,效率不高,采集过程出现异常中断,不能及时感知到。
本文主要从元数据的含义、元数据的提取、采集、监控告警几个方面,介绍我们做的一些事情。
二、元数据
2.1 什么是元数据
什么是元数据?元数据是“用来描述数据的数据”。举个例子:我拿手机拍摄了一张照片,查看照片的详情,如下所示信息:
照片信息
文件名:IMG_20201217_114115
时间:2020年12月17号 11:30:01
分辨率:4608X2592
文件大小:2.69MB
相机制造商:OnePlus
相机型号:ONEPLUS A5000
闪光灯:未使用闪光灯
焦距:4.10mm
白平衡:自动
光圈:f/1.7
曝光时间:1/50
ISO:1250
这些就是数码照片的元数据,用来描述一张图片。在资产治理平台中,我们采集Hive组件的元数据包含:表名称、字段列表、责任人、任务调度信息等。
收集全链路的数据(各类元数据),可以帮助数据平台回答:我们有哪些数据?有多少人在使用?数据存储是多少?如何查找这些数据?数据的流转是怎么样的?结合血缘关系进行问题溯源和影响分析。
2.2 采集了哪些元数据
如下图所示,是一张数据的流转图,我们主要采集了各个平台组件的:
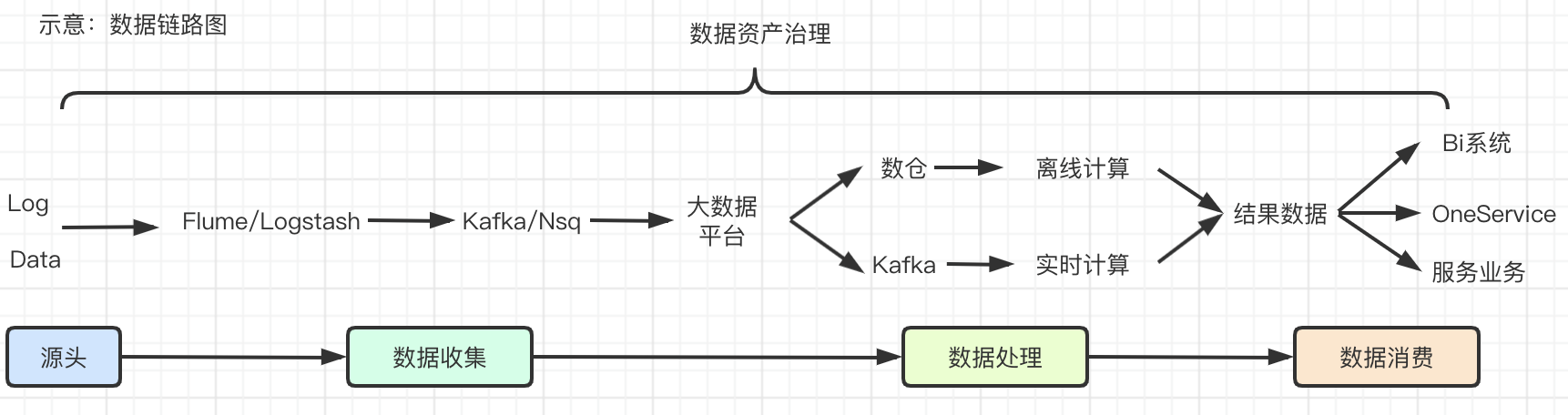
基础元数据
表名称、备注、字段列表、责任人、业务域、表所在集群、项目等信息。
-
表的大小、行数、文件数、分区数、任务调度时长、产出时间等信息。
-
集群的吞吐量、QPS、调度任务消耗Cpu、内存大小等信息。
-
表/字段级别的上下游依赖关系、任务的输入输出表依赖关系。
-
离线/实时计算任务的名称、责任人、deadline告警时间、脚本、任务配置等信息。
截至目前为止,采集到的平台组件覆盖了整个数据的链路。覆盖数据类型10种+,基础元数据的数量10w+。主要包括:
离线平台组件
Hive/Mysql。
-
Flume/Kafka/Hbase/Kylin/Es/Presto/Spark/Flink等。
-
BI报表系统、指标库系统、OneService、测试QA系统。
三、元数据提取
如何从众多平台组件提取元数据呢?大致有这几个方面:
访问Metastore获取基础元数据
一般的平台组件会把元数据存储在Mysql等关系型数据库中,通过访问Metastore获取基础的元数据。
获取组件集群资源数据
平台组件本身会提供Metrics和Alarm的监控服务,定期请求服务,把数据流入到Hbase/Opentsdb等存储。通过访问存储并对指标数据进行汇总统计,获取集群或任务的资源数据。
获取平台组件业务指标
数据中台内部有各种平台,比如KP(Kafka基础平台)、RP(Flink实时计算平台)、RDS(详情见:管理Mysql的工具平台)、DP(详情见:数据研发平台)。通过这些平台自身提供的服务获取基础元数据、业务监控指标、集群QPS、吞吐量等数据。
获取血缘数据
用户在DP平台、RP平台上开发计算任务,我们可以及时的获取发布的任务列表、任务的配置信息、SQL脚本等信息。
a. 计算任务
通过解析任务的输入/输出依赖配置,获取血缘关系。
b. SQL类型任务
通过“Sql Parser”(使用ANTLR4系统实现的sql改写工具)工具解析SQL脚本获取表/字段级别的血缘关系。
3.1 离线平台
主要是采集Hive/RDS表的元数据。
Hive组件的元数据存储在Metastore,通过JDBC的方式访问Mysql获取库表的元数据。根据Hive表信息组装成HDFS地址,通过FileSystem API获取文件的状态、文件数、文件大小、数据更新时间等趋势数据。
RDS平台提供了对Mysql服务的管理,通过平台提供的服务接口获取表的元数据、趋势数据、访问情况等信息。
3.2 实时平台
主要是Flume/Hbase/Kafka等组件的元数据。
举个例子:我们通过访问KP平台落盘的工单数据,获取topic的基础元数据信息,定时消费topic获取抽样数据,解析出字段列表。平台本身提供集群状态和业务监控指标,通过平台服务获取集群资源的使用情况。
3.3 内部工具
主要是BI报表系统(一张BI报表查询的Hive表、Mysql表关系)、指标库(指标关联的Hive表和字段关系)、OneService服务(接口访问哪些库表的关系数据)的血缘数据。
这些内部系统在产品不断迭代中积累了很多元数据。在不考虑元数据时效性的情况下,我们一般同步这些系统的数据到Hive库,经过离线处理得到元数据。
3.4 任务元数据
元数据任务主要是DP离线任务、Flink计算服务、Flume任务。
这些计算任务都有落盘,通过Binlog同步或离线同步的方式获取任务列表,得到任务的元数据。
四、数据采集
经过元数据提取,我们可以获取数据全链路中各个平台组件的元数据。数据采集指的是把这些元数据入库到数据资产管理系统的数据库中。
4.1 采集方式
采集数据主要有3种方式,下方表格列出了3种方式的优缺点。
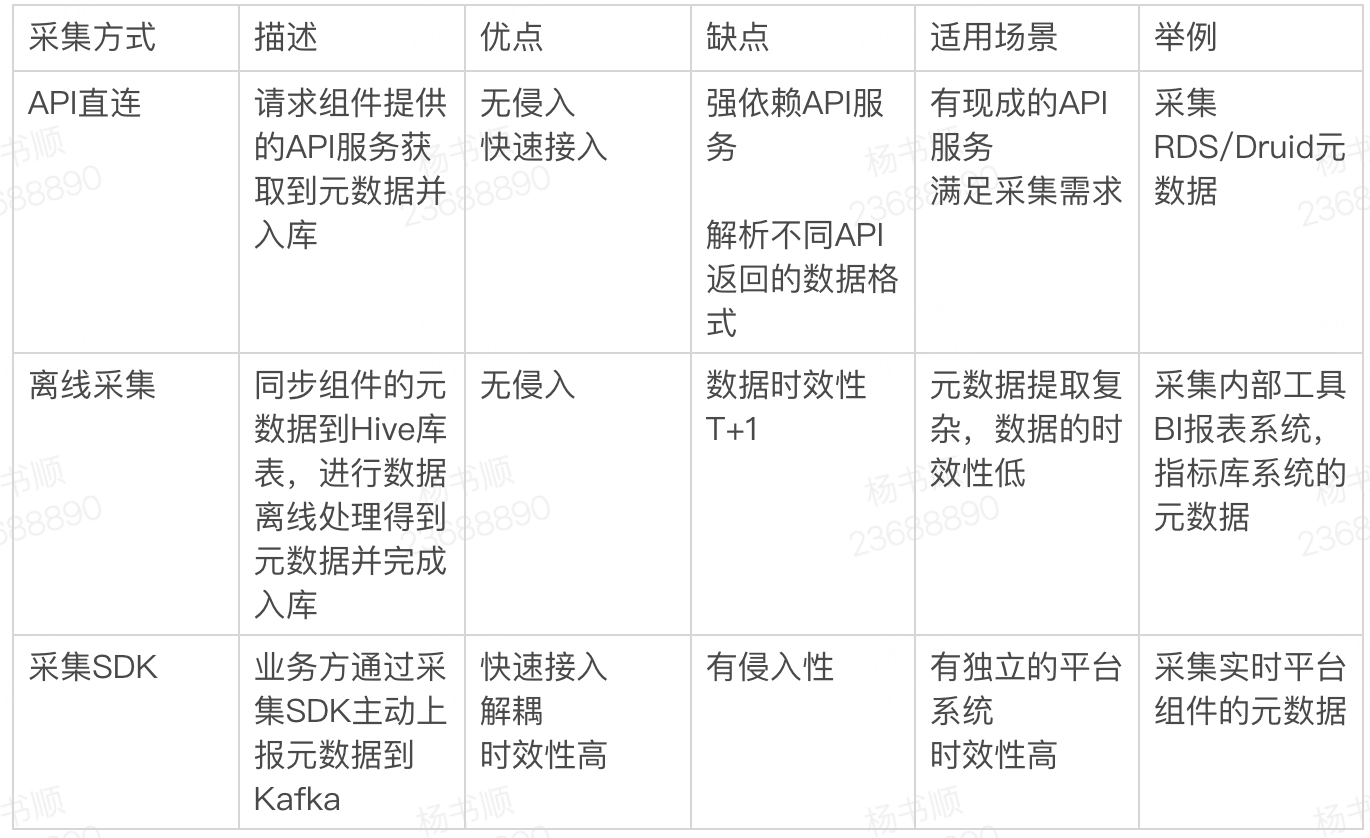
一般情况我们推荐业务方使用采集SDK。主动上报元数据,在接入时只需要关注上报的数据格式、SDK的初始化,就能快速完成上报工作。
4.2 采集SDK设计
采集SDK支持上报基础元数据、趋势数据、血缘数据,主要包括客户端SDK和采集服务端两部分。客户端SDK主要实现了通用上报模型的定义和上报功能,采集服务端主要实现了不同的适配器,完成数据的统一入库。
4.2.1 架构
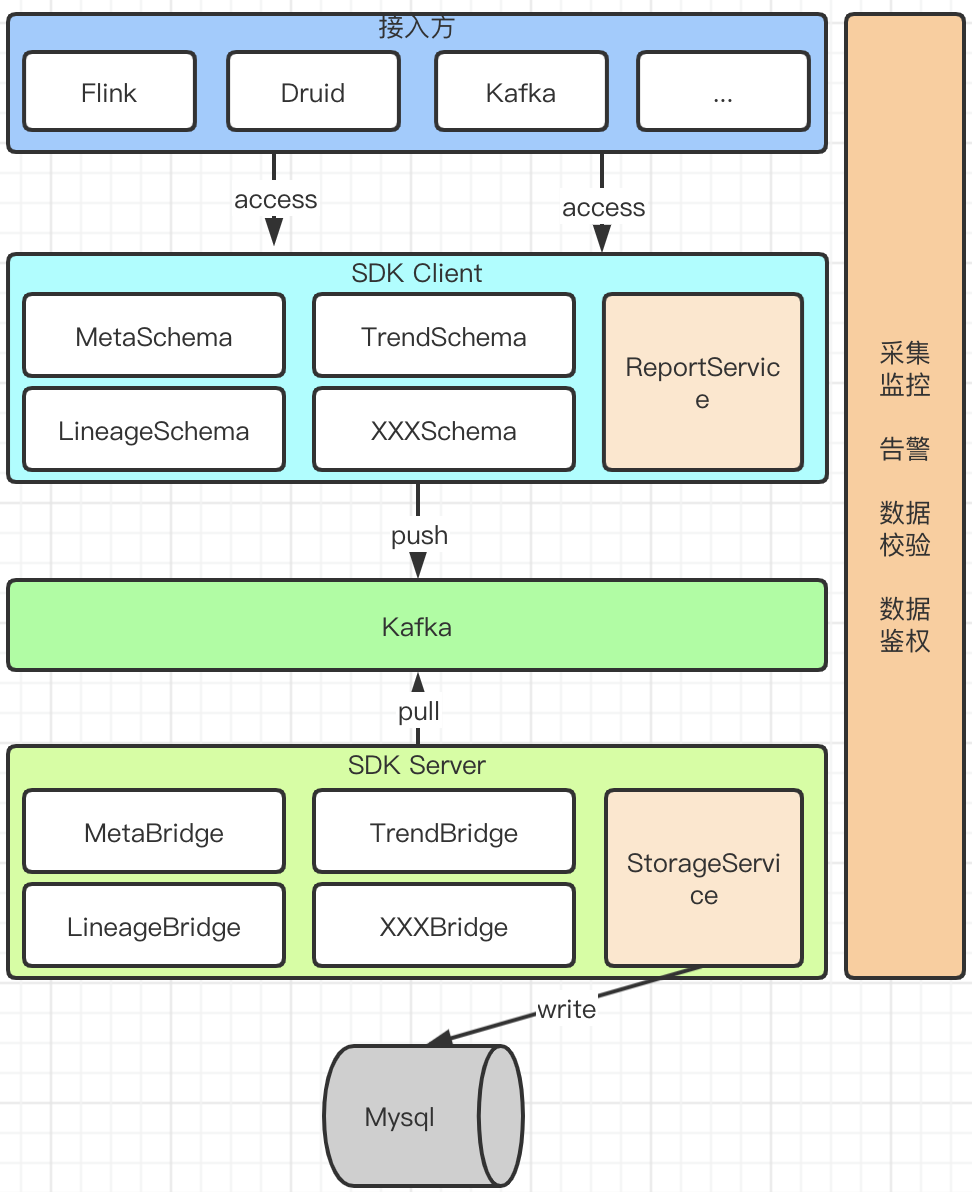
采集SDK客户端
定义了基础元数据(MetaSchema)、趋势数据(TrendSchema)、血缘数据(LineageSchema)的通用模型,支持扩展新的上报模型(XXXSchema)。ReportService实现了数据推送到Kafka的功能。
采集服务端
a. 数据鉴权
服务端消费kafka,获取到数据后,对每条记录的签名进行认证(取到记录中的appId、appName、token信息,重新生成token并比对值的过程)。
b. 统一入库服务
定义统一数据入库模型,包括表基础元数据、趋势数据、血缘数据、趋势数据并实现不同数据类型入库的服务。
c. 数据适配器Bridge
获取kafka的数据,根据不同的数据类型转换成“统一入库模型”,并触发“统一入库服务”完成数据的写入。
4.2.2 通用模型
采集的平台组件多,我们参照Hive“表模型”的定义,抽象出了一套通用的数据上报模型,保障了数据上报和数据存储的扩展性。
通用元数据模型
主要包括接入方信息、表基础信息、业务域信息、扩展信息。
通用趋势模型
主要包括表信息定义、趋势指标定义、扩展信息。
通用血缘模型
一张血缘图主要是由点、线组成的。点指的是表节点,边指的是任务节点;节点信息包括:节点名称、节点类型、节点扩展信息;表节点包括表基础信息,可以唯一确定一张表,任务节点包括任务的基础信息。
通用血缘模型主要包含表血缘模型定义、表任务血缘模型定义,支持用户单独上报表血缘、任务血缘。模型定义如下:
/**
* 表血缘模型定义
*/
@Data
public class TableLineageSchema<T extends TableNode> {
/**
* 当前节点
*/
private T current;
/**
* 父节点
*/
private List<T> parents;
/**
* 子节点
*/
private List<T> childs;
/**
* 表级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
/**
* 表任务血缘定义
*
*/
@Data
public class JobLineageSchema<Job extends JobNode, Table extends TableNode> {
/**
* 任务节点对象
*/
private Job task;
/**
* 输入对象列表
*/
private List<Table> inputs;
/**
* 输出对象列表
*/
private List<Table> outputs;
/**
* 任务级别血缘扩展信息,json对象,kv结构
*/
private String extParam;
}
每种模型定义留有扩展字段(约定json格式),不在定义中的指标可以放在扩展字段,上报数据后,也会被存储在元数据表的扩展字段中。接入新的类型,指标定义差异性较大,通过扩展新的数据模型定义,完成元数据的上报。
4.2.3 接入,校验,限流
如何保障用户上报的数据是安全的?我们设计了一组签名:接入方Id(appId)、接入名称(appName)、接入标识(token)。管理员填写基础的接入方信息即可生成随机的appId、token信息。业务方在初始化采集SDK时,指定签名信息,上报的每条数据会携带签名。在采集服务端,会对每条数据进行签名认证,这样保障了数据的安全性。
采集SDK会对上报的每条数据执行通用规则,检查数据的合法性,比如表名称不为空、责任人有效性、表大小、趋势数据不能为负数等。检查出非法数据会过滤掉并触发告警通知。
在采集SDK服务端,定时(每隔两秒)消费Kafka一批数据,支持设置消费数据的时间间隔和拉取条数,不会因为上报数据的流量波峰导致下游入库压力变大,起到了限流的作用。
4.3 触发采集
我们支持了元数据的多种采集方式,如何触发数据的采集呢?整体的思路是:
增量采集变更的数据
定期采集全量的数据
实时采集SDK上报的数据
基于阿波罗配置系统(详见:Apollo在有赞的实践)和Linux系统的Crontab功能,实现了任务的定时调度。数据采集任务配置在阿波罗上,变更配置后发布阿波罗,实时同步配置信息到线上节点的Crontab文件中。
4.3.1 增量任务,准实时
支持获取组件最近变更的元数据,配置增量任务,提升元数据采集的实时性。 比如增量采集Hive表元数据,每隔1分钟查询metastore获取最近变更的元数据列表,更新元数据。
4.3.2 全量任务,兜底
增量采集可能存在丢数据的场景,每隔1天或多天全量采集一次,作为兜底方案保障元数据的完整性。
4.3.3 采集SDK,实时上报
采集SDK支持实时和全量上报模式,一般要求接入方数据变更后实时上报,同时不定期全量上报一次。
4.4 数据存储,更新
数据采集后,要考虑如何存储、元数据发生变更如何同步更新。我们对采集过来的元数据进行分类归一,抽象出“表模型”,分类存储。
4.4.1 数据存储
我们评估了每种组件的元数据数量(总量10w+)、预估数据可能的使用场景,最终选择Mysql存储。为了满足用户的个性化查询需求,构建Es宽表。以表粒度为主包括:表名称、备注、责任人、字段列表、趋势信息、业务域信息、任务信息等。数据采集过程中同步更新Es表保障了元数据查询的实时性,定期(构建离线模型表,每天同步更新Es表)全量更新一次,保障了元数据的完整性。
元数据中的表不是孤立存在的,一般有关联的任务(离线任务,实时任务)产出表,数据地图中也会展示表和任务的流转关系。那么在众多的平台组件中,如何唯一的区分出一张表呢?我们是通过集群名称、项目名称、表类型(来自哪个平台组件)、表名称这几个字段的组合来唯一区分。
数据分类存储最终形成:基础元数据表、趋势数据表、任务元数据表、血缘数据表。
4.4.2 数据更新
元数据表下线了,如何同步更新呢?
全量采集,找差异
全量采集时,获取平台组件的所有元数据,和资产数据库中的元数据表做全量比对,找出差异的表并设置下线。
增量采集,走约定
增量采集时,与接入方约定:已下线的表不上报,3天未更新的元数据平台会进行定期清理。
五、监控预警
完成了数据的采集,是不是就大功告成了?答案是否定的。采集过程中数据类型多、方式多样、链路长,任何一个环节出现问题就会导致结果的不准确。我们通过以下方式保障采集服务的稳定性。
5.1 采集链路监控告警
5.1.1 接口监控
我们把系统所有的服务接口划分为三个等级:核心、重要、一般,并支持注解的方式打标接口和责任人,发生异常触发不同程度的告警通知。核心服务异常直接触发电话告警,重要或一般服务异常触发邮件告警。系统会存储接口请求和执行的状态,每天定时向接口服务的责任人发送服务日报。我们将元数据的采集服务标记为核心和重要服务,对“API直连方式”的接口做到了异常感知。
如下所示,是服务接口的告警通知:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[重要]等级问题, 方法名:[com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb], 异常信息:null
host:XXXXXX
处理地址:https://XXXX
如下所示,是服务接口的告警日报:
[Warning][prod][data-dict] - 数据资产平台告警
[shunfengche]今日问题汇总
请及时收敛今日问题,总问题数 1 个,出现 2 次
【核心】问题 0 个:
【重要】问题 0 个:
【一般】问题 1 个:
[数据采集]com.youzan.bigdata.crystal.controller.HiveMetaController.getHiveDb 今日出现 2 次, 已存在 5 天, 历史出现 8 次
host:XXXXXX
处理地址:https://XXXX
5.1.2 采集过程监控
针对每个元数据采集服务,采集过程发生异常则发送告警通知。
如下所示,是采集过程发生异常触发的告警:
[Warning][prod][data-dict] - 数据资产平台告警
你负责的[元信息采集]模块(backup为XXX)出现[一般]等级问题, 方法名:[com.youzan.bigdata.crystal.asyncworker.work.AsyncAllRdsDDLWorker.run], 异常信息:/n
### Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLQueryInterruptedException: Query execution was interrupted
5.1.3 kafka消息积压告警
消费kafka数据,通过kp平台配置消息积压告警,针对采集SDK服务做到了异常感知。
5.2 结果数据比对
主要是事后监控预警,定时探查采集的元数据数量异常波动。对不同类型的元数据,通过比较当日采集的数量和近7天历史平均的数量,设定异常波动告警阈值,超过阈值触发告警通知。
针对采集的元数据结果表,配置一些数据质量探查规则,定时执行异常规则发现问题数据触发告警通知。这样保障了对结果数据的异常感知。比如已定义的数据质量规则:
表责任人:离职人员或特殊责任人(表的责任人是app,admin等)数量。
血缘:无关联的任务,无上下游的表数量。
趋势数据:表趋势值非法(默认值-1)的数量。
业务域:表所属的业务域值为-1(非法值)的数量。
5.3 项目迭代机制,采集问题收敛
经过事前、事中、事后的监控告警机制,能够及时发现并感知采集异常。对异常问题,我们一般以项目迭代的方式,发起jira,组织关联人复盘。追溯根因,讨论改进方案,产出action,定期关注并持续做到问题的收敛。
六、总结和展望
6.1 总结
我们定义了一套通用的数据采集和存储模型,支持接入不同数据类型的元数据,支持多种接入方式,采集SDK提升了接入效率和数据的时效性。 如下图所示,目前已接入了各种组件的元数据,并对数据分类统一管理,提供数据字典、数据地图、资产大盘、全域成本账单等元数据的应用。
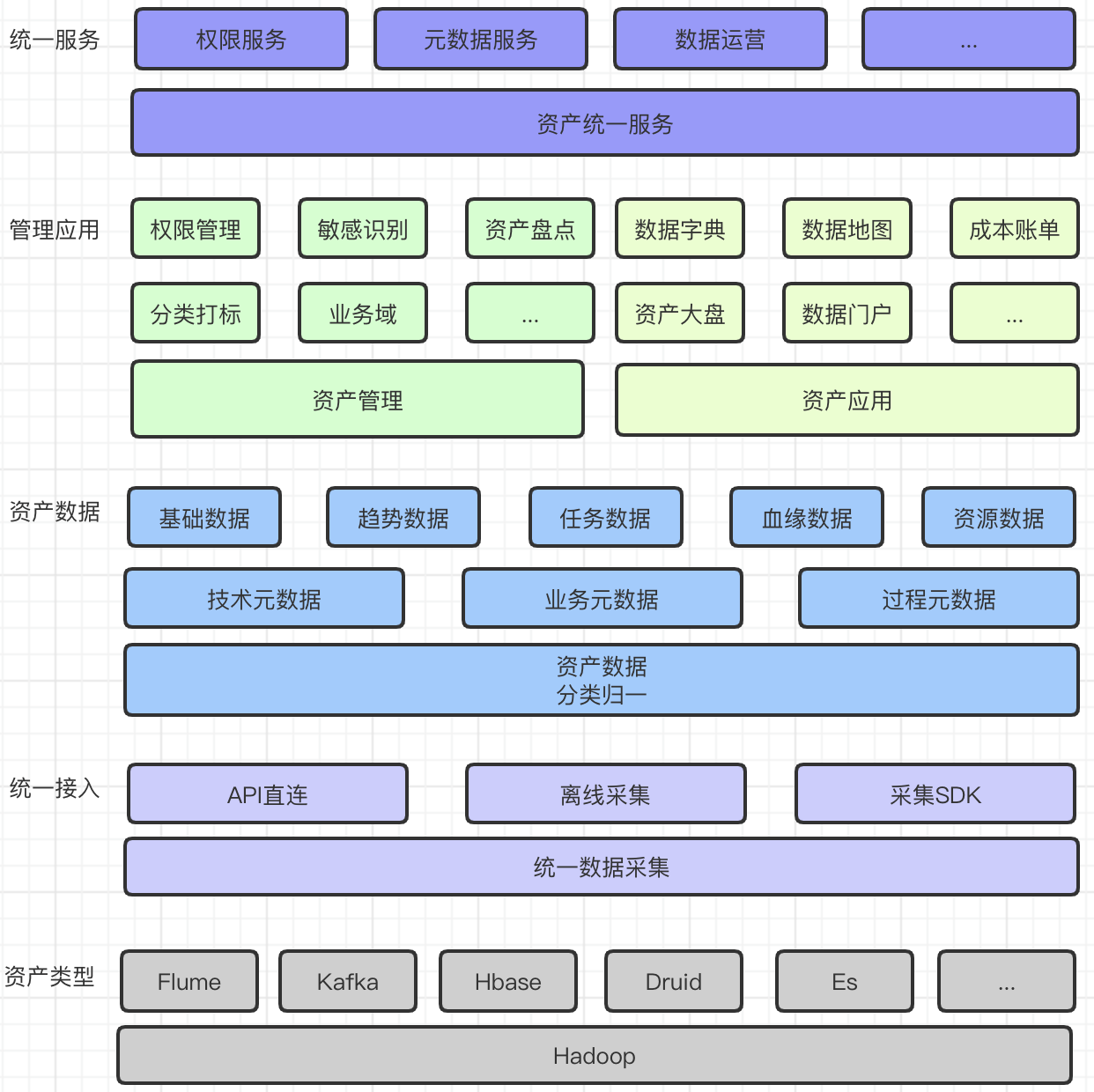
如果把数据资产治理比作建设高楼大厦,那么不同组件的元数据就是原材料,数据采集就是地基。只有地基打得牢固,数据治理这座大厦才会越建越稳。
6.2 展望
数据采集的过程中我们也遇到很多的问题,在后续的工作中需要不断的优化和功能迭代,包括但不限于:
自动化采集
接入新的数据类型,需要和接入方确认数据上报格式,编写数据适配器,后续考虑自动化采集,减少人工介入。接入工单系统,接入方发起工单申请,填报基础的元数据信息,管理员审批后,能够根据工单信息自动生成数据适配器,完成数据的上报。
采集任务管理
目前接入了各种组件的元数据,采集任务数25+,新增采集任务或任务下线,需要走阿波罗配置系统。采集任务管理、搜索、任务启停需求越来越强烈。
提升元数据质量
接入的元数据类型、元数据服务越来越多,对元数据的质量提出了更高的要求,如何保障数据的准确性、可用性,是后续重点要考虑的事情。·
支持业务元数据接入
目前主要接入了数据平台组件的元数据,业务方元数据占比较小,后续考虑支持快速接入业务数据,支持非结构化数据的采集和存储。
最后,有赞数据中台,长期招聘基础组件、平台研发、数据仓库、数据产品、算法等方面的人才。欢迎加入我们,一起enjoy~ 简历投递邮箱:[email protected]。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK