

[PyTorch 学习笔记] 6.1 weight decay 和 dropout
source link: https://zhuanlan.zhihu.com/p/225606205
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

[PyTorch 学习笔记] 6.1 weight decay 和 dropout
本章代码:
这篇文章主要介绍了正则化与偏差-方差分解,以及 PyTorch 中的 L2 正则项--weight decay
Regularization
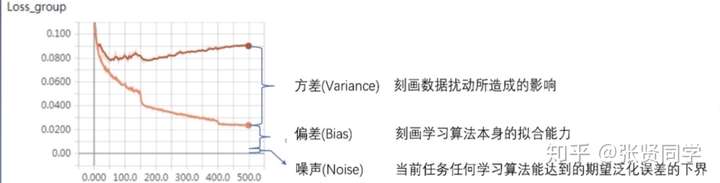
Regularization 中文是正则化,可以理解为一种减少方差的策略。
在机器学习中,误差可以分解为:偏差,方差与噪声之和。即误差=偏差+方差+噪声
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力。
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
噪声则表达了在当前任务上学习任何算法所能达到的期望泛化误差的下界。
正则化方式有 L1 和 L2 正则项两种。其中 L2 正则项又被称为权值衰减(weight decay)。
当没有正则项时:,
。
当使用 L2 正则项时,,
,其中
,所以具有权值衰减的作用。
在 PyTorch 中,L2 正则项是在优化器中实现的,在构造优化器时可以传入 weight decay 参数,对应的是公式中的 。
下面代码对比了没有 weight decay 的优化器和 weight decay 为 0.01 的优化器的训练情况,在线性回归的数据集上进行实验,模型使用 3 层的全连接网络,并使用 TensorBoard 可视化每层权值的变化情况。代码如下:
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from common_tools import set_seed
from tensorboardX import SummaryWriter
set_seed(1) # 设置随机种子
n_hidden = 200
max_iter = 2000
disp_interval = 200
lr_init = 0.01
# ============================ step 1/5 数据 ============================
def gen_data(num_data=10, x_range=(-1, 1)):
w = 1.5
train_x = torch.linspace(*x_range, num_data).unsqueeze_(1)
train_y = w*train_x + torch.normal(0, 0.5, size=train_x.size())
test_x = torch.linspace(*x_range, num_data).unsqueeze_(1)
test_y = w*test_x + torch.normal(0, 0.3, size=test_x.size())
return train_x, train_y, test_x, test_y
train_x, train_y, test_x, test_y = gen_data(x_range=(-1, 1))
# ============================ step 2/5 模型 ============================
class MLP(nn.Module):
def __init__(self, neural_num):
super(MLP, self).__init__()
self.linears = nn.Sequential(
nn.Linear(1, neural_num),
nn.ReLU(inplace=True),
nn.Linear(neural_num, neural_num),
nn.ReLU(inplace=True),
nn.Linear(neural_num, neural_num),
nn.ReLU(inplace=True),
nn.Linear(neural_num, 1),
)
def forward(self, x):
return self.linears(x)
net_normal = MLP(neural_num=n_hidden)
net_weight_decay = MLP(neural_num=n_hidden)
# ============================ step 3/5 优化器 ============================
optim_normal = torch.optim.SGD(net_normal.parameters(), lr=lr_init, momentum=0.9)
optim_wdecay = torch.optim.SGD(net_weight_decay.parameters(), lr=lr_init, momentum=0.9, weight_decay=1e-2)
# ============================ step 4/5 损失函数 ============================
loss_func = torch.nn.MSELoss()
# ============================ step 5/5 迭代训练 ============================
writer = SummaryWriter(comment='_test_tensorboard', filename_suffix="12345678")
for epoch in range(max_iter):
# forward
pred_normal, pred_wdecay = net_normal(train_x), net_weight_decay(train_x)
loss_normal, loss_wdecay = loss_func(pred_normal, train_y), loss_func(pred_wdecay, train_y)
optim_normal.zero_grad()
optim_wdecay.zero_grad()
loss_normal.backward()
loss_wdecay.backward()
optim_normal.step()
optim_wdecay.step()
if (epoch+1) % disp_interval == 0:
# 可视化
for name, layer in net_normal.named_parameters():
writer.add_histogram(name + '_grad_normal', layer.grad, epoch)
writer.add_histogram(name + '_data_normal', layer, epoch)
for name, layer in net_weight_decay.named_parameters():
writer.add_histogram(name + '_grad_weight_decay', layer.grad, epoch)
writer.add_histogram(name + '_data_weight_decay', layer, epoch)
test_pred_normal, test_pred_wdecay = net_normal(test_x), net_weight_decay(test_x)
# 绘图
plt.scatter(train_x.data.numpy(), train_y.data.numpy(), c='blue', s=50, alpha=0.3, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='red', s=50, alpha=0.3, label='test')
plt.plot(test_x.data.numpy(), test_pred_normal.data.numpy(), 'r-', lw=3, label='no weight decay')
plt.plot(test_x.data.numpy(), test_pred_wdecay.data.numpy(), 'b--', lw=3, label='weight decay')
plt.text(-0.25, -1.5, 'no weight decay loss={:.6f}'.format(loss_normal.item()), fontdict={'size': 15, 'color': 'red'})
plt.text(-0.25, -2, 'weight decay loss={:.6f}'.format(loss_wdecay.item()), fontdict={'size': 15, 'color': 'red'})
plt.ylim((-2.5, 2.5))
plt.legend(loc='upper left')
plt.title("Epoch: {}".format(epoch+1))
plt.show()
plt.close()
训练 2000 个 epoch 后,模型如下:
可以看到使用了 weight decay 的模型虽然在训练集的 loss 更高,但是更加平滑,泛化能力更强。
下面是使用 Tensorboard 可视化的分析。首先查看不带 weight decay 的权值变化过程,第一层权值变化如下:
可以看到从开始到结束,权值的分布都没有什么变化。
然后查看带 weight decay 的权值变化过程,第一层权值变化如下:
可以看到,加上了 weight decay 后,随便训练次数的增加,权值的分布逐渐靠近 0 均值附近,这就是 L2 正则化的作用,约束权值尽量靠近 0。
第二层不带 weight decay 的权值变化如下:
第二层带 weight decay 的权值变化如下:
weight decay 在 优化器中的实现
由于 weight decay 在优化器的一个参数,因此在执行optim_wdecay.step()时,会计算 weight decay 后的梯度,具体代码如下:
def step(self, closure=None):
"""Performs a single optimization step.
Arguments:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
"""
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad.data
if weight_decay != 0:
d_p.add_(weight_decay, p.data)
...
...
...
p.data.add_(-group['lr'], d_p)
可以看到:dp 是计算得到的梯度,如果 weight decay 不为 0,那么更新 ,对应公式:$\left(\frac{\partial L o s s}{\partial w{i}}+\lambda * w_{i}\right)$。最后一行是根据梯度更新权值。
Dropout
Dropout 是另一种抑制过拟合的方法。在使用 dropout 时,数据尺度会发生变化,如果设置 dropout_prob =0.3,那么在训练时,数据尺度会变为原来的 70%;而在测试时,执行了 model.eval() 后,dropout 是关闭的,因此所有权重需要乘以 (1-dropout_prob),把数据尺度也缩放到 70%。
PyTorch 中 Dropout 层如下,通常放在每个网路层的最前面:
torch.nn.Dropout(p=0.5, inplace=False)
- p:主力需要注意的是,p 是被舍弃的概率,也叫失活概率
下面实验使用的依然是线性回归的例子,两个网络均是 3 层的全连接层,每层前面都设置 dropout,一个网络的 dropout 设置为 0,另一个网络的 dropout 设置为 0.5,并使用 TensorBoard 可视化每层权值的变化情况。代码如下:
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from common_tools import set_seed
from tensorboardX import SummaryWriter
set_seed(1) # 设置随机种子
n_hidden = 200
max_iter = 2000
disp_interval = 400
lr_init = 0.01
# ============================ step 1/5 数据 ============================
def gen_data(num_data=10, x_range=(-1, 1)):
w = 1.5
train_x = torch.linspace(*x_range, num_data).unsqueeze_(1)
train_y = w*train_x + torch.normal(0, 0.5, size=train_x.size())
test_x = torch.linspace(*x_range, num_data).unsqueeze_(1)
test_y = w*test_x + torch.normal(0, 0.3, size=test_x.size())
return train_x, train_y, test_x, test_y
train_x, train_y, test_x, test_y = gen_data(x_range=(-1, 1))
# ============================ step 2/5 模型 ============================
class MLP(nn.Module):
def __init__(self, neural_num, d_prob=0.5):
super(MLP, self).__init__()
self.linears = nn.Sequential(
nn.Linear(1, neural_num),
nn.ReLU(inplace=True),
nn.Dropout(d_prob),
nn.Linear(neural_num, neural_num),
nn.ReLU(inplace=True),
nn.Dropout(d_prob),
nn.Linear(neural_num, neural_num),
nn.ReLU(inplace=True),
nn.Dropout(d_prob),
nn.Linear(neural_num, 1),
)
def forward(self, x):
return self.linears(x)
net_prob_0 = MLP(neural_num=n_hidden, d_prob=0.)
net_prob_05 = MLP(neural_num=n_hidden, d_prob=0.5)
# ============================ step 3/5 优化器 ============================
optim_normal = torch.optim.SGD(net_prob_0.parameters(), lr=lr_init, momentum=0.9)
optim_reglar = torch.optim.SGD(net_prob_05.parameters(), lr=lr_init, momentum=0.9)
# ============================ step 4/5 损失函数 ============================
loss_func = torch.nn.MSELoss()
# ============================ step 5/5 迭代训练 ============================
writer = SummaryWriter(comment='_test_tensorboard', filename_suffix="12345678")
for epoch in range(max_iter):
pred_normal, pred_wdecay = net_prob_0(train_x), net_prob_05(train_x)
loss_normal, loss_wdecay = loss_func(pred_normal, train_y), loss_func(pred_wdecay, train_y)
optim_normal.zero_grad()
optim_reglar.zero_grad()
loss_normal.backward()
loss_wdecay.backward()
optim_normal.step()
optim_reglar.step()
if (epoch+1) % disp_interval == 0:
net_prob_0.eval()
net_prob_05.eval()
# 可视化
for name, layer in net_prob_0.named_parameters():
writer.add_histogram(name + '_grad_normal', layer.grad, epoch)
writer.add_histogram(name + '_data_normal', layer, epoch)
for name, layer in net_prob_05.named_parameters():
writer.add_histogram(name + '_grad_regularization', layer.grad, epoch)
writer.add_histogram(name + '_data_regularization', layer, epoch)
test_pred_prob_0, test_pred_prob_05 = net_prob_0(test_x), net_prob_05(test_x)
# 绘图
plt.scatter(train_x.data.numpy(), train_y.data.numpy(), c='blue', s=50, alpha=0.3, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='red', s=50, alpha=0.3, label='test')
plt.plot(test_x.data.numpy(), test_pred_prob_0.data.numpy(), 'r-', lw=3, label='d_prob_0')
plt.plot(test_x.data.numpy(), test_pred_prob_05.data.numpy(), 'b--', lw=3, label='d_prob_05')
plt.text(-0.25, -1.5, 'd_prob_0 loss={:.8f}'.format(loss_normal.item()), fontdict={'size': 15, 'color': 'red'})
plt.text(-0.25, -2, 'd_prob_05 loss={:.6f}'.format(loss_wdecay.item()), fontdict={'size': 15, 'color': 'red'})
plt.ylim((-2.5, 2.5))
plt.legend(loc='upper left')
plt.title("Epoch: {}".format(epoch+1))
plt.show()
plt.close()
net_prob_0.train()
net_prob_05.train()
训练 2000 次后,模型的曲线如下:
我们使用 TensorBoard 查看第三层网络的权值变化情况。
dropout =0 的权值变化如下:
dropout =0.5 的权值变化如下:
可以看到,加了 dropout 之后,权值更加集中在 0 附近,使得神经元之间的依赖性不至于过大。
model.eval() 和 model.trian()
有些网络层在训练状态和测试状态是不一样的,如 dropout 层,在训练时 dropout 层是有效的,但是数据尺度会缩放,为了保持数据尺度不变,所有的权重需要除以 1-p。而在测试时 dropout 层是关闭的。因此在测试时需要先调用model.eval()设置各个网络层的的training属性为 False,在训练时需要先调用model.train()设置各个网络层的的training属性为 True。
下面是对比 dropout 层的在 eval 和 train 模式下的输出值。
首先构造一层全连接网络,输入是 10000 个神经元,输出是 1 个神经元,权值全设为 1,dropout 设置为 0.5。输入是全为 1 的向量。分别测试网络在 train 模式和 eval 模式下的输出,代码如下:
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self, neural_num, d_prob=0.5):
super(Net, self).__init__()
self.linears = nn.Sequential(
nn.Dropout(d_prob),
nn.Linear(neural_num, 1, bias=False),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.linears(x)
input_num = 10000
x = torch.ones((input_num, ), dtype=torch.float32)
net = Net(input_num, d_prob=0.5)
net.linears[1].weight.detach().fill_(1.)
net.train()
y = net(x)
print("output in training mode", y)
net.eval()
y = net(x)
print("output in eval mode", y)
输出如下:
output in training mode tensor([9868.], grad_fn=<ReluBackward1>)
output in eval mode tensor([10000.], grad_fn=<ReluBackward1>)
在训练时,由于 dropout 为 0.5,因此理论上输出值是 5000,而由于在训练时,dropout 层会把权值除以 1-p=0.5,也就是乘以 2,因此在 train 模式的输出是 10000 附近的数(上下随机浮动是由于概率的不确定性引起的) 。而在 eval 模式下,关闭了 dropout,因此输出值是 10000。这种方式在训练时对权值进行缩放,在测试时就不用对权值进行缩放,加快了测试的速度。
参考资料
如果你觉得这篇文章对你有帮助,不妨点个赞,让我有更多动力写出好文章。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK