

厉害了!打工人用Python分析西安市职位信息
source link: https://blog.yuanpei.me/posts/2147036181/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

厉害了!打工人用Python分析西安市职位信息
在上一篇博客中,我和大家分享了整个11月份找工作的心路历程,而在找工作的过程中,博主发现西安大小周、单休这种变相“996”的公司越来越多,感慨整个行业越来越“内卷”的同时,不免会对未来的人生有一点迷茫,因为深圳已经开始试运行“996”了,如果有一天“996”被合法化并成为一种常态,那么,我们又该如何去面对“人会一天天衰老,总有一天肝不动”的客观规律呢?我注意到Boss直聘移动端会展示某个公司的作息时间,所以,我有了抓取西安市职位和公司信息并对其进行数据分析的想法,我想知道,这到底是我一个人的感受呢?还是整个世界的确是这样子的呢?带着这样的想法,博主有了今天这篇博客。所以,在今天这篇博客里,博主会从Boss直聘、智联招聘以及前程无忧上抓取职位和公司信息,并使用MongoDB对数据进行持久化,最终通过pyecharts对结果进行可视化展示。虽然不大确定2021年会不会变得更好,可生活最迷人的地方就在于它的不确定性,正如数据分析唯一可以做的,就是帮助我们从变化的事物中挖掘出不变的规律一样。
其实,这种类似的数据分析,博主此前做过挺多的啦,譬如 基于Python实现的微信好友数据分析 以及 基于新浪微博的男女性择偶观数据分析(下) 这两篇博客。总体上来说,大部分学习Python的朋友都是从编写爬虫开始的,而在博主看来,数据分析是最终的目的,编写爬虫则是达到这一目的的手段。而从始至终,“爬”与“反爬”的较量从未停止过,Requests、BeautifulSoup、Selenium、Phantom等等的技术层出不穷。考虑到现在编写爬虫存在风险,所以,我不会在博客里透露过多的“爬虫”细节,换言之,我不想成为一个教别人写爬虫的人,因为这篇博客的标签是数据分析,关于爬虫的部分,我点到为止,不再过多地去探讨它的实现,希望大家理解。而之所以要从这三个招聘网站上抓取,主要还是为了增加样本的多样性,因为Boss直聘上西安市的职位居然只有3页,这实在是太让人费解了!
Boss直聘
通过抓包,我们可以分析出Boss直聘的地址:https://www.zhipin.com/job_detail/?query={query}&city={cityCode}&industry=&position=&page={page}。其中,query为待查询关键词,cityCode为待查询城市代码,page为待查询的页数。可以注意到,industry和position两个参数没有维护,它们分别表示待查询的行业和待查询的职称。因为我们面向的是更一般的“打工人”,所以,这些都可以进行简化。对于cityCode这个参数,我们可以通过下面的接口获得:https://www.zhipin.com/wapi/zpCommon/data/city.json。这里,简单定义一个方法extractCity()来提取城市代码:
def extractCity(self, cityName=None):
if (os.path.exists('bossCity.json') and cityName != None):
with open('bossCity.json', 'rt', encoding='utf-8') as fp:
cityList = json.load(fp)
for city in cityList:
if (city['name'] == cityName):
return city['code']
else:
response = requests.get(self.cityUrl)
response.raise_for_status()
json_data = response.json();
if (json_data['code'] == 0 and json_data['zpData'] != None):
cityList = []
for level in json_data['zpData']['cityList']:
cityList.extend(self.unfoldLevel(level))
with open('bossCity.json', 'wt', encoding='utf-8') as fp:
json.dump(cityList, fp)
if (cityName != None):
for city in cityList:
if (city['name'] == cityName):
return city['code']
else:
return json_data['zpData']['locationCity']['code']
接下来,我们可以编写searchJobs()方法来实现职位的检索:
def searchJobs(self, cityName, query, page=1):
cityCode = self.extractCity(cityName)
if (cityCode != None):
searchUrl = 'https://www.zhipin.com/job_detail/?query={query}&city={cityCode}&industry=&position=&page={page}'.format(cityCode=cityCode, query=query, page=str(page))
html = self.makeRequest(searchUrl)
soup = BeautifulSoup(html)
details = soup.find_all(name='div',attrs={'class','job-primary'})
jobItems = []
companyItems = []
for detail in details:
jobItem = self.extractJob(detail)
if (jobItem == None):
continue
else:
jobItems.append(jobItem)
companyItem = self.extractCompany(detail)
if (companyItem == None):
continue
else:
jobItem['company'] = companyItem['title']
jobItem['industry'] = companyItem['industry']
companyItems.append(companyItem)
return (jobItems,companyItems)
这里我们会用到requests、fake_useragent以及BeautifulSoup,如果你经常编写爬虫的话,对它们应当不会感到陌生。唯一需要注意的有两点:第一,Boss直聘会封杀爬虫的IP,所以,可以考虑从互联网上抓取免费的代理IP作为代理池,每次发起请求时随机选取一个IP作为代理IP,这样可以有效地减少被封杀的可能。第二,Boss直聘的Cookie最多只能使用4次,超过4次后就需要重新获取Cookie。目前,我没有找到好的解决方案,有兴趣的朋友可以参考 2019年末逆向复习系列之Boss直聘Cookie加密字段zp_stoken逆向分析 这篇博客做一点逆向方面的研究,或者考虑使用PyExecJS载入前端JavaScript脚本来生成Cookie,因为逆向并不是我这篇博客的重点。在解决了这两个问题后,我们就可以提取出每一页的岗位和公司信息,而这些都可以通过BeautifulSoup解决,这里不再赘述,关于Boss直聘部分的源代码,请参考:https://github.com/qinyuanpei/job-analyse/blob/master/Spider/bossSpider.py。
智联招聘相对于Boss直聘要简单一点,通过抓包分析,我们可以找到这样一个地址:https://fe-api.zhaopin.com/c/i/sou?at={at}&_v={v}&x-zp-page-request-id={x-zp-page-request-id}&x-zp-client-id={v}&MmEwMD={MmEwMD}。通过这个接口可以直接获得JSON格式的数据,可想要构造这几个参数出来,实在是有一点困难,因为它遇到和Boss直聘一样的问题,基本都需要一定的逆向功底,而如果尝试去解析DOM,你会发现它的前端使用了Vue.js,换句话说,这个网站是由前端完成渲染的,这意味着,如果我直接访问https://sou.zhaopin.com/?jl=854这个地址,是无法拿到可以解析的DOM结构的,这就多少会有一点尴尬。所以,实际上博主最后没有实现智联招聘的爬虫,因为在这上面投入太多的精力,实在有一点得不偿失。这里简单说一下思路,基本上我们需要以POST方式调用这个接口,然后在Body中写入下面的结构:
{"pageSize":"30","cityId":854,"workExperience":"-1","companyType":"-1","employmentType":"-1","jobWelfareTag":"-1","kt":"3","at":"20673d42d62d48c38add329318fb9e2c","rt":"84a950e77e054854b4d2f9d90826d063","_v":"0.97312845","userCode":662040894,"eventScenario":"pcSearchedSouIndex","cvNumber":"JM620408945R90500002000"}
这里依然要解决Cookie的问题,它这个Cookie简直不能更恶心,因为参数实在是太多了:
那么,我放弃了,感兴趣的朋友可以顺着这个思路继续探索,加油!
相对于Boss直聘和智联招聘,前程无忧要更简单一点,这种简单是从心智体验上来讲。经过分析,它的地址为:https://search.51job.com/list/200200,000000,0000,00,9,99,+,2,{page}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=。它的简单体现在,可以直接通过修改page这个参数来达到抓取某一页数据的目的,它本身没有特别强大的反爬机制,所以,事实上,它是整个数据分析主要的数据来源,在这个地址里可能有一点大家看不懂的东西,没关系,博主一样看不懂,我们只需要知道它表示西安就可以了,如果想抓取某个城市的职位信息,可以直接在前程无忧上搜索,地址栏会告诉你这一切是如何变化的。需要说明的是,前程无忧的职位信息是存储在window.__SEARCH_RESULT__这个变量里的,所以,我们通过这个正则直接去匹配它即可,不需要再去解析DOM,这再次体现出了它的简单:
def searchJobs(self, cityName, query, page=1):
cityCode = cityName
if (cityCode != None):
searchUrl = 'https://search.51job.com/list/200200,000000,0000,00,9,99,+,2,{page}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare='.format(page=str(page))
html = self.makeRequest(searchUrl)
data = re.findall('window.__SEARCH_RESULT__ =(.+)}</script>', str(html))[0] + "}"
details = json.loads(data)['engine_search_result']
jobItems = []
companyItems = []
for detail in details:
jobItem = self.extractJob(detail)
if (jobItem == None):
continue
else:
jobItems.append(jobItem)
companyItem = self.extractCompany(detail)
if (companyItem == None):
continue
else:
companyItems.append(companyItem)
return (jobItems,companyItems)
因为这里真正起作用的实际上只有page这个参数,所以,我们只需要循环每一页就可以了,博主就是通过这个方法抓取了大量的职位信息。同样地,我们通过extractJob()和extractCompany()两个方法来组装职位和公司的信息,最终通过元组的形式返回,由调用者自己决定要如何去处理这些数据。虽然,我们选择了MongoDB这样的数据库,它不像关系型数据库那样重视Schema,可为了我们最终分析数据的时候方便一点,还是建议使用一致的数据结构。关于前程无忧部分的源代码,请参考:https://github.com/qinyuanpei/job-analyse/blob/master/Spider/job51Spider.py。
在开始今天的数据分析前,首先向大家展示下爬虫抓取到的数据。截止到写这篇的博客的时间,博主一共收集了20000个左右的职位/公司信息,如下图所示:
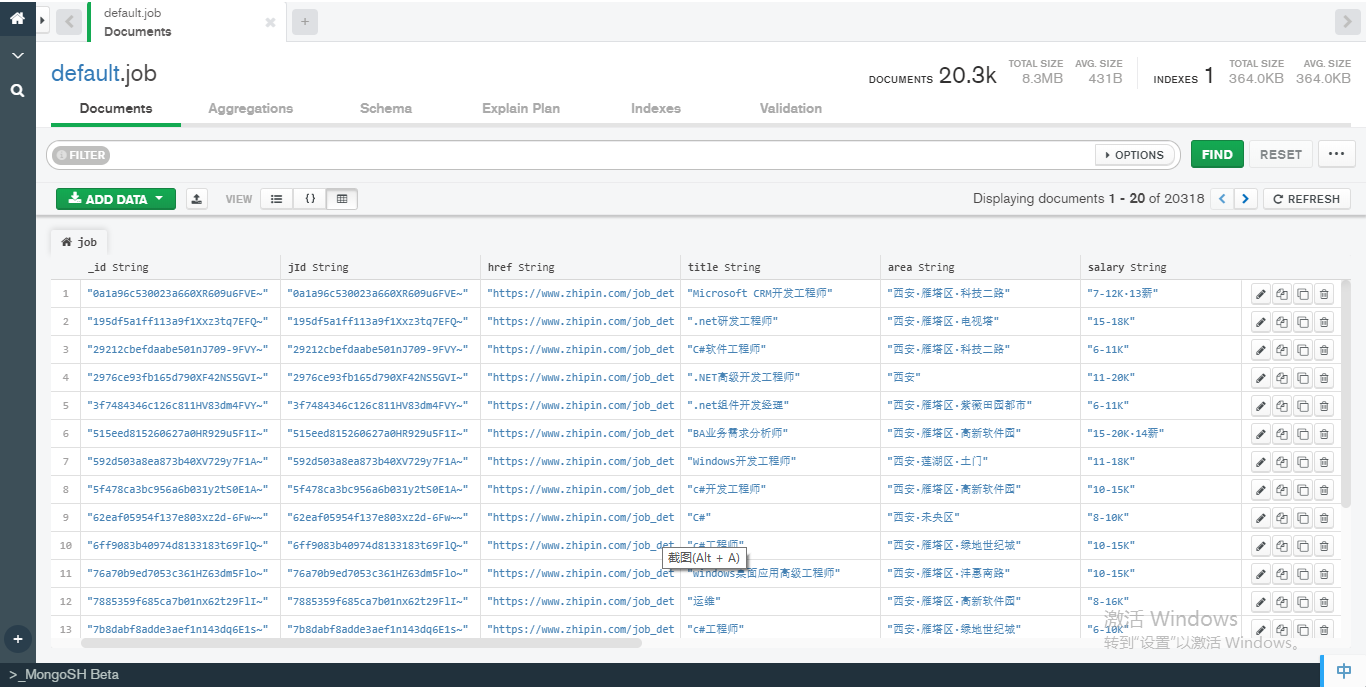
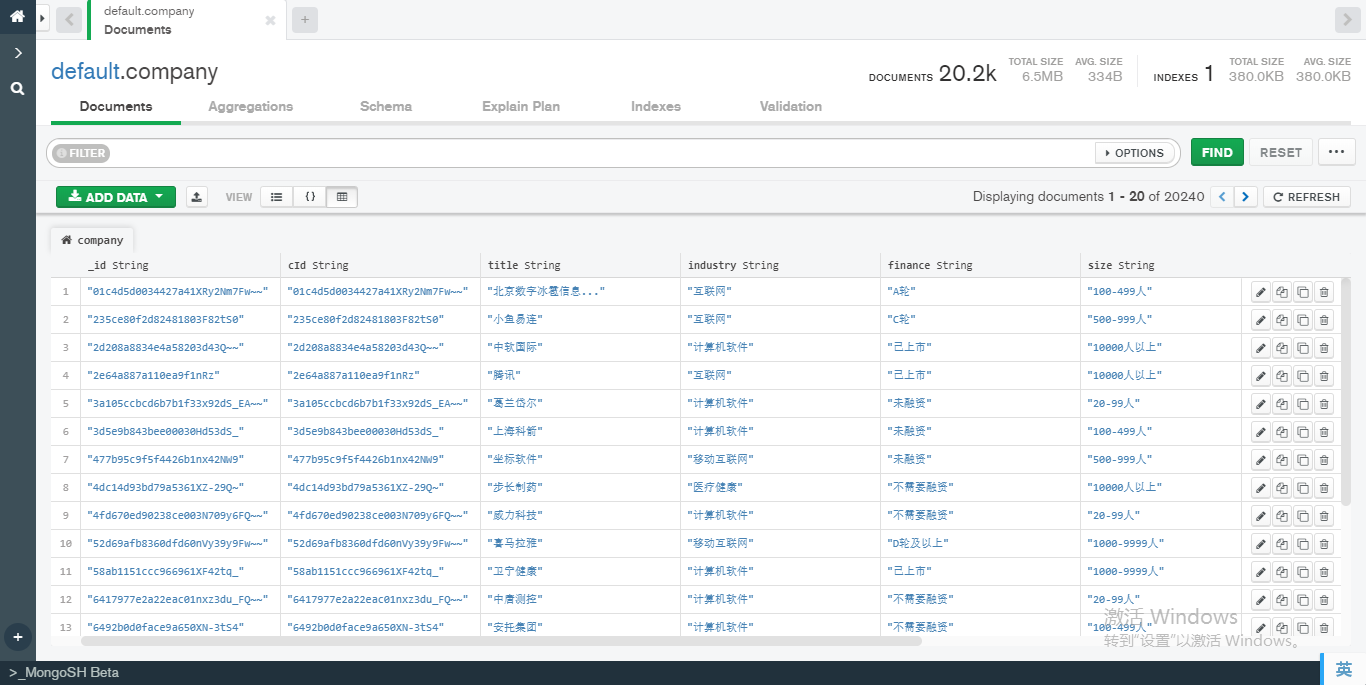
接下来,我们从数据库中读取这些数据以开始下面的分析:
store = Store.mongoStore.MongoStore('default')
jobs = list(store.find('job',{}))
companies = list(store.find('company',{}))
行业结构分析
俗话说,“男怕入错行,女怕嫁错郎”。我们今天的社会是一个非常“苛刻”的社会,它要求每一个人在“合适”的年龄做“该做”的事情,可要达到这样一个“标准”则是非常不容易的。在综艺节目《令人心动的Offer》里,“大龄”、“裸辞”、“背水一战”的丁辉,受到了来自红圈律所的“精英”们的区别对待,仿佛一个人的人生不能有一丁点的差错。或许人生的“试错”成本真的非常高,高到人们在30岁左右的时候纷纷遭遇中年危机。所以,我们实在有必要去了解一个行业,它目前的求职现状到底是什么样的,这里以西安市为例:
def analyse_industry():
industries = list(map(lambda x:x['industry'],companies))
counter = Counter(industries)
counter = sorted(counter.items(),key = lambda x:x[1],reverse = True)[0:15]
counter = dict(counter)
c = (
Pie()
.add("",[list(z) for z in zip(counter.keys(), counter.values())],label_opts=opts.LabelOpts(is_show=True, position="center"),)
.set_global_opts(
title_opts=opts.TitleOpts(title="西安市求职招聘行业结构分析(Top15)",pos_left=325),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="left", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render("./Reports/西安市求职招聘行业结构分析(Top15).html")
)
下面是整个西安市求职招聘排名前15位的行业结构:
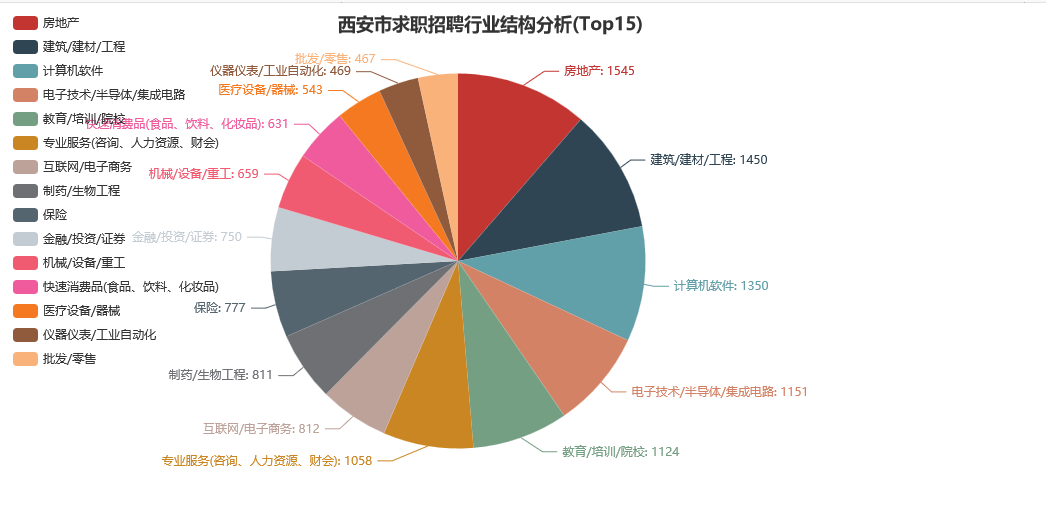
可以注意到,其中占据份额较大的行业主要有:房地产、建筑/建材/工程、计算机软件、电子技术/半导体/集成电路、教育/培训/院校等。
学历结构分析
作为一个“西漂”,博主对西安最深的一个印象就是,西安有着非常丰富的高校资源,正因为如此,博主一度认为西安遍历都是研究生。因为在过去的四年里,的确接触过不少研究生学历的同事,相比之下,博主这样一个普通211、非科班的本科生,着实显得有点相形见绌。我在之前的博客里有提到去中兴面试的经历,这个经历让我第一次意识到,学历和非科班的出身,终究有一天会成为你进入国企或者大厂的门槛,所以,博主在考虑要不要去读一个在职的研究生。这种认识到底是不是幸存者偏差呢,我们来看看数据分析的结果:
def analyse_education():
eduInfos = list(map(lambda x:x['eduInfo'], jobs))
counter = Counter(eduInfos)
counter = sorted(counter.items(),key = lambda x:x[1],reverse = True)
counter = dict(counter)
c = (
Pie()
.add("",[list(z) for z in zip(counter.keys(), counter.values())])
.set_global_opts(
title_opts=opts.TitleOpts(title="西安市求职招聘学历结构分析",pos_left=325),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="left", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render("./Reports/西安市求职招聘学历结构分析.html")
)
我承认我在胡说八道,因为结果非常的Amazing啊,非常的毕导啊:
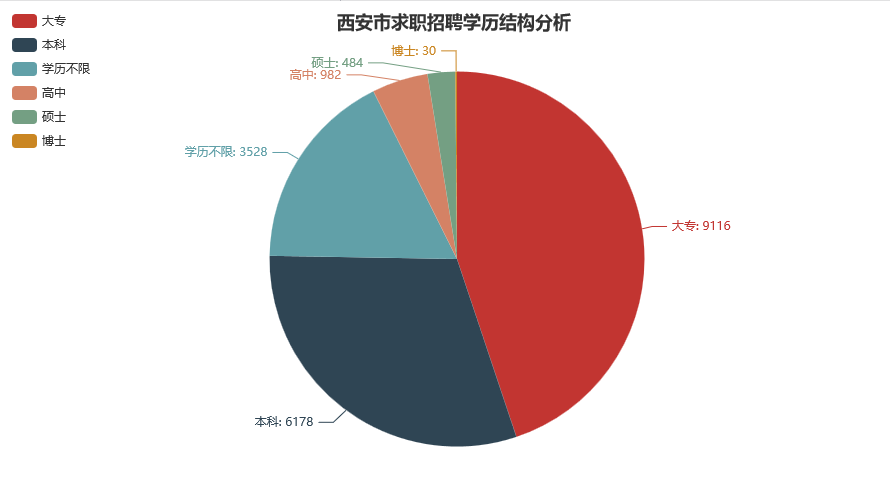
我没有想到研究生以上的比例这么低,可能是因为我身边这些同事的层次都比较高吧,哈哈!可当学历逐渐成为一种门槛,即使你比本科生多上三年学,最后一样要在这世界上颠沛流离的时候,是不是会和博主有一样的疑问,为什么IT行业会变成劳动密集型产业?是因为门槛低让这个行业劣币驱逐良币呢,还是拥有高学历的人才一样要去拧螺丝?
薪资待遇分析
有时候,我会忍不住想,是不是在任何一个城市里,人们工资增长永远都赶不上房价增长?如果真的是这样,我们为什么又要从三线小城市出来呢?可能是觉得大城市有更好的机会吧,可转眼到了2020年,上大学时一心想从事这个行业的我,当时无论如何都想不到若干年后要面对“35岁”这个问题。当“996”作为一种“福报”的声音越来越强烈,曾经我们认为的那“一点点”机会,真的就是只剩下“一点点”。人有时候就是在靠着那点“不切实际”过日子,譬如固执的认为收入会越来越高,可其实任何工作都是有天花板的存在的,以大多数普通人的努力程度,一辈子连天花板都可能触碰不到,真实的薪资水平到底是什么样的呢?年薪30万果真如此寻常等闲?我们一起来看:
def analyse_salary():
salaries = list(map(lambda x:x['avgSalary'], list(filter(lambda x:x['avgSalary'] != 0, jobs))))
counter = Counter(salaries)
counter = sorted(counter.items(),key = lambda x:x[1],reverse = True)
records = {'3000元以下':0, '3000元-5000元':0, '5000元-8000元':0, '8000元-12000元':0, '12000元-15000元':0, '15000元以上':0}
for (k,v) in counter:
if (k < 3000):
records['3000元以下'] += v
if (k >= 3000 and k < 5000):
records['3000元-5000元'] += v
if (k >= 5000 and k < 8000):
records['5000元-8000元'] += v
if (k >= 8000 and k < 12000):
records['8000元-12000元'] += v
if (k >= 12000 and k < 15000):
records['12000元-15000元'] += v
if (k >= 15000):
records['15000元以上'] += v
counter = dict(records)
c = (
Pie()
.add("",[list(z) for z in zip(counter.keys(), counter.values())])
.set_global_opts(
title_opts=opts.TitleOpts(title="西安市求职招聘平均工资分析",pos_left=325),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="left", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render("./Reports/西安市求职招聘平均工资分析.html")
)
由此,我们得到了整个西安市的收入分布情况。显然,*5000~8000这个收入区间才是大多数普通人的真实写照:
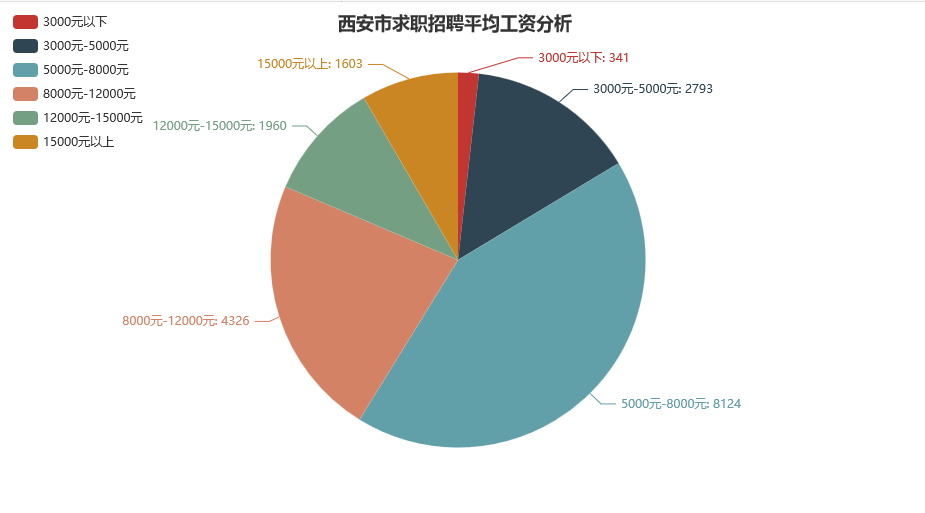
我们继续分析,哪些行业的平均工资更高一点,因为这样你会找到同龄人的参考对象:
def analyse_industry_salary():
filtered = list(filter(lambda x:x['avgSalary'] != 0, jobs))
salaries = {}
for job in filtered:
if (job['industry'] == ''):
continue
if salaries.get(job['industry']) == None:
salaries[job['industry']] = [job['avgSalary']]
else:
salaries[job['industry']].append(job['avgSalary'])
counter = {}
for (industry, data) in salaries.items():
counter[industry] = int(sum(data) / len(data))
counter = sorted(counter.items(),key = lambda x:x[1],reverse = True)[0:15]
counter = dict(counter)
c = (
Bar()
.add_xaxis(list(counter.keys()))
.add_yaxis("平均工资", list(counter.values()))
.set_global_opts(
title_opts=opts.TitleOpts(title="西安市求职招聘行业工资分析(Top15)", pos_left=325),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="left", orient="vertical"),
)
.render("./Reports/西安市求职招聘行业工资分析(Top15).html")
)
类似地,我们这里取排名前15位的行业进行分析:
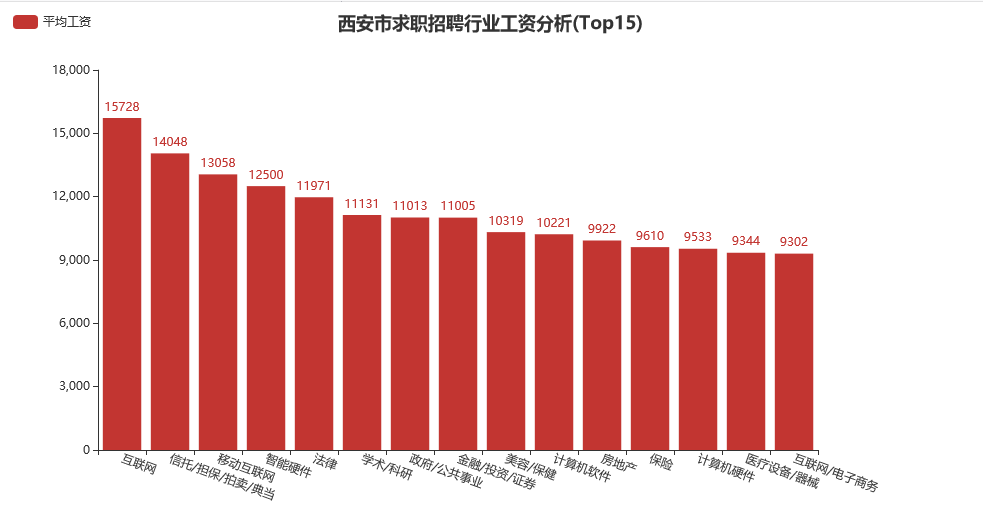
可以注意到,工资收入靠前的行业主要集中在:互联网/移动互联网/计算机软件/电子商务、信托/拍卖/典当/担保、 智能硬件、法律、学术/科研、保险、房地产、金融/投资/证券、美容/保健等行业。可惜,从一名IT行业从业者的角度来看,西安实际上并没有真正的互联网公司。这个世界常常如此,每个月挣15K的人感慨自己买不起房,可还有那么多收入在8K以下的人群,还能再说什么呢?
学历与薪资关系分析
通常大家都认为,学历越高,薪资就会越高,那么,这个是否符合实际情况呢,我们一起来看一下:
def analyse_eduInfo_salary(industry=None):
filtered = list(filter(lambda x:x['avgSalary'] != 0, jobs))
if (industry != None):
filtered = list(filter(lambda x:x['industry'] == industry, filtered))
salaries = {}
for job in filtered:
if (job['eduInfo'] == ''):
continue
eduInfo = job['eduInfo']
if (eduInfo in ['学历不限','不限']):
eduInfo = '学历不限'
if salaries.get(eduInfo) == None:
salaries[eduInfo] = [job['avgSalary']]
else:
salaries[eduInfo].append(job['avgSalary'])
counter = {}
for (eduInfo, data) in salaries.items():
counter[eduInfo] = int(sum(data) / len(data))
c = (
Bar()
.add_xaxis(list(counter.keys()))
.add_yaxis("平均工资", list(counter.values()))
.set_global_opts(
title_opts=opts.TitleOpts(title="西安市求职招聘学历与薪资关系分析", pos_left=325),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="left", orient="vertical"),
)
.render("./Reports/西安市求职招聘学历与薪资关系分析.html")
)
下面给出可视化以后的结果:
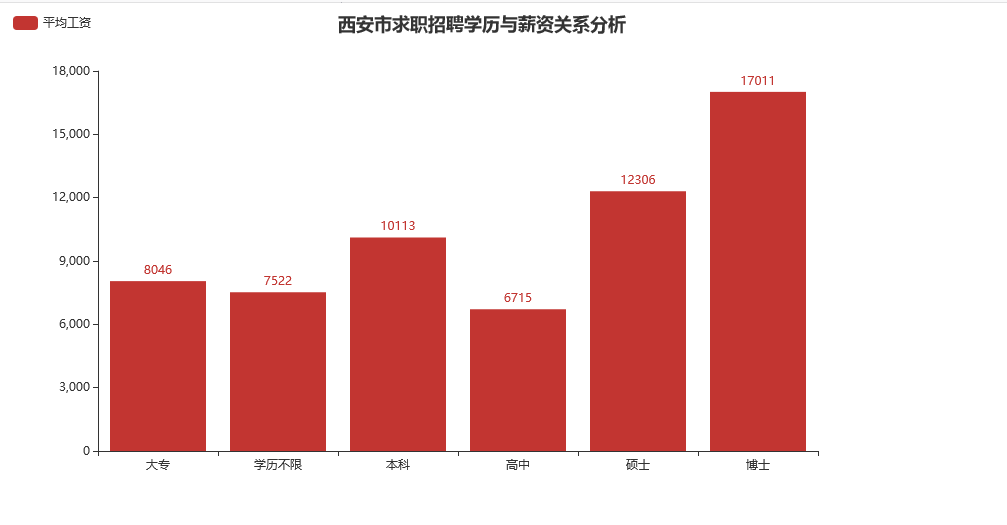
可以发现,整体上学历和薪资是呈正比的,甚至“不限学历”比“高中”的工资还要高一点。可如果有那么多“不限学历”的工作,为什么今年还有那么多人找不到工作呢?我想,这就是我们常说的选择,我们之所以付出努力,无非是想比别人多一点选择,可正如纳什均衡理论所言,如果我们大家都去选择相同的东西,最后的结果可能是大家都得不到这样东西。可话又说回来,明明都知道那个行业热门,如果不做这个选择,反而才是最奇怪的吧……
经验与薪资关系分析
如果说学历与薪资呈正比,那么经验与薪资则不一定满足这样的关系,因为经验其实是一个不准确的“度量”单位。以IT行业为例,在一家公司里,老员工的薪资被新员工的薪资“倒挂”是经常发生的事情。所以,人们似乎达成了某种共识,即期待公司主动涨薪是非常困难的,你唯一能做的就是在面试时争取更多的薪资。这就要说到经验这个话题,IT行业技术日新月异的特点,实在很难让经验变成一个“褒义词”,因为经验在积累的同时同样在“过期”,更不用说那些一直在“重复”的人了,所以,我觉得掌握通用型的知识譬如算法、数据结构等会更重要。
def analyse_exps_salary(industry=None):
filtered = list(filter(lambda x:x['avgSalary'] != 0, jobs))
if (industry != None):
filtered = list(filter(lambda x:x['industry'] == industry, filtered))
salaries = {}
for job in filtered:
if (job['exps'] == ''):
continue
exps = job['exps']
exps = exps.replace('经验','')
if (exps in ['1年','1年以内','2年','1-3年']):
exps = '1-3年'
if (exps in ['不限','经验不限']):
exps = '经验不限'
if (exps in ['3到4年','3到5年','3-4年','3-5年']):
exps = '3-5年'
if (exps in ['8到9年','5到10年','5到7年','8-9年','5-10年','5-7年']):
exps = '5-10年'
if salaries.get(exps) == None:
salaries[exps] = [job['avgSalary']]
else:
salaries[exps].append(job['avgSalary'])
counter = {}
for (industry, data) in salaries.items():
counter[industry] = int(sum(data) / len(data))
c = (
Bar()
.add_xaxis(list(counter.keys()))
.add_yaxis("平均工资", list(counter.values()))
.set_global_opts(
title_opts=opts.TitleOpts(title="西安市求职招聘工作经验与薪资关系分析", pos_left=325),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="left", orient="vertical"),
)
.render("./Reports/西安市求职招聘工作经验与薪资关系分析.html")
)
一切都会向着我们期待的方向发展吗?我们拭目以待:
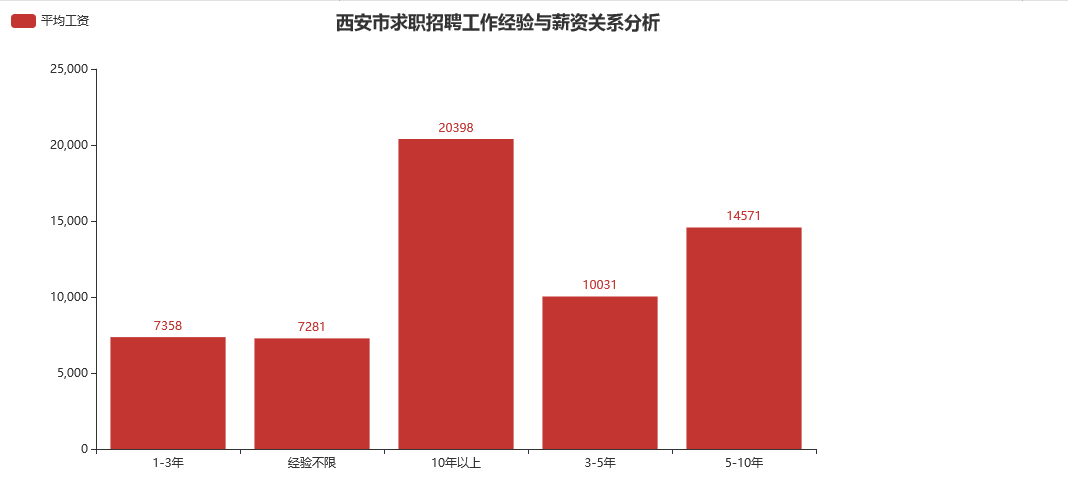
可以发现,整体上,经验越丰富,薪资待遇会越高。前提是你真的收获了经验,而不是在岁月的蹉跎里单单收获了皱纹和沧桑。这是我们每个人都应该去反思的一个问题,如果一切的经验都有过时的那一天,至少你真的拥有过它们,就像爱情这种东西一样。
招聘热词分析
在招聘网站上,一般都会以标签的方式,对职位要求、公司福利等进行描述,譬如五险一金、弹性打卡等等,通过这些标签,我们就能对职位以及公司有个基本印象。所以,我们可以通过分析这些标签,来展示在求职过程中求职者和招聘方各自关注哪些因素。下面,我们将以词云的形式来展示这些标签:
# 提取岗位关键字
job_tags = []
for item in map(lambda x:x['tags'], jobs):
if (item != None):
job_tags.extend(item)
# 提取公司关键字
company_tags = []
for item in map(lambda x:x['tags'], companies):
if (item != None):
company_tags.extend(item)
def analyse_extract_tags(words,title):
words = list(filter(lambda x:x!='', words))
data = Counter(words)
c= (
WordCloud()
.add(series_name="热门词汇", data_pair=data.items(), word_size_range=[6, 66])
.set_global_opts(
title_opts=opts.TitleOpts(
title=title, title_textstyle_opts=opts.TextStyleOpts(font_size=23)
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
.render('.\Reports\{title}.html'.format(title=title))
)
analyse_extract_tags(
words=job_tags,
title='西安市求职者热词分析'
)
analyse_extract_tags(
words=company_tags,
title='西安市招聘者热词分析'
)


可以注意到,五险一金、年终奖金、专业培训、绩效奖金、节日福利、带薪年假是大家普遍关注的点。
本文主要抓取了Boss直聘、智联招聘、前程无忧三个招聘网站的职位信息和公司信息,并在此基础上对西安市的求职招聘进行了数据分析,主要从行业结构、学历结构、薪资待遇、学历与薪资关系、经验与薪资关系、招聘热词等方面入手,经分析,针对西安市的求职招聘的求职招聘,我们可以得出下面的结论:(1)西安市排名相对靠前的行业主要有:房地产、建筑/建材/工程、计算机软件、电子技术/半导体/集成电路、教育/培训/院校等;(2)西安市招聘的职位中大专和本科学历约占总职位的75%左右,硕士以及博士学历相对较低;(3)西安市的平均薪资中,5000~8000这个收入区间是大多数普通人的真实写照,工资收入靠前的行业主要集中在:互联网/移动互联网/计算机软件/电子商务、信托/拍卖/典当/担保、 智能硬件、法律、学术/科研、保险、房地产、金融/投资/证券、美容/保健等行业;(4)拥有高学历的人更有可能拥有高薪资;(5)整体上,经验越丰富,薪资待遇会越高。前提是你真的收获了经验,而不是在岁月的蹉跎里单单收获了皱纹和沧桑;(6)在整个求职招聘中,无论是求职者还是招聘者,普遍看重的因素有:五险一金、年终奖金、专业培训、绩效奖金、节日福利、带薪年假等。虽然一开始的目的是想知道西安有多少“996”的公司,不过在后续的实现过程中,发现从Boss直聘上抓取不到这些信息,所以,最终呈现出的结果就变成了现在这个样子,考虑到篇幅,关于公司规模、公司类型的分析,没有在这里写出来,如果大家感兴趣,可以参考:https://github.com/qinyuanpei/job-analyse/tree/master。以上就是这篇博客的全部内容啦,谢谢大家!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK