

How To Make Your Python Code Run Faster — 2nd Installment
source link: https://towardsdatascience.com/did-you-know-how-to-make-your-python-code-run-faster-2nd-installment-f105516cbd8a
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

How To Make Your Python Code Run Faster — 2nd Installment
Efficient programming practices
In the last 2 tutorials, we talked about measuring the execution timeof the python code and optimum utilization of hardware for better code execution speed. In this tutorial, we will again aim to improve our code run time but, by using some programming best practices like:
- Memoization
- Vectorization
Memoization
a.) School days
I am sure everyone reading this post would remember their days of primary education. Our mathematics teacher always impressed upon memorizing multiplication tables from 2 to 20. Ever wondered why? Simple, these tables form the foundation for mathematical calculations, and storing them in your memory can help you calculate faster.
b.) Back to Future
The old concept of memorizing difficult concepts is built into modern world programming concepts by the name memoization.
Quoting Wikipedia, memoization is defined as the optimization technique used primarily to speed up computer programs by storing results of expensive function calls and returning the cached result when the same input occurs again.
c.) Implementing in Python
To demonstrate this concept in Python, let’s first define an expensive function. To emulate an expensive function, which is computationally time-consuming, we will call sleep function from the time package and artificially increase the run time of the function.
Python code to create the function is written below. This function uses a numerical argument as the input, sleeps for 5 seconds, and then returns the square of the numerical value as output.
USUAL APPROACH TO DEFINE A FUNCTION#### Import time package
import time#### Defining expensive function - The Usual Way
def expensive_function(n):
time.sleep(5)
return n**2
d.) Run time with the commonly practiced approach
With the approach used above, every time we make a function call, the function will first sleep for 5 seconds and then return the actual result. Let’s time profile this function by making 3 consecutive calls.
### Calling the expensive function 3 times and timing
%%timeit -n1 -r1
expensive_function(9)
expensive_function(9)
expensive_function(9)### Time profile output
15 s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
Given, we have called the function 3 times, the total execution time recorded is 15 seconds.
e.) Reducing the run time using memoization
MEMOIZATION APPROACH TO DEFINE FUNCTIONS
### Importing package
import time### Re-defining the expensive function
def expensive_function(n):
argument_dict = {}
if n in argument_dict:
return argument_dict[n]
else:
argument_dict[n] = n**2
time.sleep(5)
return n**2### Testing the run time
%%timeit -n1 -r1
expensive_function(9)
expensive_function(9)
expensive_function(9)### Time Profile output
5.01 s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
Explanation
- As memoization advocates the storage of results from expensive functions, we have used Python’s dictionary to do that job for us. Notice the definition of the dictionary “argument_dict”
- The function definition has slightly changed. Now, before sleeping for 5 seconds and returning the results, the function checks if the result associated with the passed argument already exists in the dictionary
- A call to sleep function is only made if the results associated with the passed argument are not available in the memory (dictionary in this case)
- Looking at the test results one can notice that the execution time (5.01 secs) for the test code has gone down by one-third of what was encountered in the past execution (15 secs)
Vectorization
Every time we think of implementing iterative operation in our code, the first programming construct which comes to our mind is the loop. Loops do a reasonable job when working with smaller data sets but the performance degrades as the size of the data set increases. A small change in the programming mindset can help us overcome this challenge.
Consider a scenario where we are required to perform some operation on one column of a Pandas Data frame containing 1 million rows. If approached traditionally, one will loop through 1 million records one after the other.
Vectorization, on the other hand, would suggest performing this operation just once on the complete column (not record by record). This way, you are escaping performing the same operation 1 million times. Following examples demonstrate how can we eliminate loops from some common programming scenarios:
a) Simple mathematical operations
Let’s consider a simple scenario where we have a Pandas data frame containing base and perpendicular lengths of 100k right-angled triangles and the task is to calculate their hypotenuse. The formula for this calculation is as follows:
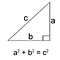
Let’s capture the run time when performing this operation using the pandas apply method (iterative application of a function on a series object):
#### Importing libraries
import pandas as pd
import random#### Creating Pandas with random values of base and perpendicular
base = [random.randint(1,100) for _ in range(100000)]
perpend = [random.randint(1,100) for _ in range(100000)]
triangle = pd.DataFrame(list(zip(base, perpend)),columns=["Base", "Perpendicular"])#### Calculating hypotenuse
%%timeit
triangle["Hypotenuse"] = triangle.apply(lambda row: (row["Base"]**2 + row["Perpendicular"]**2) **(1/2), axis=1)#### Performance
3.43 s ± 52.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Using apply (one of the most efficient forms of pandas looping) to loop through 100k rows has taken us approx 3.43 seconds. Let’s see how vectorization can help us in improving the performance of this code.
#### Importing libraries
import pandas as pd
import random#### Creating Pandas with random values of base and perpendicular
base = [random.randint(1,100) for _ in range(100000)]
perpend = [random.randint(1,100) for _ in range(100000)]
triangle = pd.DataFrame(list(zip(base, perpend)),columns=["Base", "Perpendicular"])#### Calculating hypotenuse
%%timeit
triangle["Hypotenuse"] = (triangle["Base"]**2 + triangle["Perpendicular"]**2) **(1/2)#### Performance
5.81 ms ± 274 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Explanation
- Loop, used in the previous example, is eliminated in this version of the code
- A single code statement operating on complete pandas series object (Base and Perpendicular) is incorporated (highlighted in bold)
- The complete operation is done in 5.81 ms as compared to 3.42 seconds earlier. Isn’t this improvement substantial?
b) Operations involving conditionals
Another common scenario where vectorization can come in handy is, when the loops are to be executed conditionally. To demonstrate this, we have created some dummy data that has information on hourly electricity consumption in our house for the year 2019 (365*24 records). We want to calculate the cost of electricity for each hour given the charges are different for different hours in the day. The charges table is as follows:

Evaluating the performance when writing simple loop:
#### Importing libraries
import pandas as pd#### Importing Dataframe
df = pd.read_csv("/home/isud/DidYouKnow/Tutorial 4/electricity.csv")#### Calculating Hourly Electricity Cost
%%timeit
df["cost"] = df[["Hour","Usage"]].apply(lambda x: x["Usage"]*5 if x["Hour"]<7 else (x["Usage"]*10 if x["Hour"] <19 else x["Usage"]*15),axis = 1)#### Performance
417 ms ± 19.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Using pandas’ most efficient looping approach (apply method) we could achieve our objective in 417 milliseconds. Let’s evaluate the performance when performing the same operation using vectorization:
#### Importing libraries
import pandas as pd#### Importing Dataframe
df = pd.read_csv("/home/isud/DidYouKnow/Tutorial 4/electricity.csv")#### Calculating Hourly Electricity Cost
%%timeit
less_seven = df["Hour"].isin(range(1,7))
less_nineteen = df["Hour"].isin(range(7,19))
rest = df["Hour"].isin(range(19,24))
df.loc[less_seven, "Cost"] = df.loc[less_seven, "Usage"] * 5
df.loc[less_nineteen, "Cost"] = df.loc[less_nineteen, "Usage"] * 10
df.loc[rest, "Cost"] = df.loc[rest, "Usage"] * 15#### Performance
7.68 ms ± 47 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Explanation
- Rather than looping through each row, we have created logical vectors for different hours of the day namely less_seven, less_nineteen and rest
- These logical vectors are then used for one shot (vectorized) calculation of the cost components.
- With the above approach, we could reduce the code run time from 417 milliseconds to 7.68 milliseconds.
Closing note
In the last 2 tutorials, we have tried equipping you with the approaches to write efficient codes. Try these approaches and let us know if they were helpful.
Will try and bring more interesting topics in future tutorials. Till then:
HAPPY LEARNING!!!!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK