

python requests库如何使用代理避免爬虫IP限制,proxy无效的解决方法,解决requests.e...
source link: https://blog.popkx.com/python-requests-library-how-to-use-proxy-proxy-invalid-solution-to-solve-requests-exception/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

python requests库如何使用代理避免爬虫IP限制,proxy无效的解决方法,解决requests.exceptions.MissingSchema: Proxy URLs must have explicit schemes错误
python 制作爬虫获取网络资源是方便的,但是很多网站设置了反爬虫机制,最常见的就是限制 IP 频繁请求了,只要某个 IP 在单位时间内的请求次数超过一定值,网站就不再正常响应了,这时,我们的 python 爬虫就无法正常工作了。对于这种限制 IP 的反爬虫机制,解决方法很简单,只要让python爬虫换 IP 访问资源就可以了,即使用代理(proxy)。

如何使用代理(proxy)
鉴于制作 python 爬虫时,requests 库使用的较多,这里就介绍下 requests 库如何使用代理。其实真的很简单,下面是一个非常简单的使用代理的 demo:
#encoding=utf8
import requests
url = 'https://blog.popkx.com'
proxy = {
'https': 'https://95.154.110.194:51232'
}
header = {
'User-agent': 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)',
}
if __name__ == "__main__":
res = requests.get(url, headers=header, proxies=proxy)
print res.status_code
这里用我的博客地址: https://blog.popkx.com 做测试,执行脚本,发现成功了。
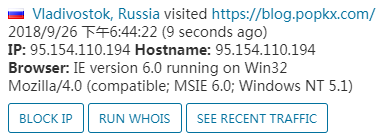
在后台查询,发现访问 IP 即为我们设置的代理 IP。
可能会遇到的几点问题
python 的 requests 库使用代理是简单的,但是依然可能会遇到问题,例如:
使用代理,结果报错:requests.exceptions.MissingSchema: Proxy URLs must have explicit schemes
报错信息的意思是,代理 url 需要指定明确的方案。这很可能是填写代理信息的格式出错了,例如,下面的填写方式就会造成 requests.exceptions.MissingSchema: Proxy URLs must have explicit schemes 错误。
proxy = {
'https': '95.154.110.194:51232'
}
解决方法很简单,填写完整就可以了。
proxy = {
'https': 'https://95.154.110.194:51232'
}
明明设置了代理,代理却不起作用
这个问题,可能是因为设置的代理协议和要访问的网站协议不一致造成的。比如我的博客协议是https,如果代理协议是http,则代理将不会起作用。修改一下 demo,试验之:
#encoding=utf8
import requests
url = 'https://blog.popkx.com'
proxy = {
'http': 'https://95.154.110.194:51232' # 协议修改为 http
}
header = {
'User-agent': 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)',
}
if __name__ == "__main__":
res = requests.get(url, headers=header, proxies=proxy)
print res.status_code
执行脚本,在后台发现访问 IP 是我本机的 IP,而不是代理 IP。
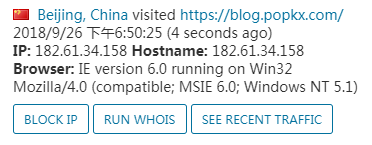
阅读更多: Python
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK