

Linux学习第26节,内核中的“中断”下半部工作队列机制
source link: https://blog.popkx.com/linux-learning-section-26-workqueue-mechanism-for-the-lower-half-of-interrupt-in-the-kernel/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

第24节提到,在处理中断时,Linux 内核为了解决“又想做得快,又想做得多”的矛盾,将一次完整的中断处理分为“上半部”和“下半部”两部分,耗时较多但是对实时性要求不高的处理统统放入下半部。

2.6.26 版本的 Linux 内核有软中断、tasklet和工作队列三种形式的“下半部”。前面两节主要讨论了软中断和tasklet,我们已经知道软中断处于中断上下文中,因此软中断处理程序不能阻塞,不能睡眠,这就限制了软中断处理程序的发挥。tasklet 也是如此,因为它是基于软中断机制实现的。
Linux 内核中的工作队列
那如果想把下半部的工作推后到进程上下文中完成,或者推后执行的任务需要睡眠时,就需要借助工作队列机制了。Linux 内核会把工作队列中的工作交给内核线程去执行,而内核线程正是运行在进程上下文中的,所以工作队列允许重新调度,也允许其睡眠。
工作队列子系统其实算是一组接口,通过它创建的进程(即所谓的工作者线程)负责执行Linux内核或者其他模块排到工作队列中的任务。Linux 内核提供默认的工作者线程(event/n,n是处理器编号)处理队列中的任务,这样看来,工作队列就变成了一组把延后执行的任务(排入队列中的任务)交给特定线程(默认的工作者线程)处理的接口。
Linux 内核中工作队列使用的数据结构是 workqueue_struct 结构体,它的C语言代码如下,请看:
struct workqueue_struct {
struct cpu_workqueue_struct *cpu_wq;
struct list_head list;
const char *name;
int singlethread;
int freezeable; /* Freeze threads during suspend */
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
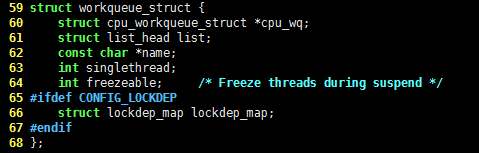
容易看出,workqueue_struct 结构体是一个链表的节点,成员 cpu_wq 是多维的,因为每个处理器都对应一个工作者线程,结构体 cpu_workqueue_struct 的C语言代码如下,请看:
struct cpu_workqueue_struct {
spinlock_t lock;
struct list_head worklist;
wait_queue_head_t more_work;
struct work_struct *current_work;
struct workqueue_struct *wq;
struct task_struct *thread;
int run_depth; /* Detect run_workqueue() recursion depth */
} ____cacheline_aligned;
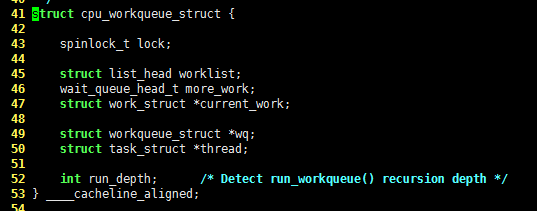
显然,结构体 cpu_workqueue_struct 也会串成一个链表。每个工作者线程关联一个自己的工作队列 wq,thread 成员则负责关联线程。
处理工作队列中的任务
结构体 cpu_workqueue_struct 的成员 current_work 表示工作者线程要处理的工作,它的数据结构由结构体 work_struct 定义,C语言代码如下,请看:
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func;
};
成员 func 指向处理函数,data 则是它的参数。这些结构被连接成链表,每个处理器上的每种类型的队列都对应这样一个链表,例如前面提到的“默认的工作者线程”就有这样的链表。

当工作者线程被唤醒时,它就会执行链表中所有的工作,执行完毕后,相应的 work_struct 会被从链表上移除。当链表为空时,工作者线程再次进入睡眠。这一过程由 worker_thread() 函数完成,它的C语言代码如下,请看:
299 static int worker_thread(void *__cwq)
- 300 {
...
|- 309 for (;;) {
|| 310 prepare_to_wait(&cwq->more_work, &wait, TASK_INTERRUPTIBLE);
|| 311 if (!freezing(current) &&
|| 312 !kthread_should_stop() &&
|| 313 list_empty(&cwq->worklist))
|| 314 schedule();
|| 315 finish_wait(&cwq->more_work, &wait);
|| 316
|| 317 try_to_freeze();
|| 318
|| 319 if (kthread_should_stop())
|| 320 break;
|| 321
|| 322 run_workqueue(cwq);
|| 323 }
| 324
| 325 return 0;
| 326 }
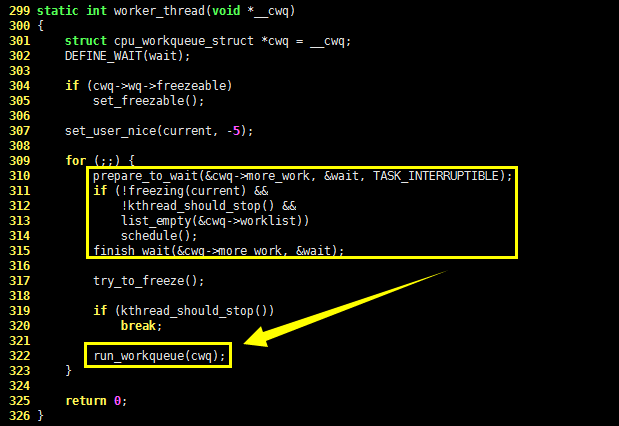
请看黄框中的核心代码,在for(;;)死循环中,work_thread() 函数将自己设置为 TASK_INTERRUPTIBLE 状态,并加入到等待队列中。如果工作链表为空,则进行一次进程调度,否则结束等待,调用 run_workqueue() 函数执行链表中的工作。run_workqueue() 函数的C语言代码如下,请看:
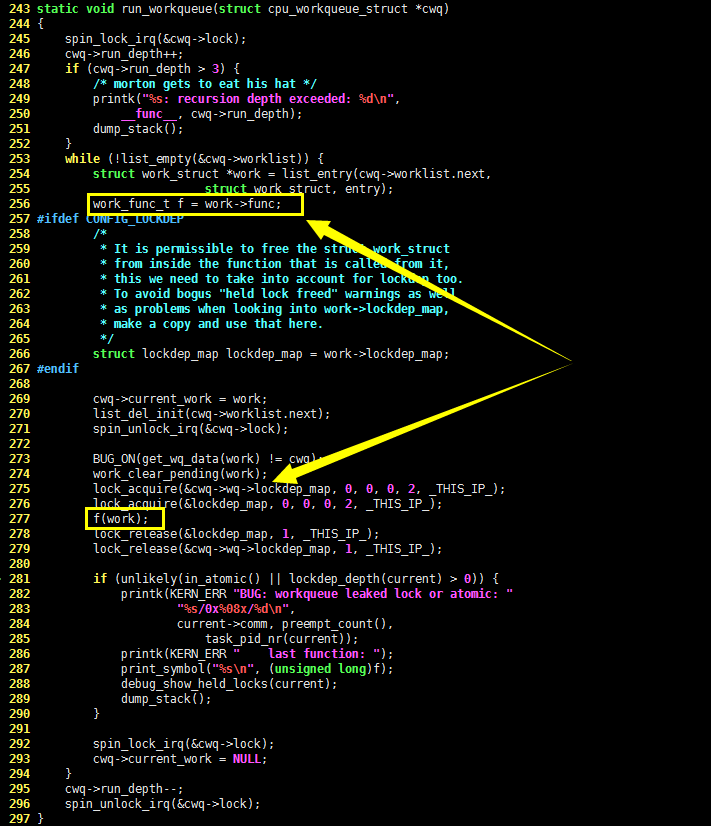
run_workqueue() 函数的C语言代码虽然长,但是逻辑并不复杂,无非就是从链表取下节点对象,逐个执行,这里就不赘述了。好了,现在已经明白Linux 内核是如何设计和实现工作队列的了,再来看看如何使用它。
使用工作队列
Linux 内核定义了 DECLARE_WORK 宏用于静态创建 work_struct 结构体,它的C语言代码如下,请看:
#define DECLARE_WORK(n, f) \
struct work_struct n = __WORK_INITIALIZER(n, f)
#define __WORK_INITIALIZER(n, f) { \
.data = WORK_DATA_INIT(), \
.entry = { &(n).entry, &(n).entry }, \
.func = (f), \
__WORK_INIT_LOCKDEP_MAP(#n, &(n)) \
}
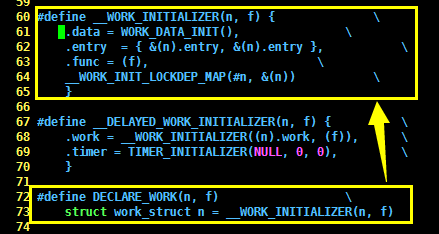
其实就是创建一个 work_struct 结构体并赋值。当然,也可以在C语言程序运行时,使用 INIT_WORK 宏通过指针创建一个工作,INIT_WORK 宏的C语言代码如下,请看:
#define INIT_WORK(_work, _func) \
do { \
(_work)->data = (atomic_long_t) WORK_DATA_INIT(); \
INIT_LIST_HEAD(&(_work)->entry); \
PREPARE_WORK((_work), (_func)); \
} while (0)
再来看看工作队列的处理函数,它的原型如下:
void work_handler(void *data);
这个函数由工作者线程执行,因此运行在进程上下文中,允许响应中断,且可以睡眠可以被调度。工作就创建好之后,可以通过 schedule_work() 函数将其交给默认工作线程处理,它的C语言代码如下,请看:
int schedule_work(struct work_struct *work)
{
return queue_work(keventd_wq, work);
}
容易看出, schedule_work() 函数其实就是把 work 加入到全局工作队列 keventd_wq 中,这一动作由 queue_work() 函数完成,它的C语言代码如下:
int queue_work(struct workqueue_struct *wq, struct work_struct *work)
{
int ret = 0;
if (!test_and_set_bit(WORK_STRUCT_PENDING, work_data_bits(work))) {
BUG_ON(!list_empty(&work->entry));
__queue_work(wq_per_cpu(wq, get_cpu()), work);
put_cpu();
ret = 1;
}
return ret;
}
容易看出,queue_work() 函数的核心功能由__queue_work() 函数完成,它的C语言代码如下:

到这里就明白了,其实 schedule_work() 函数的核心就是将工作 work 加入到工作队列中,排队等待被执行。
当然,Linux 内核也允许创建新的工作者线程,但是并不推荐,所以相关分析留给读者自己了。
到这里,Linux 内核中关于中断“下半部”的三种类型就粗略的分析完了。“软中断”适合处理对实时性要求高,需要频繁执行的工作,但是需确保共享数据的同步安全性。tasklet 能确保同一类型的工作不会在多个处理器上同时运行,但是它是基于“软中断”实现的,因此和“软中断”一样处于中断上下文中,不能睡眠不能阻塞。如果推后执行的工作需要在进程上下文中运行,则应选择工作队列。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK