

C语言陷阱与技巧第17节,如果有个条件很大可能不发生,怎样写出更高效率的程序
source link: https://blog.popkx.com/c-language-traps-and-skills-section-17-how-to-write-more-efficient-programs-if-one-conditions-are-very-impossible/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

C语言陷阱与技巧第17节,如果有个条件很大可能不发生,怎样写出更高效率的程序
在学习C语言程序开发时,很多初学者常常会有一种“编程也不过如此”的错觉,这种感觉通常出现在刚刚学完C语言语法,且能够独立完成一些课后练习题的时候,初学者的信心会在这一时期达到顶峰。可能会觉得程序无非就是各种 if 条件判断,加上相应的逻辑处理。
程序员编写程序就是为了服务人的,程序能够提供的服务越多,这个程序的功能也就越强大。不过,程序是死板的,它需要接收外界(比如人)输入的指令,才知道要做什么。
例如,你打开今日头条,你得点击我的文章才能看到这些内容。头条不会在你没有输入时,自动的把我的文章显示到手机。
这么看来,“程序是各种条件判断,加上相应的逻辑处理”这句话并没有错。程序会根据条件的不同,做出不同的响应。事实上,在C语言程序开发中也是如此——例如,程序员常常需要根据被调用函数不同的返回值,做出不同的处理,这其实就是“条件判断”+“相应逻辑处理”。
不过,从上一节介绍的 3 种风格的C语言代码应该可以看出,同样一个功能,有经验的程序员总是能够写出紧凑易读的代码,以更小的开销,实现更高的执行效率。
以下这种C语言代码常常出现在C语言程序开发中,请看:
if(cond){
...
statements;
...
}else{
...
statements;
...
}
可是有时候 cond 只在极少的情况下发生,例如:随机生成一个随机数,该随机数的范围是 0~100000,如果随机数小于 2,则将 val 赋值为 -1,否则将 val 赋值为当前UTC时间,相关C语言代码如下,请看:
if(myrand() < 2)
val = -1;
else
val = time(NULL);
从上述代码可以看出, val = -1; 其实只有 2/100000 的几率会被执行,但是为了这 2/100000 的几率,程序每次都需要判断 if 条件是否成立,这会造成一定的性能损失。
可是,不写 if 判断代码又会导致最终得到的C语言程序有可能不按照预期执行,该怎么办呢?类似的情况还有,某个条件非常可能成立,只会在极少情况下才不成立,但是同样得写上 if 语句每次判断。
针对这种情况,其实可以参考 Linux 内核的C语言代码,请看下面这两个宏:
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
其实看宏的名字应该就能明白它们的作用:likely(x) 会告诉编译器 x 很可能成立,unlikely(x) 则会告诉编译器 x 不太可能成立,然后编译器会据此优化代码,生成效率更高的程序,稍后我们会看到一个实例。
这一过程是由编译器内置函数__builtin_expect实现的,应该能够发现,Linux 内核使用该函数时用到了一个小技巧——使用 "!!" 将条件转换为 bool 值( 0 或 1)。
相信读者应该已经明白,在C语言中任何非零值都会被认为是“真”,所以下面这样的C语言代码:
if(32)
printf("true");
else
printf("false");
编译后会输出 “true"。但是有时候有些程序员在开发中会忽略这一点,掉进“陷阱”,例如:
有两个函数 fun1() 和 fun2() 会返回任意整数,要求只有当它们一个返回真,一个返回假的时候,才打印“success”。
有些程序员会直接写:
int a = fun1();
int b = fun2();
if( ( a && (!b) || ( (!a)&&b ) )
printf("success")
还有些程序员注意到了 fun1() 和 fun()2 要么返回真,要么返回假,他觉得上面这种写法太罗嗦,于是写可能会写出这样的C语言代码:
if( fun1() != fun2() )
printf("success");
看起来,似乎只有一个真一个假的时候,fun1() 和 fun2() 才会不相等,所以上面这种简洁的写法更好?
不过要是 fun1() 和 fun2() 函数一个返回 3,一个返回 4 ,上面这种写法就会输出不符合预期的结果了。所以这种思路正确的写法如下,请看相关C语言代码:
if( !!fun1() != !!fun2() )
printf("success");
"!!" 可以将条件转换为 bool 值,下面这两种写法是等价的:
b = cond?1:0;
// 等价于
b = !!cond;
likely 与 unlikely 宏的实例
现在我们一起看一下 likely 与 unlikely 宏的作用,写出C语言代码如下,请看:
#define likely(x) (__builtin_expect(!!(x), 1))
#define unlikely(x) (__builtin_expect(!!(x), 0))
int test_likely(int x)
{
if(likely(x==0))
x = 6;
else
x = 9;
return x;
}
int test_unlikely(int x)
{
if(unlikely(x==0))
x = 6;
else
x = 9;
return x;
}
int test_normal(int x)
{
if(x==0)
x = 6;
else
x = 9;
return x;
}
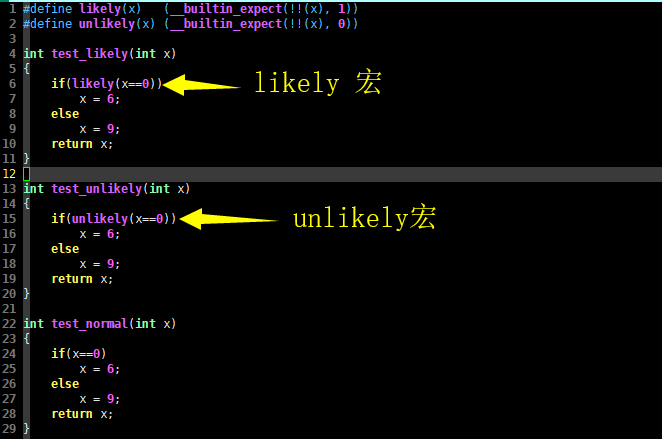
以上 test_xx() 函数在判断 x 是否等于 0 时,分别使用了 likely 宏,unlikely 宏,以及没有使用宏直接判断。我们输入以下命令:
# gcc -fprofile-arcs -O2 -c t.c
# objdump -d t.o
得到如下输出:
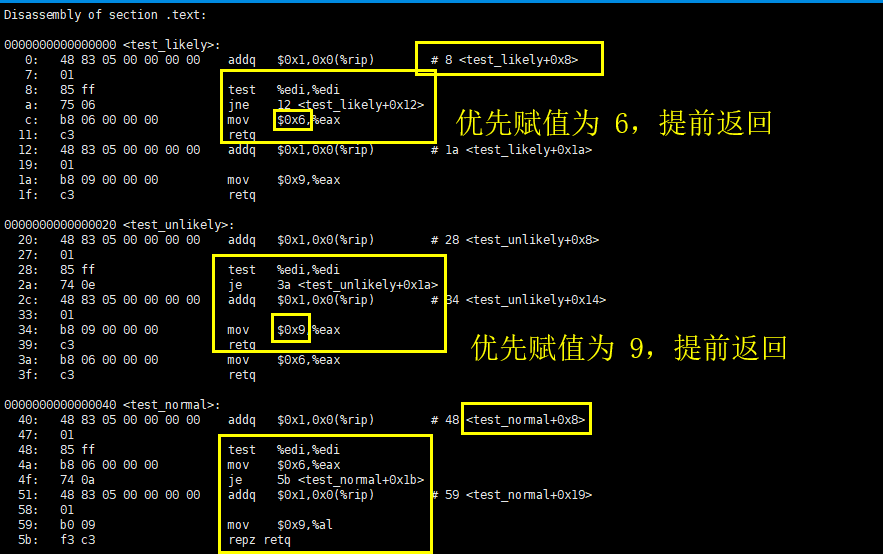
容易看出,likely 宏优先将 x 赋值为 6并提前返回,这意味着“x==6 极有可能发生”。unlikely 认为“x==6不太可能发生”,因此优先将 x 赋值为 9 并提前返回。而 test_normal() 函数则没有这些优化。
其实从这里也能够看出,如果程序员将 likely 宏与 unlikely 宏使用反了,是会降低C语言程序的效率的,因此在使用这两个宏之前,一定要弄清楚条件是很大可能发生,还是基本不会发生,否则会适得其反。
本节讨论了C语言程序开发中条件语句的重要性,介绍了使用 "!!" 将条件转换为 bool 值的小技巧,并在此基础上讨论了 Linux 内核中常用的 likely 和 unlikely 两个宏,正确使用这两个宏是能够提高最终得到的C语言程序运行效率的。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK