
12

Apache ActiveMQ实战(1)-基本安装配置与消息类型
source link: https://blog.csdn.net/lifetragedy/article/details/51836557
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Apache ActiveMQ实战(1)-基本安装配置与消息类型
ActiveMQ简介

ActiveMQ是一种开源的,实现了JMS1.1规范的,面向消息(MOM)的中间件,为应用程序提供高效的、可扩展的、稳定的和安全的企业级消息通信。ActiveMQ使用Apache提供的授权,任何人都可以对其实现代码进行修改。
ActiveMQ的设计目标是提供标准的,面向消息的,能够跨越多语言和多系统的应用集成消息通信中间件。ActiveMQ实现了JMS标准并提供了很多附加的特性。这些附加的特性包括,JMX管理(java Management Extensions,即java管理扩展),主从管理(master/salve,这是集群模式的一种,主要体现在可靠性方面,当主中介(代理)出现故障,那么从代理会替代主代理的位置,不至于使消息系统瘫痪)、消息组通信(同一组的消息,仅会提交给一个客户进行处理)、有序消息管理(确保消息能够按照发送的次序被接受者接收)。
ActiveMQ 支持JMS规范,ActiveMQ完全实现了JMS1.1规范。
JMS规范提供了同步消息和异步消息投递方式、有且仅有一次投递语义(指消息的接收者对一条消息必须接收到一次,并且仅有一次)、订阅消息持久接收等。如果仅使用JMS规范,表明无论您使用的是哪家厂商的消息代理,都不会影响到您的程序。
ActiveMQ整体架构
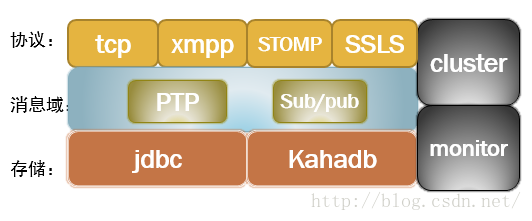
ActiveMQ主要涉及到5个方面:
消息之间的传递,无疑需要协议进行沟通,启动一个ActiveMQ打开了一个监听端口, ActiveMQ提供了广泛的连接模式,其中主要包括SSL、STOMP、XMPP;ActiveMQ默认的使用 的协议是openWire,端口号:61616;ActiveMQ主要包含Point-to-Point (点对点),Publish/Subscribe Model (发布/订阅者),其中在 Publich/Subscribe 模式下又有Nondurable subscription和 durable subscription (持久 化订阅)2种消息处理方式
在消息传递过程中,部分重要的消息可能需要存储到数据库或文件系统中,当中介崩溃时,信息不 回丢失
- Cluster (集群)
- Monitor (监控)
ActiveMQ的安装配置
- 通过http://activemq.apache.org/download.html 下载:apache-activemq-5.13.3-bin.tar.gz
- 把下载的该文件通过tar –zxvf apache-activemq-5.13.3-bin.tar.gz解压在当前目录
- 通过修改$ACTIVEMQ_HOME/conf/activemq.xml文件可以修改其配置
我们在此段増加配置如下:
此处,我们使用的是”>”通配符,上述配置为每个队列、每个Topic配置了一个最大2mb的队列,并且使用了”optimizedDispatch=true”这个策略,该策略会启用优化了的消息分发器,直接减少消息来回时的上下文以加快消息分发速度。
找到下面这一段
为确保扩展配置既可以处理大量连接也可以处理海量消息队列,我们可以使用JDBC或更新更快的KahaDB消息存储。默认情况下ActiveMQ使用KahaDB消息存储。ActiveMQ支持三种持久化策略:AMQ、KAHADB、JDBC
- AMQ 它是一种文件存储形式,具有写入快、容易恢复的特点,采用这种方式持久化消息会被存储在一个个文件中,每个文件默认大小为32MB,如果一条消息超过32MB,那么这个值就需要设大。当一个文件中所有的消息被“消费”掉了,那么这文件会被置成“删除”标志,并且在下一个清除开始时被删除掉。
- KAHADB,相比AMQ来説,KAHADB速度没有AMQ快,可是KAHADB具有极强的垂直和横向扩展能力,恢复时间比AMQ还要短,因此从5.4版后ActiveMQ默认使用KAHADB作为其持久化存储。而且在作MQ的集群时使用KAHADB可以做到Cluster+Master Slave的这样的完美高可用集群方案。
- JDBC,即ActiveMQ默认可以支持把数据持久化到DB中,如:MYSQL、ORACLE等。
找到下面这一段
此处为ActiveMQ的内存配置,从5.10版后ActiveMQ在<memoryUsage>中引入了一个percentOfJvmHeap的配置,该百分比为:
$ACTIVEMQ_HOME/bin/env中配置的JVM堆大小的百分比,如$ACTIVEMQ_HOME/bin/env 中:
$ACTIVEMQ_HOME/bin/env中配置的JVM堆大小的百分比,如$ACTIVEMQ_HOME/bin/env 中:
那么此处的percentOfJvmHeap=90即表示:MQ消息队列一共会用到2048M*0.9的内存。
全部配完后我们可以通过以下命令启动ActiveMQ
这种方式为前台启动activemq,用于开发模式便于调试时的信息输出。
你也可以使用:
你也可以使用:
以后台进程的方式启动activemq。
启动后在浏览器内输入http://192.168.0.101:8161/admin/ 输入管理员帐号(默认为admin/admin)即可登录activemq的console界面
启动后在浏览器内输入http://192.168.0.101:8161/admin/ 输入管理员帐号(默认为admin/admin)即可登录activemq的console界面
- 启动后的ActiveMQ的数据位于:$ACTIVEMQ_HOME/data/目录内
- 启动后的ActiveMQ运行日志位于:$ACTIVEMQ_HOME/data/目录内的activemq.log文件
- 如果需要改ActiveMQ的日志配置可以通过修改$ACTIVEMQ_HOME/conf/log4j.properties
ActiveMQ与Spring集成
在Spring中建立一个activemq.xml文件,使其内容如下:
其中:
<property name="alwaysSessionAsync" value=“true" />
对于一个connection如果只有一个session,该值有效,否则该值无效,默认这个参数的值为true。
<property name="useAsyncSend" value="true" />
将该值开启官方说法是可以取得更高的发送速度(5倍)。
<bean id="destination" class="org.apache.activemq.command.ActiveMQQueue">
<!-- 设置消息队列的名字 -->
<constructor-arg value="ymk.queue?consumer.prefetchSize=100" />
</bean>
在此我们申明了一个队列,并用它用于后面的实验代码。
consumer.prefetchSize则代表我们在此使用“消费者”预分配协议,在消费者内在足够时可以使这个值更大以获得更好的吞吐性能。
<property name="alwaysSessionAsync" value=“true" />
对于一个connection如果只有一个session,该值有效,否则该值无效,默认这个参数的值为true。
<property name="useAsyncSend" value="true" />
将该值开启官方说法是可以取得更高的发送速度(5倍)。
<bean id="destination" class="org.apache.activemq.command.ActiveMQQueue">
<!-- 设置消息队列的名字 -->
<constructor-arg value="ymk.queue?consumer.prefetchSize=100" />
</bean>
在此我们申明了一个队列,并用它用于后面的实验代码。
consumer.prefetchSize则代表我们在此使用“消费者”预分配协议,在消费者内在足够时可以使这个值更大以获得更好的吞吐性能。
工程中的pom.xml文件主要内容如下:
ActiveMQ与Spring集成-发送端代码
上述例子非常的简单。
它其实是启动了一个Message Listener用来监听ymk.queue中的消息,如果有消息到达,接收端代码就会把消息“消费”掉。
而发送端代码也很简单,它每次向ymk.queue队列发送一个文本消息。
这边所谓的MQ消费大家可以这样理解:
用户sender向MQ的KAHADB中插入一条数据。
用户receiver把这条数据select后,再delete,这个select一下后再delete就是一个“消费”动作。
它其实是启动了一个Message Listener用来监听ymk.queue中的消息,如果有消息到达,接收端代码就会把消息“消费”掉。
而发送端代码也很简单,它每次向ymk.queue队列发送一个文本消息。
这边所谓的MQ消费大家可以这样理解:
用户sender向MQ的KAHADB中插入一条数据。
用户receiver把这条数据select后,再delete,这个select一下后再delete就是一个“消费”动作。
简单消息与事务型消息
我们可以注意到上述的例子中我们的代码中有这样的一段:
session = conn.createSession(false, Session.AUTO_ACKNOWLEDGE);
它代表的是我们的MQ消费端消费模式为“自动”,即一旦消费端从MQ中取到一条消息,这条消息会自动从队列中删除。
ActiveMQ是一个分布式消息队列,它自然支持“事务”型消息,我们可以举一个例子
系统A和系统B是有一个事务的系统间“服务集成”,我们可以把它想成如下场景:
系统A先会do sth…然后发送消息给系统B,系统B拿到消息后do sth,如果在其中任意一个环节发生了Exception,那么代表系统A与系统B之间的消息调用这一过程为“失败”。
失败要重发,重发的话那原来那条消息必须还能重新拿得到。
此时我们就需要使用事务性的消息了。而事务性的消息是在:
生产端和消费端在创建session时,需要:
session = conn.createSession( true, Session.AUTO_ACKNOWLEDGE);
下面来看一个实际例子。
事务型消息发送端(生产端)
此处其它代码与普通式消息发送代码相似,只在以下几处有不同,首先在取得session时会声明事务开启“true”。
session = conn.createSession(true, Session.AUTO_ACKNOWLEDGE);
然后在发送时会有一个动作:
相应的在catch(Exception)时需要
事务型消息接收端(消费端)
在我们的接收端的createSession时也需要把它设为“事务开启”,此时请注意,生产和消费是在一个事务边界中的。
session = conn.createSession(true, Session.AUTO_ACKNOWLEDGE);
然后在接收时会有一个动作:
注意:
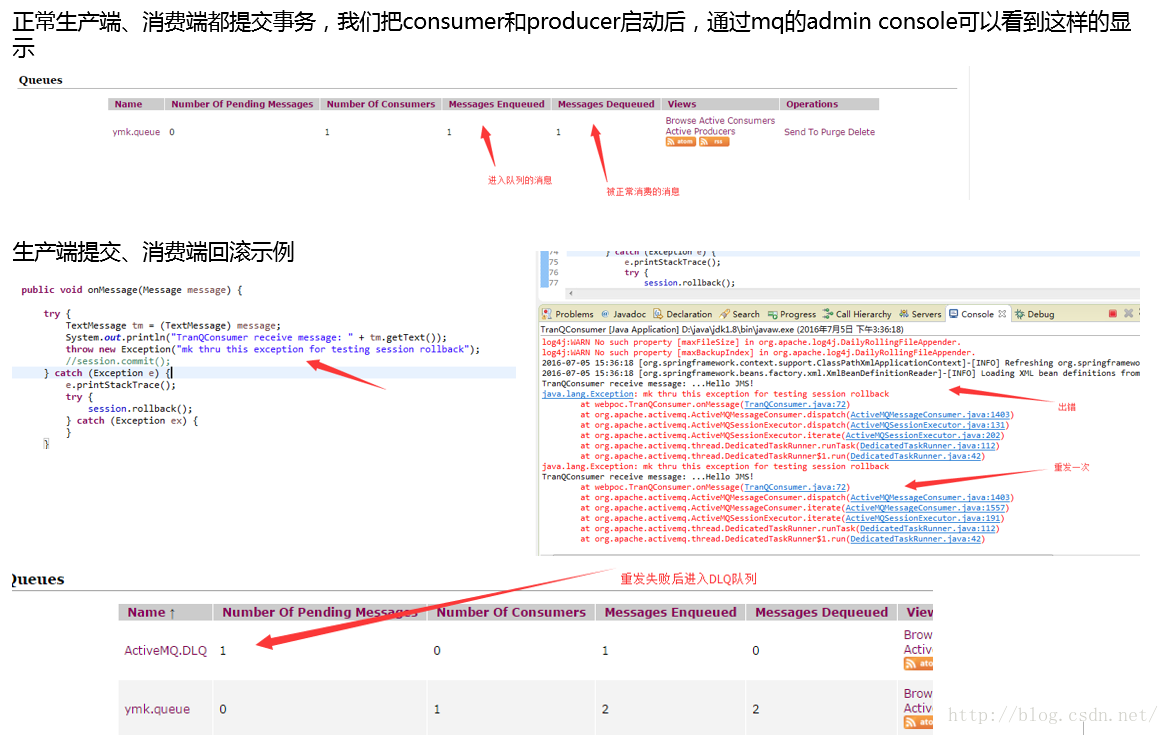
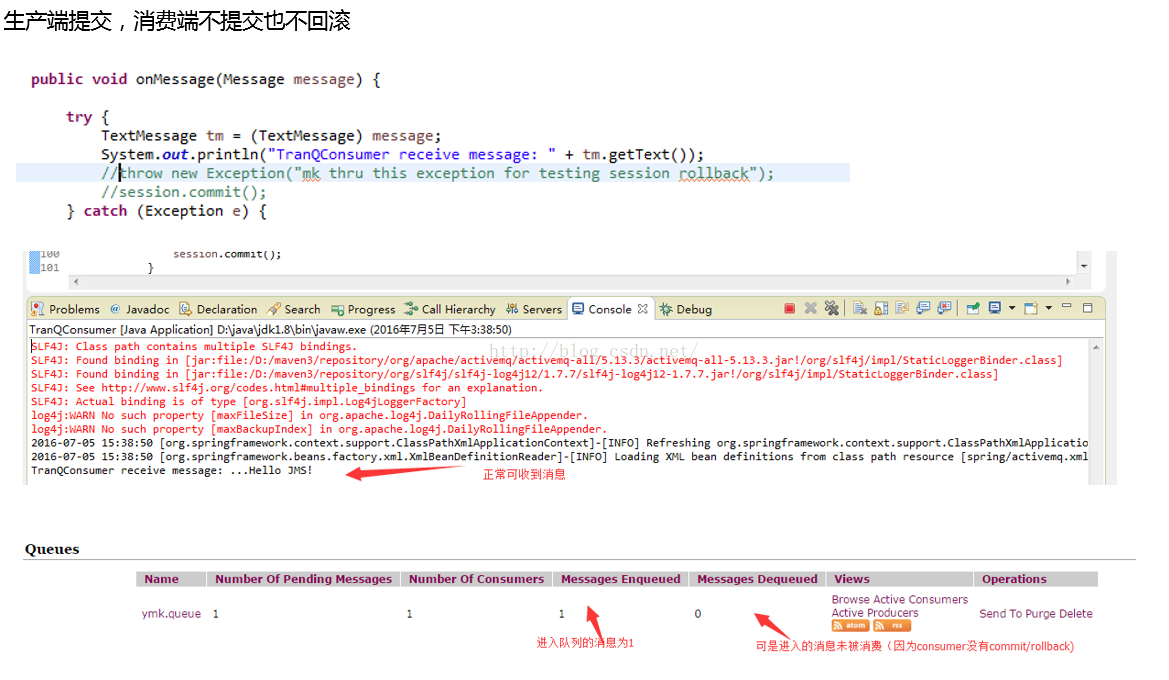
- 如果在消费端的onMessage中没有session.commit(),那么这条消息可以正常被接收,但不会被消费,换句话説客户端只要不commit这条消息,这条消息可以被客户端无限消费下去,直到commit(从MQ所persistent的DB中被删除)。
- 如果在消费断遇到任何Exception时session.rollback()了,ActiveMQ会按照默认策略每隔1s会重发一次,重发6次如果还是失败,则进入ActiveMQ的ActiveMQ.DLQ队列,重发策略这个值可以设(稍后会给出)。
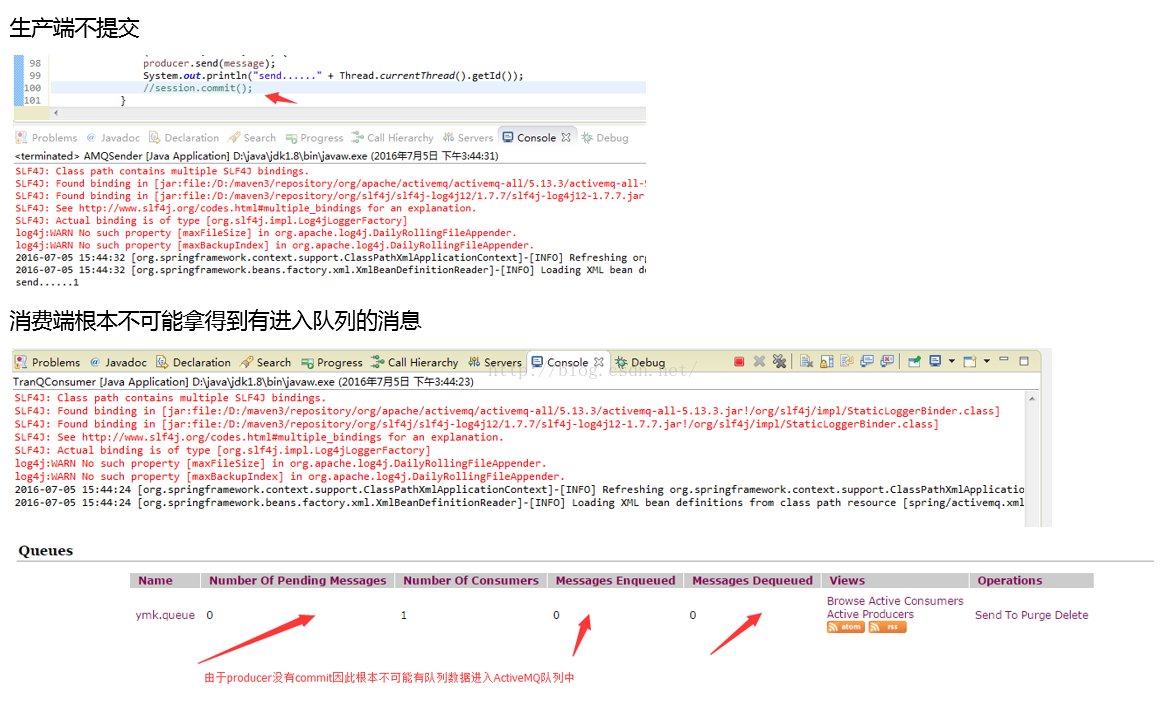
- 如果在生产端的try{}块里发生错误,导致回滚(没有commit),会怎么样?消费队列永远拿不到这条被rollback的消息,因为这条数据还没被插入KAHADB中呢。
- 再如果,消费端拿到了消息不commit也不rollback呢?那消费端重启后会再次拿到这条消息(因为始终取where status=‘未消费’取不到的原因,对吧?)
事务型消息的重发机制
以上例子申明了对于destination这个队列的重发机制为间隔100毫秒重发一次。
事务型消息的演示
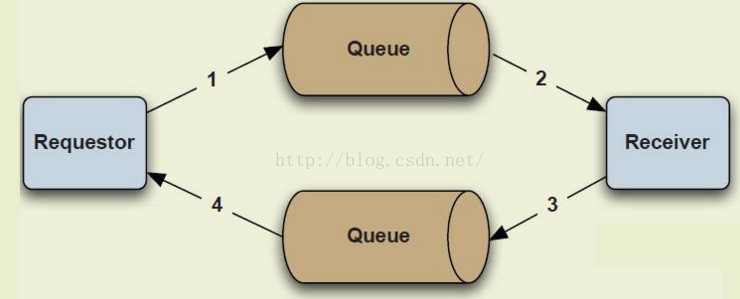
点对点,应答式消息
所谓点对点应答式消息和事务无关,它主要实现的是如:
生产端:我发给你一个消息了,在你收到并处理后请回复!因为我要根据你的回复内容再做处理
消费端:我收到你的消息了,我处理完了请查收我给你的回复
生产端:收到你的消息,88
生产端:我发给你一个消息了,在你收到并处理后请回复!因为我要根据你的回复内容再做处理
消费端:我收到你的消息了,我处理完了请查收我给你的回复
生产端:收到你的消息,88
点对点,应答式消息核心代码-配置部分

其实也没啥花头,就是多了一个队列(不要打我)
。。。。。。
关键在于代码,代码,不要只重视表面吗。。。要看内含的LA。。。
这两个队列其实:
一个Request
一个应答(也可以使用temp队列来做应答队列)
。。。。。。
关键在于代码,代码,不要只重视表面吗。。。要看内含的LA。。。
这两个队列其实:
一个Request
一个应答(也可以使用temp队列来做应答队列)
点对点,应答式消息核心代码-设计部分
我们设立两个程序:
它就是一个随机不可重复的数字,以String型传入API,也可以是GUID,它主要是被用来标示MQ 中每一条不同的消息用的一个唯一ID
JMSReplyTo
它就是一个生产端用来接收消费端返回消息的地址
- 发送端(生产端)内含一个MessageListener,用来收消费端的返回消息
- 服务端(消费端)内含一个MessageListener,用来收生产端发过来的消息然后再异步返回
- JMSCorrelationID
- JMSReplyTo
它就是一个随机不可重复的数字,以String型传入API,也可以是GUID,它主要是被用来标示MQ 中每一条不同的消息用的一个唯一ID
JMSReplyTo
它就是一个生产端用来接收消费端返回消息的地址
点对点,应答式消息核心代码-生产端部分代码
- RandomStringUtils
- replyDest
来看位于客户端(生产端)的messageListener吧
其余部分代码(没啥花头,就是sender里带了一个messageListener):
producer.send(message);
点对点,应答式消息核心代码-生产端所有代码
点对点,应答式消息核心代码-消费端部分代码
- 此处的send()方法内有两个参数,注意其用法
- 然后为这个消费端也加一个messageListener如:
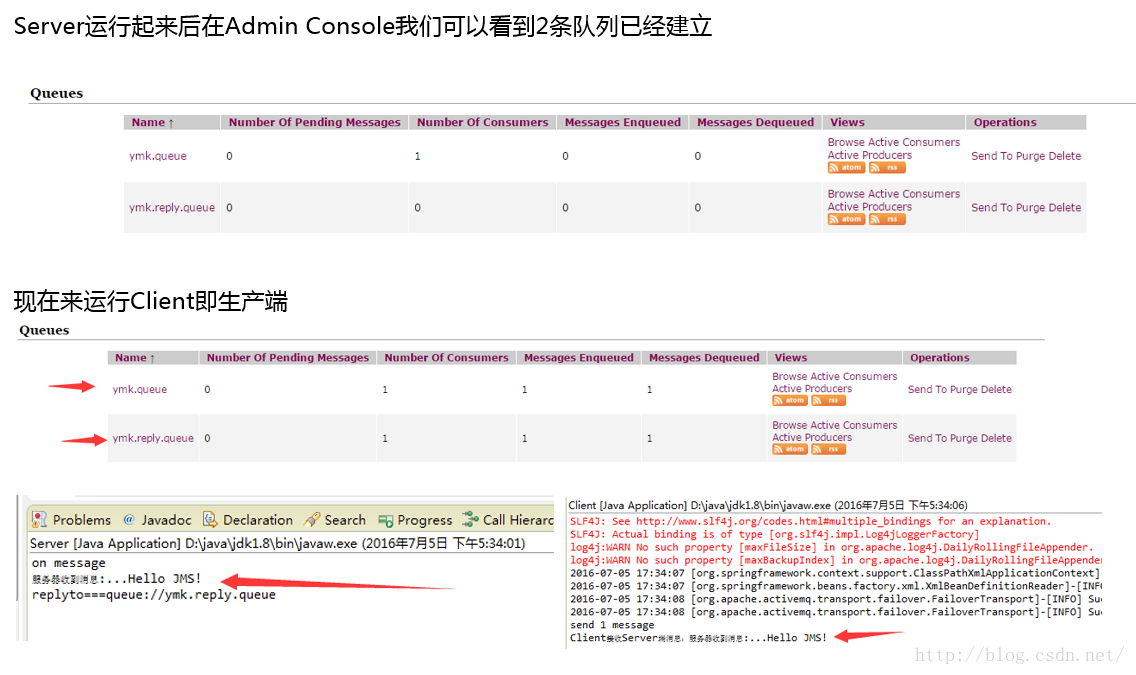
点对点,应答式消息核心代码-演示
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK