

learner - 博客园
source link: https://www.cnblogs.com/sliencer/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Unicode中跟汉字相关的一些内容的总结陈词
UniHan
这几天琢磨着怎么方便的给汉字注音, 因为要知道具体哪些Unicode是给汉字用的, 就读了读Unicode的官方文档. 目前unicode已经发展到了7.0. 不看不知道, 发现Unicode的定义中颇有些有趣的内容, 写下了给大家分享下, 也算是个笔记.
Unicode中跟汉字相关统称为UniHan, 官方文档在http://www.unicode.org/reports/tr38/
其中常用的缩写叫CJK, 就是中日韩的意思, 显然是把三种基于汉语的文字列在一起.
此文档内容讲了一大堆, 基本意思就是说这三种文字是同源的, 有很多统一的地方, 也有众多差异. Unicode中的文字并不是自己发明的或直接研究的成果, 而都是对各种现有权威资料的汇总和总结, 比如简体字主要基于中国的国标, 什么GB12345等. 除了定义每个字的字形和code point外, 还从其他资料中搜集了其他信息, 如拼音, 异体字, 笔画,简单的英文翻译,部首,康熙字典部首...
就拿其中我比较关心的拼音来说, uniHan有一个zip包, 叫UniHan.zip, ftp://www.unicode.org/Public/zipped/7.0.0/unihan.zip
其中文件UniHan_Readings.txt就包含了各种拼音信息. 截图如下:
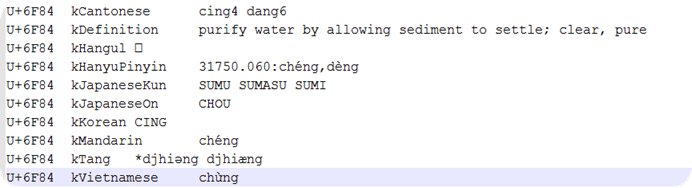
U+6F84就是汉字"澄"的code point, 从上面我们可以看到: 一个英语定义 kDefinition,
用广东话定义的发音kCantonese, kHanyuPinyin是<漢語大字典>中对此字的发音定义; kMandarin描述的是这个字在普通话中最常用的发音(对多音字有意义); 而其他日语韩语的部分我就看不懂了, 懂行的一看便知.
根据文档TR38记录, Unicode中的拼音搜集了四种
-
kHanyuPinlu
現代漢語頻率詞典
-
kHanyuPinyin
漢語大字典
-
kMandarin
-
kXHC1983
现代汉语词典
这个只是text格式的, 比较容易分析, 其他链接还有xml格式的, 我就不多说了.
文章中提到了X,Y,Z三轴的说法, 大概意思就是说所有的汉字都可以定位在X,Y,Z三个坐标轴上, 这是为了建立各个文字字形与其含义之间的关系. X轴代表含义,Y轴代表某个具体意思的字的各种字形, 而Z轴就是字形的小变形, 举个例子说: "說" "貓"两个字有完全不同的意思, 所以在X轴上是两个不同的值; "貓" 和 "猫"就是一个意思, 所有他们的X轴的值是相同的, 但由于字形有很大差异, 所以Y的值是不一样的; 而 "說"和"説"两个字X轴Y轴都是一样的, 但由于其写法的小差异,他们的Z值是不同的.
下面说说unihan 中字符的code point分布.
简单的说, 跟中文有关的有两个大部分, 一部分是各种汉字和日韩文字;另一部分是辅助的东西, 如偏旁部首, 全字符的英文, 全字符的标点符号,诸如此类.
先说基本的部分:汉字
汉字中最大的一部分叫CJK Unified Ideographs(中日韩统一表意符号集) U+4E00 – 9FCC

随后又有多次补充扩展
CJK Unified Ideographs Extension A
U+3400 – U+4DB5

CJK Unified Ideographs Extension B
U+20000 – U+2A6D6
CJK Unified Ideographs Extension C
U+2A700 – U+2B734
CJK Unified Ideographs Extension D
U+2B740 – U+2B81D

在这些extension之外,是几个为了兼容性而保留的几个区域
CJK Compatibility Ideographs U+F900 – U+FAD9
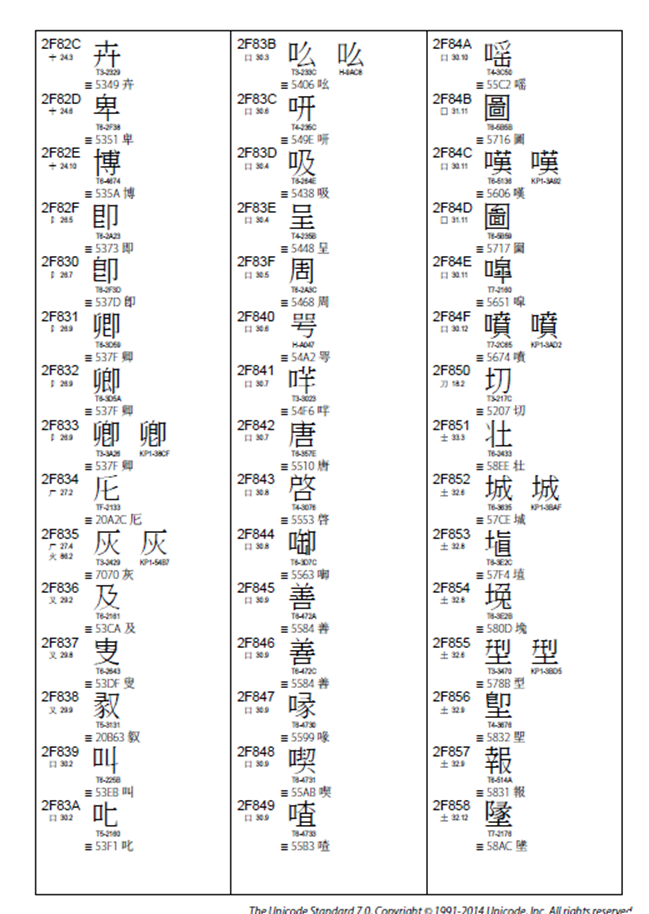
CJK Compatibility Supplement U+2F800 – U+2FA1D
(仔细看下面截屏, 每个字都等价对应到另一个code point)

说完了汉字, 后面相关的部分就比较乱了, 我就随便猜测了:
CJK Phonetics and Symbols Area 偏旁部首吧 U+2E80-U+2EF3
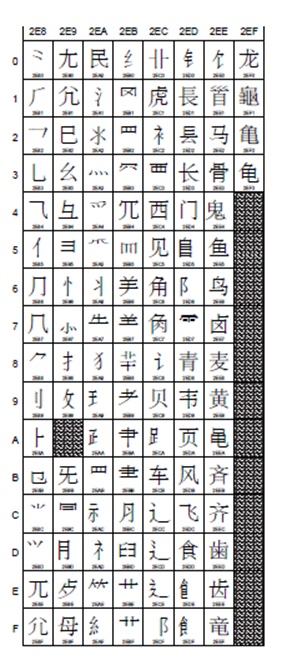
Kangxi Radicals康熙字典里的偏旁部首? U+2F00 – U+2FD5
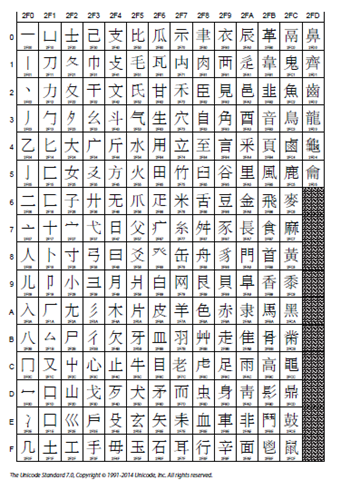
CJK Ideographic Description Characters 用来描述汉字结构的符号,如左右结构,上中下结构等 U+2FF0 - U+2FFB

CJK Symbols and Punctuation 符号 U+3000 -303F
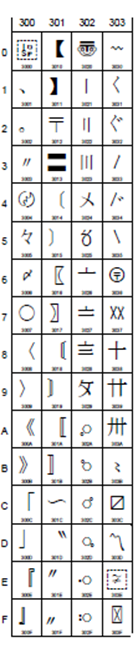
Bopomofo 老拼音? U+3105-312D, U+31A0 – U+31B7
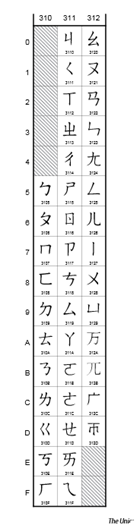
CJK strokes 笔画 U+31C0 – U+31E3
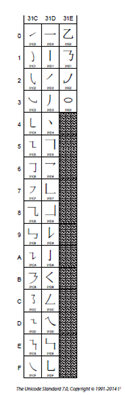
Enclosed CJK Letters and Months 其它奇奇怪怪的东西, 包括月份等等, 怀疑有没有人用啊 U+3220 – U+32CB
CJK Compatibility 另外很多奇葩的东西 U+3358-U+33FE

再有更过分的我就不都列了, 如易经八卦,麻将牌之类(是的, 麻将牌也能进Unicode, 震惊中)
其他
说完了UniHan, 说点儿别的相关的. 首先是平面分布的问题. 因为目前所有的unicode的code point都分布在0 到 0x10FFFF之间, 所以简单粗暴的根据每个字符的最高5个bit,分成17层, 第0层就是0-0xFFFF;1层就是0x10000 =0x1FFFF;2层为0x20000 – 0x2FFFF;以此类推;最后一层(16层) 0x100000 – 0x10FFFF. (真的好险, 层数在多点儿就可以和地狱比比了)
Anyway, 汉字主要分布在0层,个别分布在2层. 因为几乎所有人都基本工作在0层的,所以0层又称为BMP(Basic Multilingual Plane).
最后在聊点encoding, 在windows平台上最常用的是UTF-16, 也就是用16bit为单位来表达unicode. 那么哪些变态的超过0xFFFF的字符怎么办呢? 很简单, 在unicode中0-0xFFFF中预留了一块区域0xD800 – 0xDFFF是不允许任何字符集使用的, 这部分就被UTF-16用来编码. 编码的方式很简单, 超过0xFFFF的字符最大是16层的0x10FFFF, 共21位, 所以不管三七二十一, 所有大于0xFFFF的字符在编码前先减去0x10000, 这样的结果就是最多只有20位了, 然后一分二, 分为高10位和低10位;高10为与0xD800或一下, 得到的结果就是在0xD800到0xDFFF之间, 叫lead surrogate或者high surrogates; 低10位与0xDC00或一个(就是做个加法), 得到的结果就是trail surrogate或low surrogates. 搞定.
多加一句, 所谓的UCS-2是UTF-16的前身, UCS最大只支持到0xFFFF, 他的字符是定宽的, 没有surrogate一说, 它不能表达unicode的所有字符.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK