

ElasticSearch学习笔记
source link: https://jiajunhuang.com/articles/2020_07_04-elasticsearch.md.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

ElasticSearch学习笔记
搭建单节点ES
用Docker来搭建是比较简单的方式:
$ docker pull elasticsearch
$ docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch
ES引入了几个新的概念,我们和数据库对比一下:
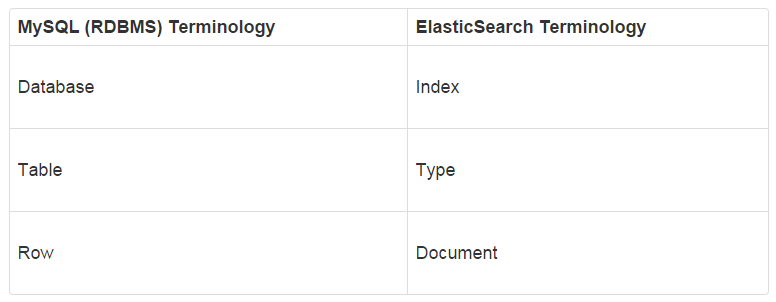
可以看到ES对应数据库的概念,然后看下ES在URL里如何对应这些概念:
http://host:port/[index]/[type]/[_action/id]
还有一个概念就是document,其实就是每一个JSON就是一个document。比如插入一个document:
$ http POST :9200/customer/doc2/1 name="John Doe"
这里,customer 就是index,doc2就是type,1 就是id,如果不想指定id,想要实现数据库里自增id的方式,就这样:
$ http POST :9200/customer/doc/ name="John Doye"
HTTP/1.1 201 Created
Location: /customer/doc/AXMTYwk4PDh6wP1Uklpb
content-encoding: gzip
content-length: 156
content-type: application/json; charset=UTF-8
{
"_id": "AXMTYwk4PDh6wP1Uklpb",
"_index": "customer",
"_shards": {
"failed": 0,
"successful": 1,
"total": 2
},
"_type": "doc",
"_version": 1,
"created": true,
"result": "created"
}
看,返回结果中, 就会把自动生成的id一起返回。 获取文档就要用到这个id:
$ http :9200/customer/doc/AXMTYwk4PDh6wP1Uklpb
HTTP/1.1 200 OK
content-encoding: gzip
content-length: 137
content-type: application/json; charset=UTF-8
{
"_id": "AXMTYwk4PDh6wP1Uklpb",
"_index": "customer",
"_source": {
"name": "John Doye"
},
"_type": "doc",
"_version": 1,
"found": true
}
ES本身就是为了搜索的,我们来看下如何搜索,搜索就是往 _search 这个endpoint请求:
$ http :9200/customer/_search
HTTP/1.1 200 OK
content-encoding: gzip
content-length: 258
content-type: application/json; charset=UTF-8
{
"_shards": {
"failed": 0,
"skipped": 0,
"successful": 5,
"total": 5
},
"hits": {
"hits": [
{
"_id": "AXMTWg-BPDh6wP1UklpX",
"_index": "customer",
"_score": 1.0,
"_source": {
"name": "John Doge"
},
"_type": "doc"
},
{
"_id": "2",
"_index": "customer",
"_score": 1.0,
"_source": {
"name": "John Dog"
},
"_type": "doc"
},
{
"_id": "AXMTYwk4PDh6wP1Uklpb",
"_index": "customer",
"_score": 1.0,
"_source": {
"name": "John Doye"
},
"_type": "doc"
},
{
"_id": "1",
"_index": "customer",
"_score": 1.0,
"_source": {
"name": "John Doe"
},
"_type": "doc"
},
{
"_id": "1",
"_index": "customer",
"_score": 1.0,
"_source": {
"name": "John Doe"
},
"_type": "doc2"
},
{
"_id": "_create",
"_index": "customer",
"_score": 1.0,
"_source": {
"name": "John Doge"
},
"_type": "doc"
}
],
"max_score": 1.0,
"total": 6
},
"timed_out": false,
"took": 62
}
瞧,这样,不带条件,就把所有的文档搜出来了。如果只想搜索一个 type 里的,那就:http :9200/customer/doc2/_search。
如果想搜索整个ES里的,那就:http :9200/_search。
更复杂的搜索,就要用到Elastic的Query DSL来进行操作了。
Query DSL
Query DSL比较灵活,代价就是相对复杂,其实是用JSON的形式,来表达查询规则。分为两种:
- query。query会模糊查找文档,然后根据匹配程度有一个打分,根据打分来排序。
- filter。filter就是看是否匹配,结果要么匹配,要么不匹配。相对简单。
最简单的DSL如下:
{
"query":{
"match_all": {}
}
}
作用就是查询所有的文档。
可以根据 size 和 from 来指定从何处开始取结果,取多少:
$ cat query.json
{
"query":{
"match_all": {}
},
"from": 2,
"size": 1
}
$ http GET :9200/_search < query.json
HTTP/1.1 200 OK
content-encoding: gzip
content-length: 203
content-type: application/json; charset=UTF-8
{
"_shards": {
"failed": 0,
"skipped": 0,
"successful": 5,
"total": 5
},
"hits": {
"hits": [
{
"_id": "AXMTYwk4PDh6wP1Uklpb",
"_index": "customer",
"_score": 1.0,
"_source": {
"name": "John Doye"
},
"_type": "doc"
}
],
"max_score": 1.0,
"total": 6
},
"timed_out": false,
"took": 2
}
除了上面的 match_all,ES还有好几个查询语句,他们都是放在 query 里面,我们来看看:
match_all: 查询全部match: 简单匹配multi_match: 在多个字段上执行相同的match查询query_string: 可以在查询里边使用AND或者OR来完成复杂的查询term: term可以用来精确匹配,精确匹配的值可以是数字、时间、布尔值range: range用来查询落在指定区间内的数字或者时间bool: bool可以通过must,must_not,filter,should把多个查询条件组合起来
聚合查询就更强大了,这个还是直接看文档吧:https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html

关注公众号,获得及时更新
在KVM里安装Minikube
Python RQ(Redis Queue)添加gevent支持
使用shairport-sync搭建airplay音频服务器
Recommend
-
35
各个业务数据“汇总到hive,经过ETL处理后,导出到数据库“是大数据产品的典型业务流程。这其中,sqoop(离线)和kafka(实时)几乎是数据总线的标配了。但是有些业务也有不标准的,比如hive数据导入到ES.hive数据导入到ES,官方组件是elasticsearch-hadoop.其用法在前面的...
-
55
当前的笔记只介绍 Elasticsearch 的搜索部分。 文章中的搜索都是在 kibana 的 Dev tools 进行查询的。 准备工作 需要安装 Elasticsearch 、
-
12
Elasticsearch 学习笔记 配置说明Development 与 Production模式说明参数修改的第二种方式
-
4
Elasticsearch 学习笔记 发表于 2021-02-14 ...
-
8
ELK-学习笔记–elasticsearch的mapping |坐而言不如起而行! 二丫讲梵 > 日志管理 >
-
17
本文预计阅读时间 22 分钟 2019年5月21日,Elastic官方发布消息: Elastic Stack 新版本6.8.0 和7.1.0的核心安全功能现免费提供。 这意味着用户现在能够对网络流量进行加密、创建和管理用户、定义能够保护索引和集群级别访问权限的角色,并且...
-
8
ELK-学习笔记–elasticsearch的日常维护参数 |坐而言不如起而行! 二丫讲梵 > 日志管理 >
-
21
本文预计阅读时间 12 分钟 prometheus监控es,同样采用exporter的方案。 项目地址: elasticsearch_exporter:https://github.com/justwatchcom/elasticsearch_exporter 1、安装部署 现有es三...
-
12
本文预计阅读时间 13 分钟 索引生命周期管理将会是es维护管理中重要的一环,生产中已经有一个集群用的 7.x 版本,一直也没有使用自带的生命周期管理工具,今天就来研究一下,现在先通过简单的例子来理解这个功能以及用法。 1,...
-
2
Elasticsearch学习笔记 文档(document):每条数据就是一个文档 词条(term):文档中按照语意分开后的词语 索引(index):相同类型文档的集合 映射(mapping):索引对文档字段的约束,类似于数据表的结构约束
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK