

后SoC时代或将迎来Chiplet拐点
source link: https://zhuanlan.zhihu.com/p/110233934
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

后SoC时代或将迎来Chiplet拐点
作者:痴笑
导读:我们正站在SoC设计方法论到chiplet的拐点上,本文的观点目前来看可能比较科幻,实际上却是非常符合半导体行业发展的规律。这里先把结论罗列出来(1)Chiplet拐点将带领集成电路生态将迈入“打土豪分田地"的新时期;(2)Chiplet拐点面前,新形态体系结构形态的将提倡富含想象力的小而美,并且“去中心化”;(3)Chiplet拐点将诞生一类新型态的富含模拟电路芯片——有源基板(active interposer),它将终结低电压低增益低匹配的先进工艺模拟设计困局。
打土豪,分田地
如果用一个字来概来涵盖单芯片片上系统(Monolithic SoC)方案与芯粒(Chiplet)方案,我会选天朝人民最耳熟能详的“拆”字。简而言之,就是把原来一块大的单芯片,拆分为多个小芯片的组和,然后通过高级封装重组。以前我们也把这样的模式称为System-in-Package,2.5D/3D封装。2015年,Marvell的老板还把这样的模式称为芯片界的乐高——麻糬计划(Mochi)。
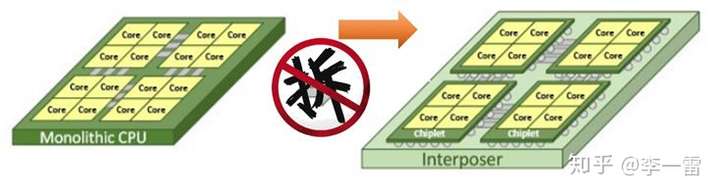
但是SiP早期只是满足不同工艺间芯片的链接,比如CPU/GPU和DRAM的异构集成。所以当时Chiplet被提出以后,也就是少数几个学有余力的学霸间的花式表演。SoC在过去的很长一段时间,仍然是主流,Chiplet拐点从未真正到来。
然而,世界发展地太快。AI来了,贪欲来了,土豪炫富心态也来了。Monolithic SoC芯片在过去几年进入了“贫穷限制了想象力”的新境界——
首先推波助澜的英伟达黄教主,收到人工智能的助力,英伟达的旗舰GPU从100mm2,开始指数级发展。去年发布的Volta架构核弹级GPU——GV100的面积率先突破800mm2大关,据说今年即将推出的Ampere系列新核弹级GPU将在7nm工艺达到826mm2 【瑟瑟发抖】。
然后就是那些不要face的初创小妮子们,为了造一个个大新闻,变得毫无”节止“(此处不带贬义)—— 其中最有名的当推硅谷初创 Cerebras Systems的AI芯片,面积达到了令人发指的46,225mm2,(你没有看错,那是逗号!)片上SRAM达到18GB 【我只能说你咋不上天呢?】:
如此大面积的芯片,有良率么,有意义么?下图统计了良率与面积大小的关系,对于小于10mm2的芯片而言,monolithic方案和chiplet方案的良率差别很小,但是一旦芯片面积超过200mm2,monolithic方案的良率会比chiplet方案低超过20%。可以预期,在700-800mm2的面积上,monolithic方案的良率很可能不超过10%。
由此,对于要商业化卖钱的芯片而言成本问题就活生生地体现了。假设研发费用是相同的,那么可以分摊研发一次性费用NRE的芯片数量,chiplet会比monolithic高3-4倍,如果进一步考虑良率,chiplet方案的成本价将远远低于monolithic方案。
AMD公司在ISSCC2020年上就以其多核架构为例子,对比了AMD服务器级别设计中,采用chiplet方案和monolithicSoC方案的成本,可见芯片越大monlithic方案和的成本比在chiplet高的越多,并且能保持在一倍以上。
诚然,土豪们与新贵们依旧可以炫富。但是chiplet却是高性能芯片(组)打开市场化,完成生态的最有效捷径。
正所谓,他强由他强,清风拂山岗;他横由他横,明月照大江;他自狠来他自恶,我自一口真气足。“小而美”的专用芯片们,只要能搭上chiplet高速列车,终究笑到最后才是王道。
去中心化的新架构形态
故事讲到这里,看官们你或许会问,chiplet是不是只会给庞然大物带来冲击?小打小闹的呢?我在过去的很长一段时间,也简单的认为,chiplet是是巨头们的乐高玩具,学术界的玩家既玩不起,也没啥必要玩。
直到今年的ISSCC,当头一棒点醒了我。
还用乐高做例子。乐高除了有图纸按图索骥的标准玩法,还有给出元模块自定义乐高的高级版——Lego MOC (My Own Creations),每年乐高官方都会有Lego MOC的最佳评比。小编某天还在B站抖音刷到过一个用乐高做的洗丑袜子专用迷你洗衣机。
即便如此,乐高迷们仍然不足以满足MoC的需求,此时,3D打印的普及进一步冲击了乐高的世界——用户可以自定义元积木的任何形状,然后打印出来,以填补官方元间库的不足。好事者还用Lego MOC自己打造打一个3D打印机的教程。于是,乐高的世界打开了新维度的新大门~
当3D打印遇上乐高MOC搭乐高当然有不同的搭法,搭chiplet也一样。常规方法就是按照目前高性能计算体系结构的研究成果,按图索骥搭出如下类SoC的标准化结构,以主控/多核CPU为核心+并行计算协处理器(GPU,AI芯片)+ 堆叠的Memory+IO是常规操作。(下图来自ISSCC 2020 法国CEA的chiplet paper)
与常规操作相对应的,就是非主流杀马特了。Chiplet的发展会催生非常多目前不存在的芯片形态,或者大大简化某些形态的芯片进入主流平台的过程。
在这个过程中,“去中心化”或将成为一个重要的特点。
先来看AMD的Server级处理器Chiplet方案——二代EPYC。(这家伙在7nm工艺下耗电280W,据前方记者报道,该芯片在ISSCC现场demo用液氮冷却云山雾罩,远观还以为是炊烟袅袅)
AMD的Chiplet方案方案,由其Ryzen系列芯片演化而来。然而,在逐渐演化的过程中,系统的核心从CCX高性能计算核,逐步变成了一颗一存储和互联为主的IOD核。而且AMD还给IOD的互联拓扑结构,起了一个“复仇者联盟”式的名字——无限结构,infinity fabric。
而原本在系统中起着关键作用的处理器核心,变成了一个可以被scaling的元素:2/4/6/8,任意数量的核心方案都可以定制,要多少买多少,经济实惠。
Chiplet的这种新型配置带来的主客异位的变化是否会引发体系结构的新一轮讨论?这种新形态下的互联方式和存储模式,还有没有必要遵从目前主流的片上网络/总线的模式?毕竟从物理学上,其电路的拓扑结构已经不一样了。他也应该不同于现在繁琐的PCIe等一链接版上原件为主的桥连接方法,毕竟还是够近,通信间即便需要一些协议,也应该是简单的。
法国CEA在ISSCC 2020提出了他们的建议:采用如下的全数字,全摆幅,极简的准同步握手机制,完成chiplet间通信。chiplet间通信的延时采用延时补偿的机制,相比于片内SoC的延迟,只提高了1到3倍,根据距离长短,完全可估计。相比于目前的LPDDR之类的协议,无论在电路复杂度还是能效上都有显著提高。
在这种特征下,“去中心”化的设计理念是保障芯片组间可以静态重构的重要前提。毕竟很可能Chiplet的主体再也不是拥有译码能力的处理器核心,而是一个并没有多少处理能力的片上网络。与此同时,每一个Chiplet的键位上可以放芯片类型也将更加不拘一格。除了今年ISSCC提到的微处理器,还可以是如今火爆的存算一体芯片,领域专用芯片,非典型CMOS工艺(ReRAM / MEMS / TFET / ...)的IoT芯片等等,以及更多发挥想象力的新型芯片。只要你流的起片,去他的超大规模SoC设计验证,小而美的百花齐放才是春天。
总之一句,Chiplet拐点到来后,玩家绝不仅是土豪,去中心化发展会让土豪们面临各种“特洛伊”陷阱。
模拟电路能摆脱scaling down噩梦了?
不同于AMD,Intel和CEA设计chiplet方案时,还推出了一种全新功能定义的电路来实现chiplet——active interposer,有源基板。
早期的Chiplet基板,实现的功能完成芯片间的互联和芯片pin脚到封装pin脚的扇出功能,取代wire bond方案里面长长引线的寄生效应,可以简单的理解为是密度更高、体积更小的PCB版,也被称为无源基板, passive interposer。
但是,今年ISSCC上法国CEA提出的有源基板却令人眼前一亮:
有源基板讲白了就是一颗工艺节点大、面积大、能做底盘的新型芯片,由于是完整的芯片,设计师可以自定义这颗芯片的方案。
在CEA的方案中,不仅可以用于链接,同时通过实现路由功能(router)在基板上完成类片上网络的互联。更惊艳的是,他在基板上实现了基于开关电容的稳压电源。由于基板工艺的节点比高性能计算的节点大很多、成本低很多,所以,用基板工艺做一些用能量存储的大容量片上电容一点都不心疼。这时候也完全不用担心先进工艺下各种开关的各种非理想(漏电/浅沟槽阈值调制)等非理想效应。
过去十年,模拟电路工程师们被摩尔定律逼的要多惨有多惨。Scaling下先进工艺那低于1V的电源电压,(却没有scaling热噪声的幅度,SNR又不允许下降);越来越低的输出阻抗,导致放大器的增益难以为继;甚至是40nm后开始的不可理喻的版图匹配要求,还有FinFET开始的栅极电阻……种种麻烦都在把基于运算放大器的传统模拟电路往绝路上逼。模拟工程师们只能调转枪头往Digital PLL / Digial LDO / SAR ADC / Digital PA等不少基于数字电路的模拟设计上走,可总有些电路是要靠放大器的。
然而chiplet却给了让这一困局新的思路——把适合大工艺节点的模拟电路放在有源基板上。同时,还包括那些占面积超大的无源器件,这个方法同时还能将最大程度地提高先进工艺的利用效率,把昂贵的工艺花在刀刃上。让做放大器的模拟工程师远离先进工艺的噩梦,回到亚微米时代自由发挥的黄金岁月。
下图是Intel在今年ISSCC 2020的Chiplet 产品——lakefield的Foveros 3D封装平台里提到的如何布局计算芯片(Compute Die)和基板芯片(Base Die)的策略。高压(比如高压串行接口USB/LVDS,用于同步的晶振)、无源、电源管理、以及对Scaling Down不敏感的模拟电路,还有各类经典(温度等)传感器统统可放在基板大节点工艺上。
顺带提一句,当在选择不同节点的基板时,还能发挥初异构的功耗优势。比如Intel在选择基板上用了超低漏电的节点(22FFL),然后将standby的相关电路集成到大基板上去,进一步优化stand功耗。这是传统SoC不具有的选项。
chiplet拐点也让模拟工程师可以喘口气,不再被scaling down追着打了。
能看到这里的读者们,你对Chiplet心动了么?如果您有更多comments,欢迎留言。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK