

df与du输出结果不同的原因研究
source link: https://kernel.taobao.org/2019/08/why-df-and-du-output-different/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Aug 13, 2019 • 付林 齐江
df与du输出结果不同的原因研究
Question
标准GNU工具coreutils中有俩程序df / du,他们都可以查看磁盘的使用情况。通常情况下他们的统计结果并不会相同,这是因为统计信息来源的差异。所以问题来了:在ext4文件系统下,有哪些可能的因素会带来统计信息的差异?
Knowledge Background
ext4 filesystem
physical structure overview
Unix-like 文件系统,有file / dentry / inode / superblock的概念。在文件系统这一层次,只存在superblock与inode,前者保存的是文件系统的元信息(metadata),后者是文件的metadata;file与进程相关联,记录了进程打开文件的上下文信息;使用dentry建立的机制(dcache),提供了加速使用文件名查找文件方法。
磁盘与光盘的最小存储单位是扇区(sector),操作系统每次I/O的首选长度(block size)称为块(block),文件系统上最小的分配单位(fragment size)叫做fragment。传统机械硬盘的单位扇区大小为512字节,现代机械硬盘的扇区大小可以是4096字节。Linux系统下,block size几乎可以认为等于fragment size。[2][3][4]
inode(index node)作为文件数据的索引信息而存在,记录了inode number、文件元信息、文件数据块的索引信息。inode存储在block中,默认大小是128字节,因此一个block可以存储多个inode,数个存储inode的block组成inode table。
为了加速空闲block与inode的查找,设计了bmap与imap,它们采用位图的方式标识block或inode是否被使用。
inode table、bmap、imap过大也不利于查找,因此将一定数量的block划分成块组(block group)。每个block group都包含自己的metadata区域(存储inode table、bmap、imap)与数据区域。 ext2 / ext3采用直接/间接寻址(Direct/Indirect Block Addressing)的方式索引data block,而ext4采用Extent Tree的方法,这减少了大文件下metadata对空间的占用。
每个block group的元信息使用GDT(group descriptor table)描述。考虑到未来文件系统扩容的需要,出现了保留GDT(Reserved GDT)。
superblock的存在是为了记录block数量与使用量等文件系统的metadata,它存储在0号block group中。为了防止superblock的损坏,在特定的block group中会保存备份。修改GDT/Reserved GDT会导致superblock的更改,因此他们仨会放在一起。
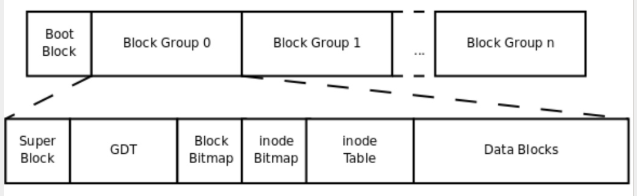
详细内容参考第4章 ext文件系统机制原理剖析,man page: ext4,Linux doc: ext4 Data Structures and Algorithms,Ext4 (and Ext2/Ext3) Wiki与The Second Extended File System。 ext4文件系统相关的命令行工具有:e2fsprogs、fuse2fs、e2tools。
inode,soft link(aka symbolic link) / hard link,and mount –bind
inode与文件是一对一的关系,将inode与文件关联后使用inode number而非文件名来识别文件。
Linux下文件的种类有七种,ls -l会看到具体的文件类型:
$ ls -ail /dev/cdrom /etc/fstab
9837 lrwxrwxrwx 1 root root 3 Jul 17 11:06 /dev/cdrom -> sr0
1310722 -rw-r--r-- 1 root root 643 Jul 1 17:39 /etc/fstab
^ | |
| | +-- file size
| +---------------- link count
+-------------------------------- inode number
?: 未知文件类型(some other file type) -: 普通文件(regular file) d: 目录(directory) c: 字符设备文件(character special file) b: 块设备文件(block special file) s: 套接字(socket) p: 命名管道(FIFO, named pipe) l: 软链接(symbolic link, aka soft link)
排除未知文件,只有普通文件、目录与软链接可能存在data block。
每个目录文件都有data block,存储有该目录下所有的文件名,以及对应文件的inode number、文件类型。
Note: Linux doc: ext4 Data Structures and Algorithms, 4.1. Index Nodes提到了使用inode number查找inode的算法,大意是: inode table线性存储struct ext4_inode,有固定大小sb.s_inode_size,因为block group的存在,先查找所属group —— (inode_number - 1) / sb.s_inodes_per_group,在此group中对应的偏移量—— (inode_number - 1) % sb.s_inodes_per_group。不存在编号为0的inode。
对于非目录文件,硬链接的增加实际上是在目录的data block中加一项记录,同时inode中的引用计数加一,这也是为什么hard link无法跨文件系统的原因(inode number可能冲突)。删除非唯一的硬链接过程与添加相反,只有当inode的引用计数为0的时候,才将inode加入orphan inode list,在没有进程打开此文件后会进入文件的删除流程。
Note: lsof -a +L1可以显示当前的orphan inodes。它的原理是遍历/proc//fd/下的所有文件描述符,因为orphan inode对应的文件描述符有特殊的标志,所以可以枚举出对应的文件。 但若一个orphan inode的文件描述符与内核线程相关联,显然lsof无法枚举出来。[acct()](http://man7.org/linux/man-pages/man2/acct.2.html)系统可能导致这种情况的发生(issue: [Phantom full ext4 root filesystems on 4.1 through 4.14 kernels](https://www.spinics.net/lists/linux-ext4/msg62843.html))。 在kernel启用编译选项CONFIG_BSD_PROCESS_ACCT后,调用acct(filename)会开启process accounting,之后在每个进程终止的时后kernel会将统计信息[struct acct](https://elixir.bootlin.com/linux/v5.0/source/include/uapi/linux/acct.h#L44)写入filename。内核参数[/proc/sys/kernel/acct](http://man7.org/linux/man-pages/man5/proc.5.html)定义了accounting机制的行为。
对于目录文件,本身不存在硬链接的概念,ls -l显示的link count指的是该目录下一级文件中所有目录文件的总数(包含”.”与”..”,因此即使是空目录link count的值也是2)。不过[mount –bind ](http://man7.org/linux/man-pages/man8/mount.8.html)的作用与hard link一样,只不过link count不增加罢了,而且它可以跨文件系统。
符号链接(symbolic link)又称软链接(soft link),它的作用是指向原文件或目录,存储的是目标文件路径,只有当目标文件路径字符串大于60字节的时候才会被分配一个data block,因此它的大小通常为0。
- link management
创建软链接、硬链接,除了通过操作系统间接管理的方式,比如shell提供的[ln]与系统调用symlink()、link(),还可以直接操作存储介质,比如e2fsprogs中的debugfs,e2tools中的e2ln。
debugfs -w -R "link ( | )"可用于创建hard link,然而:
ln filespec dest_file
Create a link named dest_file which is a hard link to filespec. Note this does not adjust the inode reference counts.
v1.44.5的debugfs -R “link …“并不会带来link count的变化,v0.0.16.4的e2ln也同样如此(因为他们从读取到写入的逻辑几乎是一致的)。
ext4 file system mount option / feature
- bsddf / minixdf
ext4提供了挂在选项bsddf / minixdf(默认bsddf),它影响了statfs()获取到的f_blocks(Total data blocks in filesystem)。
/**
* int ext4_statfs(struct dentry *dentry, struct kstatfs *buf)
*/
if (!test_opt(sb, MINIX_DF))
overhead = sbi->s_overhead;
buf->f_blocks = ext4_blocks_count(es) - EXT4_C2B(sbi, overhead);
Note: e2fsprogs在resize/resize2fs.c中对overhead做出了解释: Overhead is the number of bookkeeping blocks per group. It includes the superblock backup, the group descriptor backups, the inode bitmap, the block bitmap, and the inode table.
- has_journal 拥有has_journal feature的ext4会启用日志功能,文件系统的日志也会占用block,这些blocks在格式化分区的时候确定。statfs()系统调用在获取信息时并不一定会将journal blocks排除在外——挂载时启用选项minixdf,f_blocks在计算时并不会减去journal blocks (这部分blocks属于overhead的一部分)。# mkfs.ext4 -J size=journal-size 可在格式化分区的时候指定journal的大小为\<journal-size\>。
/**
*
*/
resv_blocks = EXT4_C2B(sbi, atomic64_read(&sbi->s_resv_clusters));
if (!test_opt(sb, MINIX_DF))
overhead = sbi->s_overhead;
buf->f_blocks = ext4_blocks_count(es) - EXT4_C2B(sbi, overhead);
bfree = percpu_counter_sum_positive(&sbi->s_freeclusters_counter) -
percpu_counter_sum_positive(&sbi->s_dirtyclusters_counter);
/* prevent underflow in case that few free space is available */
buf->f_bfree = EXT4_C2B(sbi, max_t(s64, bfree, 0));
buf->f_bavail = buf->f_bfree -
(ext4_r_blocks_count(es) + resv_blocks);
if (buf->f_bfree < (ext4_r_blocks_count(es) + resv_blocks))
buf->f_bavail = 0;
debugfs -R “stat <8>” 或# dumpe2fs | grep -i journal可以获取到journal size:
# debugfs -R "stat <8>" /dev/loop2
debugfs 1.42.9 (28-Dec-2013)
Inode: 8 Type: regular Mode: 0600 Flags: 0x80000
Generation: 0 Version: 0x00000000:00000000
User: 0 Group: 0 Size: 134217728
File ACL: 0 Directory ACL: 0
Links: 1 Blockcount: 262144
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x5d3956d3:00000000 -- Thu Jul 25 03:14:27 2019
atime: 0x5d3956d3:00000000 -- Thu Jul 25 03:14:27 2019
mtime: 0x5d3956d3:00000000 -- Thu Jul 25 03:14:27 2019
crtime: 0x5d3956d3:00000000 -- Thu Jul 25 03:14:27 2019
Size of extra inode fields: 28
EXTENTS:
(0-32766):1081344-1114110, (32767):1114111
# dumpe2fs /dev/loop2 | grep -i journal
dumpe2fs 1.42.9 (28-Dec-2013)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Journal inode: 8
Journal backup: inode blocks
Journal features: journal_64bit
Journal size: 128M
Journal length: 32768
Journal sequence: 0x00000002
Journal start: 1
Note: <8>代表inode为8的文件,它是一个special inode,属于journal。
- inline data
Linux v3.8之后,ext4添加了一项feature:inline data。LWN.net: Improving ext4: bigalloc, inline data, and metadata checksums提到:
大部分文件系统下存在两类inode:一类是存在与内核中、与文件系统无关的inode(`struct inode),一类是在存储介质上保存、文件系统相关的inode(on-disk inode)。对第二类inode的维护意味着IO操作。 on-disk inode的大小在文件系统创建后便确定,默认大小是256字节,但实际上只需要大约一半的空间,其余空间常用来存储文件的额外属性。 文件的存储需要分配额外的block。若存在太多的小文件,则会造成大量block的浪费。如果使用了clustering (数个block组成一个更大的block cluster,文件系统分配的最小单位是block cluster。feature: bigalloc),这种空间浪费会更加严重。
inline data的提出是便是为了解决这种存储空间浪费的问题。启用inline_data特性的ext4文件系统,在文件小于60字节的时候不会被分配data block,数据将会存储在inode中。
man page描述df:report file system disk space usage。coreutils中的df使用了glibc的statvfs(),间接地调用系统调用statfs()家族,数据来源于文件系统的super block。
它的输出,即–output的参数有以下几种:
source: The source of the mount point, usually a device.
fstype: File system type.
itotal: Total number of inodes.
iused: Number of used inodes.
iavail: Number of available inodes.
ipcent: Percentage of IUSED divided by ITOTAL.
size: Total number of blocks.
used: Number of used blocks.
avail: Number of available blocks.
pcent: Percentage of USED divided by SIZE.
file: The file name if specified on the command line.
target: The mount point.
与空间大小有关输出以block的数量计算,输入的block大小从文件系统的super block中获取,输出的大小可以通过参数-B / –block-size指定,默认1024字节。
输出信息的数学表达式如下:
# about inode
<total inodes> = <statvfs.f_files>
<available inodes> = <statvfs.f_free>
<used inodes> = <total inodes> - <available inodes>
# about block count
<total blocks> = <statvfs.f_blocks> * <block size> / <output block size>
<available blocks> = <statvfs.f_bavail> * <block size> / <output block size>
<used blocks> = (<statvfs.f_blocks> - <statvfs.f_ffree>) * <block size> / <output block size>
Note:
- df是优先从/proc/self/mountinfo获取挂载的设备信息的,如果不存在该文件则是/proc/self/mounts。/proc/self/下存在三个以mount为前缀的文件,详见man page proc。
- df对存储空间的统计是以block的数量而非字节为单位。
- KiB/kiB与KB/kB是不同的,前者是2的幂,后者是10的幂,即Kibibit与Kibibyte的区别。
man page描述du:estimate file space usage。它的原理是深度优先遍历目标文件目录下的所有文件(非orphan inode),使用stat()家族获取文件信息。
影响du输出结果的因素有以下几种:
- follow symbolic links?
- count sizes many times if hard linked?
- use apparent sizes rather than disk usage?
- is output unit SIZE-byte blocks?
在实现上,是否遍历符号链接指向的文件,区别在与是否fstatat()的flag是否设置了AT_SYMLINK_NOFOLLOW。 文件去重是基于hash的,对硬链接的判断则是观察inode中硬链接的计数是否大于1,当然排除了文件目录的可能性。 因为stat()获取的文件大小是真实大小(以字节为单位),并非分配的block units size,因此通过向上取整获取block units的方式计算出block units size。 至于最后一个,只是做了单位的转换。
Conclusion
假如文件系统正常(即不存在bug、一致性问题),操作系统、软件也不存在bug,那么存在这么几种可能性:
- 进程导致的orphan inodes
- 用户态进程导致,可使用$ lsof -a +L1查看;
- 系统调用acct(),无法在/proc中得知文件的打开状态。
- mount –bind导致的重复计数
- 直接操作存储设备建立hard link导致的hard link计数异常
- debugfs command # debugfs -w -R "link ..."
- ext4 mount option / feature
- bsddf / minixdf
- has_journal
- inline_data
- 因小文件过多带来的实际分配空间(block units)与实际文件大小(apparent size)之间的差异
- du参数–apparent-size
- 输出的计量单位不同带来的差异
- du与df参数-B, –block-size=SIZE
若系统的状态不正常,df / du统计信息的巨大差异有可能是orphan inodes导致的:即inode->i_nlink == 0 && inode->i_count != 0,同时不存在进程关联了此inode。 为此,我开发了一个诊断模块,目前已集成到diagnose-tools。一个使用案例如下:
$ insmod diagnose.ko
$ echo "vda1" > /proc/ali-linux/diagnose/fs/dump_orphan
$ cat /proc/ali-linux/diagnose/fs/dump_orphan
device "vda1" orphan list:
inode 262188 (ffff88003803f0e8): mode 40755, nlink 0, count 1
inode 262189 (ffff88003803d0e8): mode 40755, nlink 0, count 1
inode 262930 (ffff88003803c8e8): mode 40755, nlink 0, count 1
inode 262931 (ffff88003803c0e8): mode 40755, nlink 0, count 1
inode 262932 (ffff88003803d8e8): mode 40755, nlink 0, count 1
inode 262933 (ffff88003803fce8): mode 40755, nlink 0, count 1
inode 262934 (ffff88003c3e90e8): mode 40755, nlink 0, count 1
$ # or use script after insmoding module:
$ ali-diagnose report-dump-orphan vda1
device "vda1" orphan list:
inode 262188 (ffff88003803f0e8): mode 40755, nlink 0, count 1
inode 262189 (ffff88003803d0e8): mode 40755, nlink 0, count 1
inode 262930 (ffff88003803c8e8): mode 40755, nlink 0, count 1
inode 262931 (ffff88003803c0e8): mode 40755, nlink 0, count 1
inode 262932 (ffff88003803d8e8): mode 40755, nlink 0, count 1
inode 262933 (ffff88003803fce8): mode 40755, nlink 0, count 1
inode 262934 (ffff88003c3e90e8): mode 40755, nlink 0, count 1
Reference
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK