

Apache Flink: Flink on Zeppelin Notebooks for Interactive Data Analysis - Part 2
source link: https://flink.apache.org/ecosystem/2020/06/23/flink-on-zeppelin-part2.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Flink on Zeppelin Notebooks for Interactive Data Analysis - Part 2
23 Jun 2020 Jeff Zhang (@zjffdu)
In a previous post, we introduced the basics of Flink on Zeppelin and how to do Streaming ETL. In this second part of the “Flink on Zeppelin” series of posts, I will share how to perform streaming data visualization via Flink on Zeppelin and how to use Apache Flink UDFs in Zeppelin.
Streaming Data Visualization
With Zeppelin, you can build a real time streaming dashboard without writing any line of javascript/html/css code.
Overall, Zeppelin supports 3 kinds of streaming data analytics:
- Single Mode
- Update Mode
- Append Mode
Single Mode
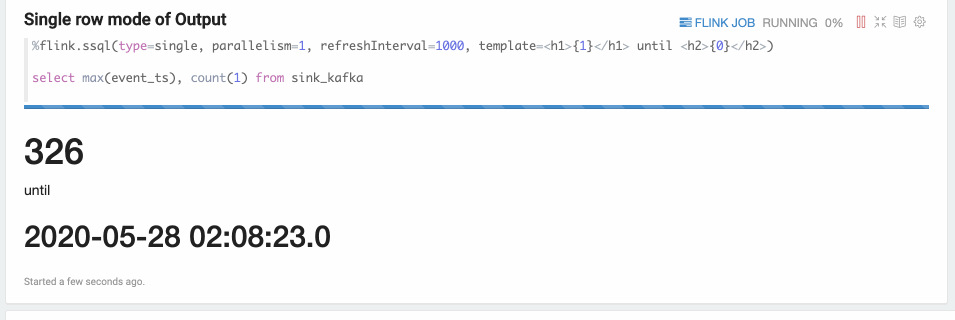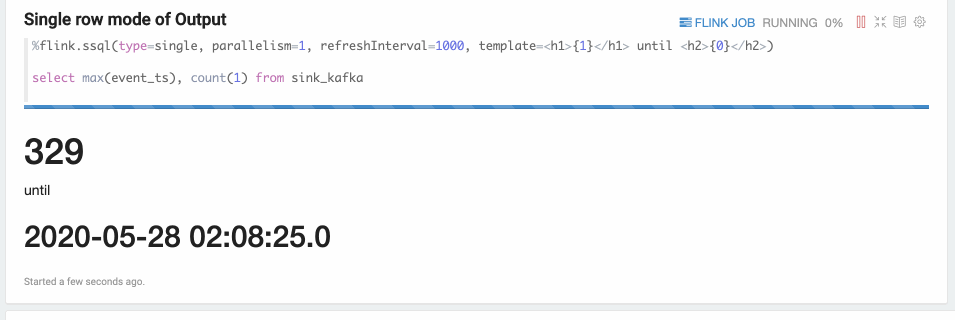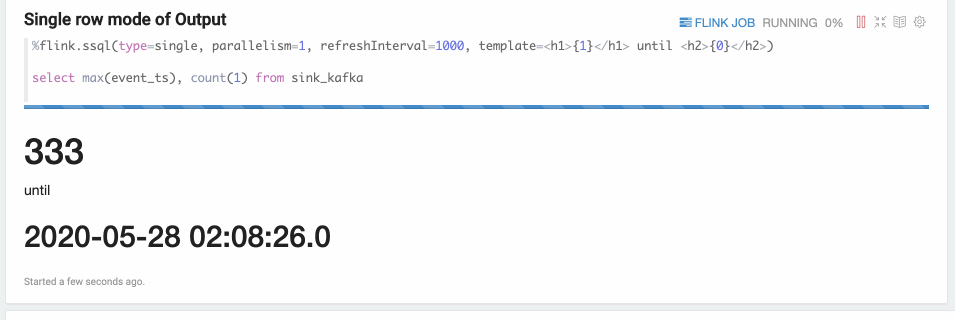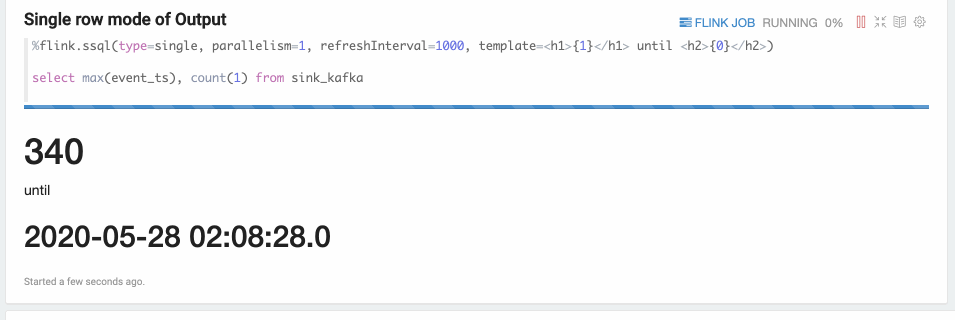
Single mode is used for cases when the result of a SQL statement is always one row, such as the following example.
The output format is translated in HTML, and you can specify a paragraph local property template for the final output content template.
And you can use {i} as placeholder for the {i}th column of the result.
Update Mode
Update mode is suitable for the cases when the output format is more than one row,
and will always be continuously updated. Here’s one example where we use GROUP BY.
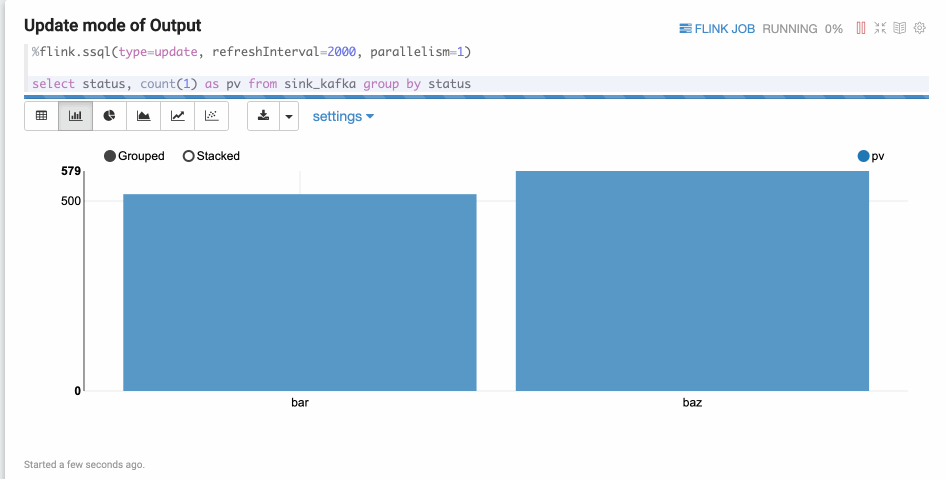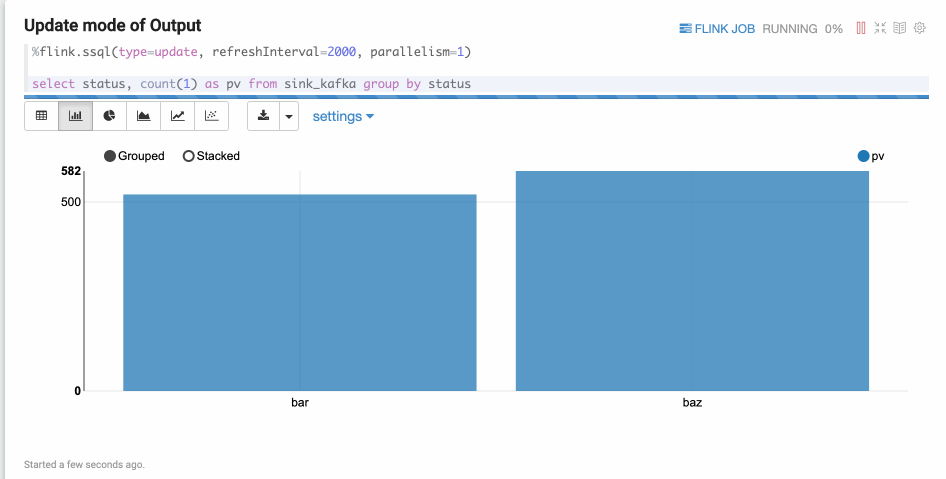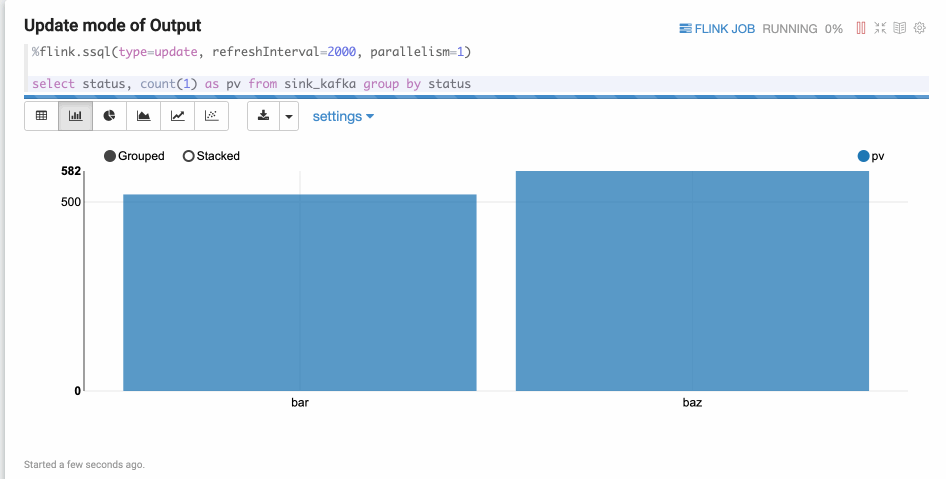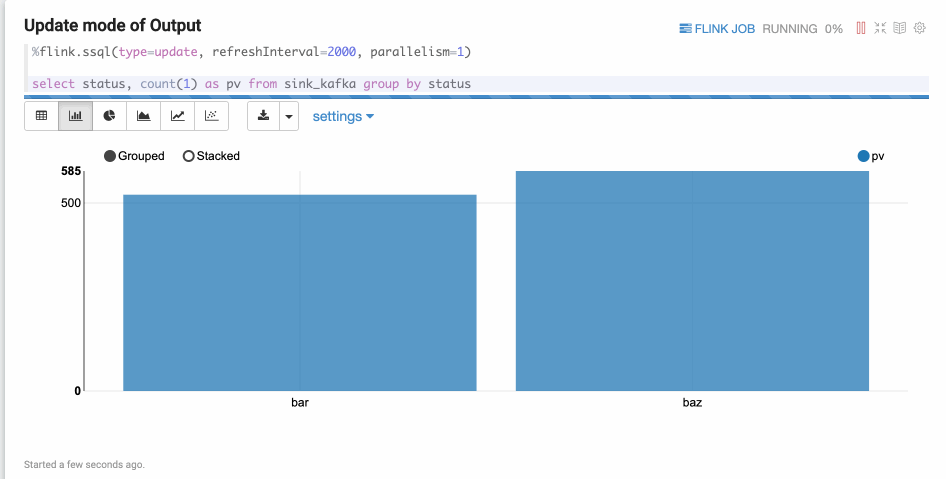
Append Mode
Append mode is suitable for the cases when the output data is always appended. For instance, the example below uses a tumble window.
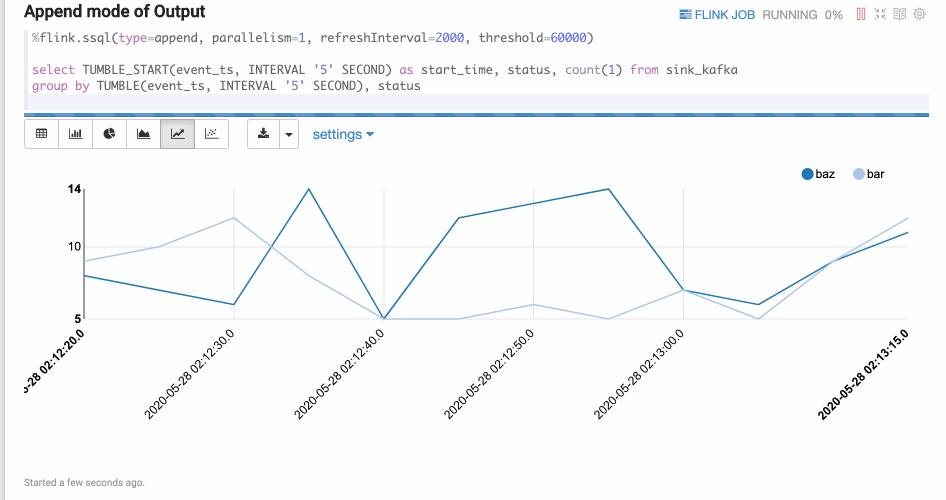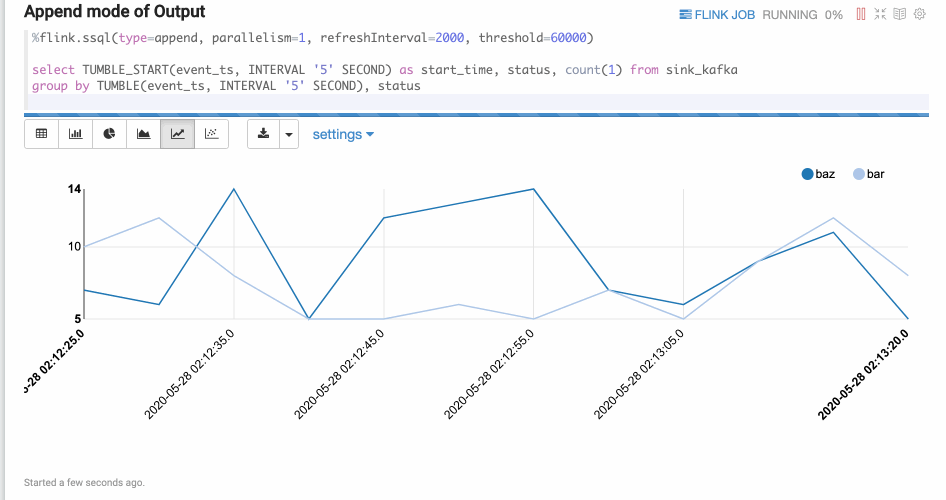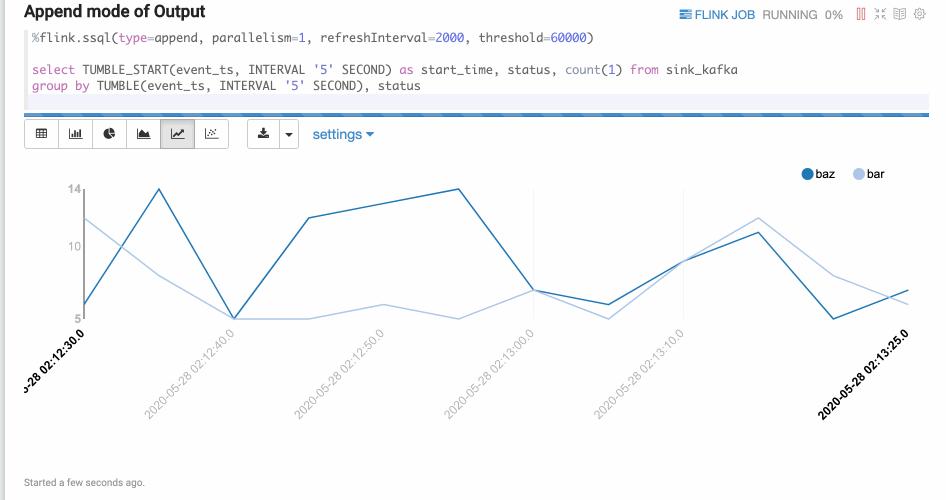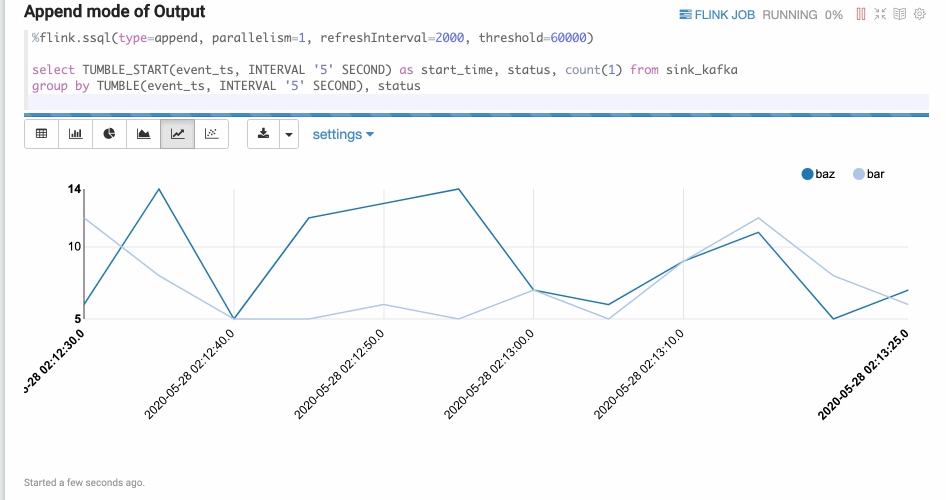
SQL is a very powerful language, especially in expressing data flow. But most of the time, you need to handle complicated business logic that cannot be expressed by SQL. In these cases UDFs (user-defined functions) come particularly handy. In Zeppelin, you can write Scala or Python UDFs, while you can also import Scala, Python and Java UDFs. Here are 2 examples of Scala and Python UDFs:
- Scala UDF
%flink
class ScalaUpper extends ScalarFunction {
def eval(str: String) = str.toUpperCase
}
btenv.registerFunction("scala_upper", new ScalaUpper())- Python UDF
%flink.pyflink
class PythonUpper(ScalarFunction):
def eval(self, s):
return s.upper()
bt_env.register_function("python_upper", udf(PythonUpper(), DataTypes.STRING(), DataTypes.STRING()))After you define the UDFs, you can use them directly in SQL:
- Use Scala UDF in SQL
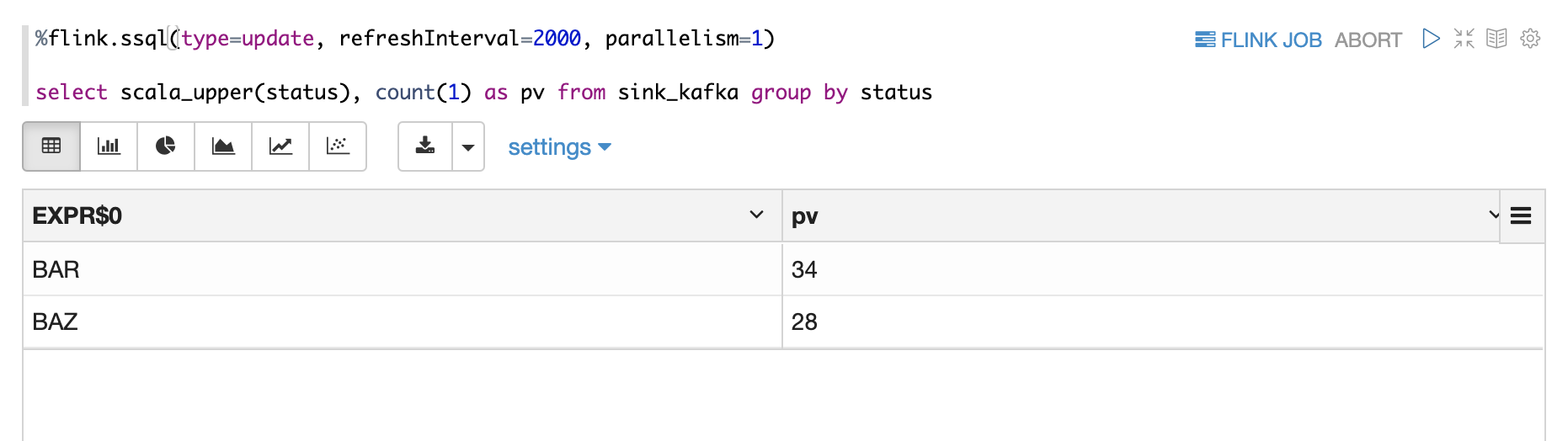
- Use Python UDF in SQL
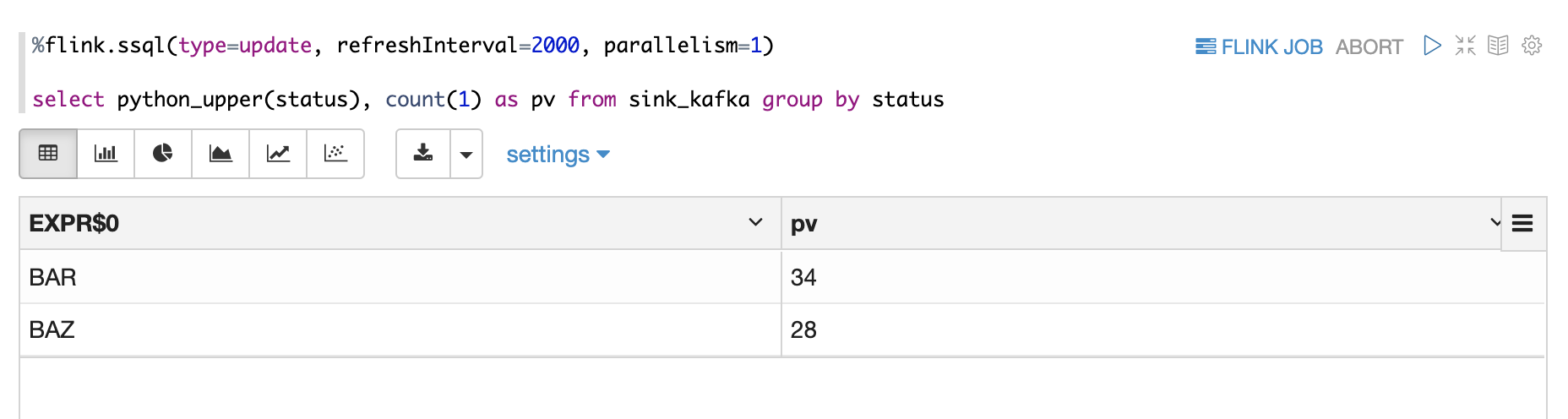
Summary
In this post, we explained how to perform streaming data visualization via Flink on Zeppelin and how to use UDFs. Besides that, you can do more in Zeppelin with Flink, such as batch processing, Hive integration and more. You can check the following articles for more details and here’s a list of Flink on Zeppelin tutorial videos for your reference.
References
- Apache Zeppelin official website
- Flink on Zeppelin tutorials - Part 1
- Flink on Zeppelin tutorials - Part 2
- Flink on Zeppelin tutorials - Part 3
- Flink on Zeppelin tutorials - Part 4
- Flink on Zeppelin tutorial videos
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK