

深入剖析Macho (1)
source link: http://satanwoo.github.io/2017/06/13/Macho-1/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

最近在公司里和一些同事搞了一些东西,略微底层。于是希望借这个机会好好把Macho相关的知识点梳理下。
虽然网上关于Macho的文章介绍一大堆,但是我希望能够从Macho的构成,加载过程以及需要了解的相关背景角度去进行分析,每一个点都力图深入。也会在这篇文章最后打造一个类似class-dump的小型工具。
程序启动加载的过程
当你点击一个icon启动应用程序的时候,系统在内部大致做了如下几件事:
- 内核(OS Kernel)创建一个进程,分配虚拟的进程空间等等,加载动态链接器。
- 通过动态链接器加载主二进制程序引用的库、绑定符号。
虽然简要概述很简单,但是有几个需要特别主要的地方:
- 二进制程序的格式是怎么样的?内核是如何加载它的?
- 内核是如何得知要使用哪种动态链接器的?
- 动态链接器和静态链接器的区别是啥?
- 程序在运行前究竟要做哪些步骤?顺序是怎么样的?
带着这些问题,我将一步步来剖析整个过程
二进制程序格式
在MacOS或者iOS上可执行的程序格式叫做Macho-O,它的主要成分如下图所示:

- 一个
mach_header标记一些元信息,比如架构、CPU、大小端等等 - 多个
Load Command告诉你究竟如何加载每个段的信息。 - 多个
Segement及Section,包含了每个段自身的信息。包括一些数据、代码以及段的执行权限等等。
Macho-O,目标文件(.o)以及动态库,静态库都是Mach-O格式。所以,下面我们就用64位的定义从每个部分来介绍一下具体的数据结构:
mach_header_64
这个结构体代表的都是Mach-O文件的一些元信息,它的作用是让内核在读取该文件创建虚拟进程空间的时候,检查文件的合法性以及当前硬件的特性是否能支持程序的运行。
从源码中可以看出,整个结构题定义如下:
struct mach_header_64 {
uint32_t magic; /* mach magic number identifier */
cpu_type_t cputype; /* cpu specifier */
cpu_subtype_t cpusubtype; /* machine specifier */
uint32_t filetype; /* type of file */
uint32_t ncmds; /* number of load commands */
uint32_t sizeofcmds; /* the size of all the load commands */
uint32_t flags; /* flags */
uint32_t reserved; /* reserved */
};
- magic 用于标识当前设备的是大端序还是小端序。如果是
0xfeedfacf(MH_MAGIC_64)就是大端序,而0xcffaedfe(MH_CIGAM_64)是小端序,iOS系统上是小端序。 - cputype 标识CPU的架构,比如ARM,X86,i386等等,进行了宏观划分。
- cpusubtype 具体的CPU类型,区分不同版本的处理器。
- filetype 划分之前我们提到的文件类型,比如是可执行文件还是目标文件。
- ncmds 有几个
LoadCommands,每个LoadCommands代表了一种Segment的加载方式。 - sizeofcmds
LoadCommand的大小,主要用于划分Mach-O文件的‘区域’。 - flags 标记了一些dyld过程中的参数。
- reversed 没用。
这里有个比较有意思的问题是,我为了验证大端序小端序的问题的时候,用了MacOS上的计算器进行
验证,本质上这应该是个小端序的应用程序,其二进制如下:
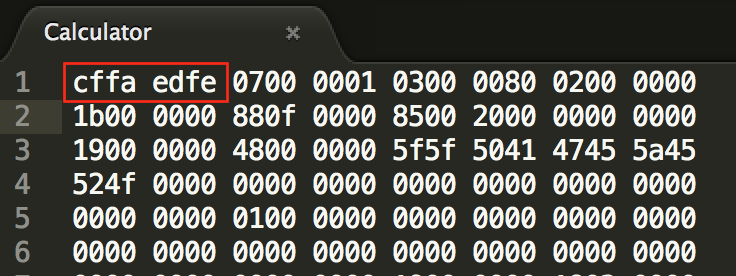
但是在otool和MachoView上看出来都是MH_MAGIC_64,如下所示:

我擦,这下看了懵逼,难道是我理解错了?于是赶紧翻了下class-dump代码,其解析header部分代码如下:
// 解析部分代码
_byteOrder = CDByteOrder_LittleEndian;
CDDataCursor *cursor = [[CDDataCursor alloc] initWithData:data];
_magic = [cursor readBigInt32];
if (_magic == MH_MAGIC || _magic == MH_MAGIC_64) {
_byteOrder = CDByteOrder_BigEndian;
} else if (_magic == MH_CIGAM || _magic == MH_CIGAM_64) {
_byteOrder = CDByteOrder_LittleEndian;
} else {
return nil;
}
// readBigInt32的代码
- (uint32_t)readBigInt32;
{
uint32_t result;
if (_offset + sizeof(result) <= [_data length]) {
result = OSReadBigInt32([_data bytes], _offset);
_offset += sizeof(result);
} else {
[NSException raise:NSRangeException format:@"Trying to read past end in %s", __cmd];
result = 0;
}
return result;
}
我们在用LLDB看下_data里面的内容指向的内存地址:
(lldb) po _data
<OS_dispatch_data: data[0x100600b40] = { leaf, size = 199520, buf = 0x100281000 }>
用Xcode Memory看下:
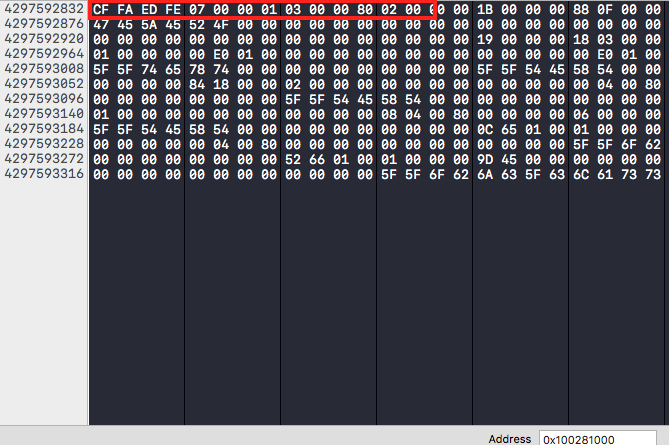
看起来是没错的。然后由于MacOSX本身是小端序的,CFFAEDFE这样的数据会被自动解析成FE ED FA CF。所以这样是有问题的。因此,class-dump采用了OSReadBigInt32的方式去解析:
OS_INLINE
UInt32
OSReadSwapInt32(
volatile void * base,
volatile UInt offset
)
{
union lconv {
UInt32 ul;
UInt8 uc[4];
} *inp, outv;
// 步骤1
inp = (union lconv *)((UInt8 *)base + offset);
// 步骤2
outv.uc[0] = inp->uc[3];
outv.uc[1] = inp->uc[2];
outv.uc[2] = inp->uc[1];
outv.uc[3] = inp->uc[0];
// 步骤3
return (outv.ul);
}
这个方法会利用union的特性,进行数据交换。我们还是用刚刚的例子来验证:
- 步骤1按照默认方式读出数据:
FE ED FA CF。 - 步骤2进行交换,地址从低到高,分别是
FE ED FA CF。 - 步骤3利用
union的特性,当成一个32的数输出,按照默认小端序解析,会成为CF FA ED FE。也即是MH_CIGAM_64,是小端序。
其实按照MachoView的解析方式,将MH_CIGAM_64和MH_MAGIC_64理解成MACHO文件和当前平台的编码顺序是否一致更好,如果解析出来是MH_CIGAM_64则表示不一致;否则一致。
Segment(段)
讲完了Mach-O文件的header部分,我们需要进行Load Commands部分。但是在这之前,我想先大致介绍下Mach-O中的Segment及其下属的Section(节),让大家能更好的理解Load Commands。
从整体上来说,Mach-O里面包含的段有以下这些:
- __TEXT 代码段/只读数据段
- __PAGEZERO Catch访问NULL指针的非法操作的段
- __DATA 数据段
- __LINKEDIT 包含需要被动态链接器使用的信息,包括符号表、字符串表、重定位项表等。
- __OBJC 包含会被
Objective Runtime使用到的一些数据。
关于
__OBJC这个段,我是一脸懵逼的,从Macho文档上看,他包含了一些编译器私有的节。没有任何公开的资料描述,具体让我研究研究再说。
Section(节)
刚刚我们提到的__TEXT和__DATA段都分别有下属的节。
其中,比较难以理解的可能是__la_symbol_ptr,让我们还是来以计算器的例子来理解:
- 我们先从MachoView上找一个
stub,比如[xxxx -> _CFRelease]。 - 其数据是FF256A7C0000,结合这个节是在__TEXT段中,我猜测是应该一段汇编代码的16进制表示。
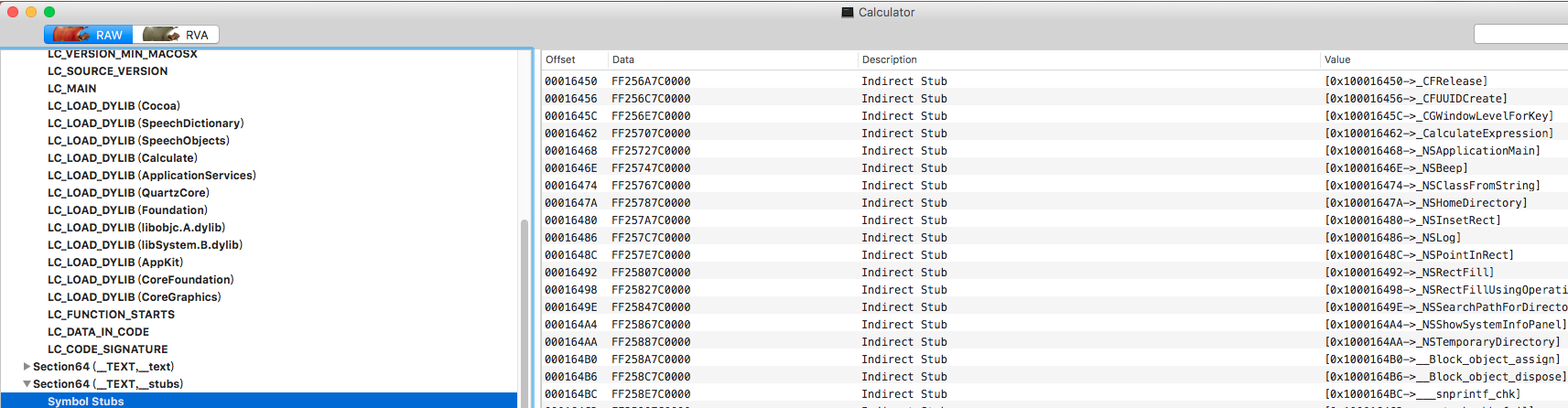
- 从Hopper中打开,查看对应偏移量的stub含义:
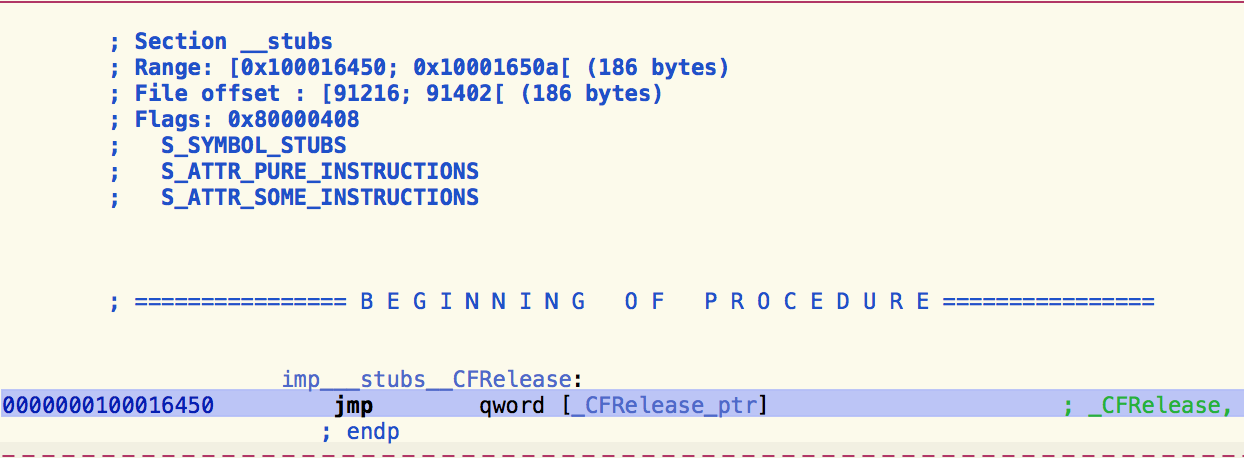
我们可以看到这段代码的16进制表达就是:
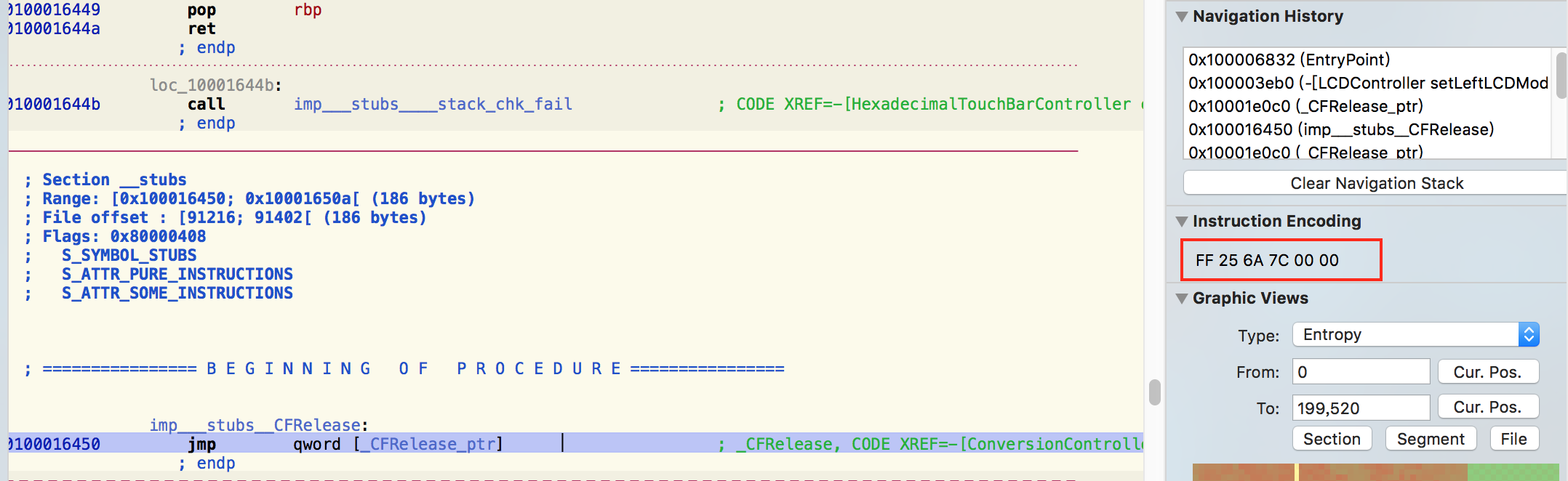
从上图不难看出,stub的含义就是跳转到以__la_symbol_ptr对应表项数据所指向地址的代码。
- 跳入以后,我们可以看到如下代码:
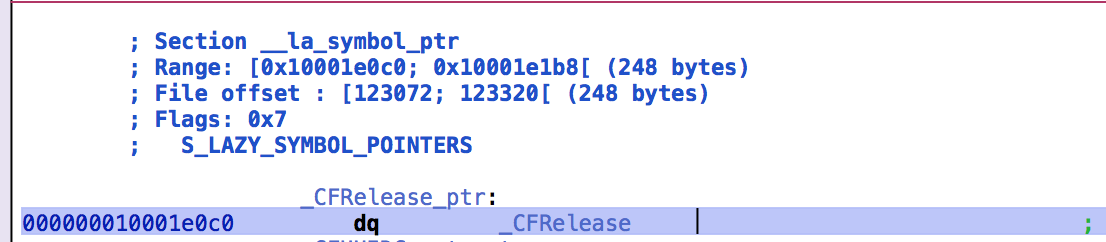
可以看到,在还没加载程序的时候,对应表项的数据还是dq _CFRelease。双击点进去看一下:
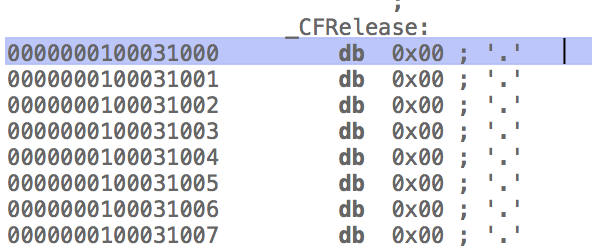
这里显示的应该是有点问题,如果全0的话是不可能使用lazy binding的。
我们还是用MachOView来看一下:

跳转到这个地址看看,没错了,处于stub_helper节里了:
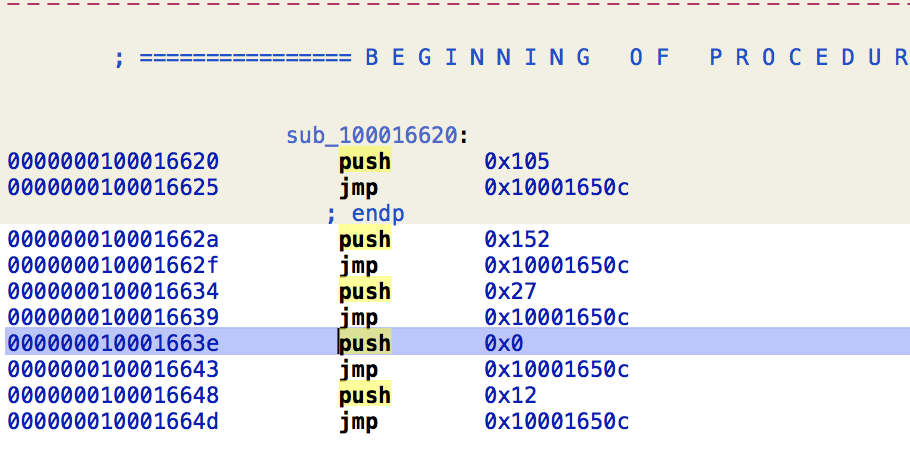
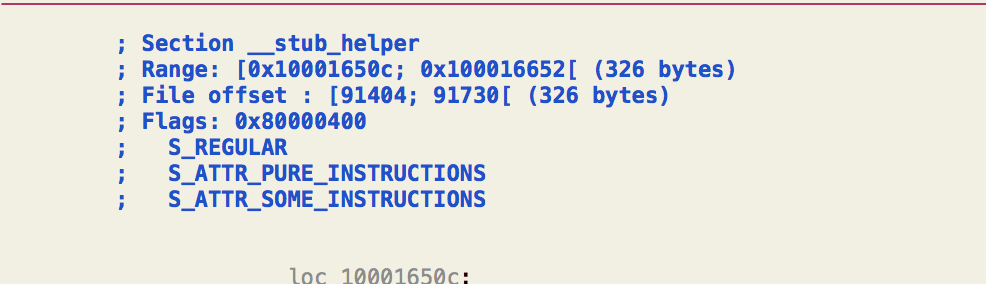
__la_symbol_ptr里面所有表项的数据都会被bind成dyld_stub_helper。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK