

python内置模块urllib介绍
source link: https://foofish.net/python-urllib.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

urllib 是 python 的内置模块, 主要用于处理url相关的一些操作,例如访问url、解析url等操作。
urllib 包下面的 request 模块主要用于访问url,但是用得太多,因为它的光芒全都被 requests 这个第三方库覆盖了,最常用的还是 parse 模块。 写爬虫过程中,经常要对url进行参数的拼接、编码、解码,域名、资源路径提取等操作,这时 parse 模块就可以排上用场。
一、urlparse
urlparse 方法是把一个完整的URL拆分成不同的组成部分,你可以根据自己的需求提取其中的某部分内容。 返回结果 ParseResult 是 namedtuple 的子类,由以下10部分组成,每部分既可以通过名字获取也可以通过下表索引得到。
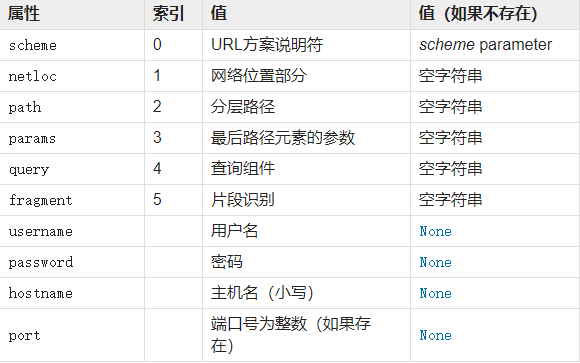
>>> from urllib import parse >>> url = 'https://mp.weixin.qq.com/s?__biz=MjM5MzgyODQxMQ==&mid=2650366919&idx=1&sn=1b36a9f2c0921cdeac52942ec591a923#rd' >>> result = parse.urlparse(url) # 返回ParseResult对象 >>> print(result) ParseResult(scheme='https', netloc='mp.weixin.qq.com', path='/s', params='', query='__biz=MjM5MzgyODQxMQ==&mid=2650366919&idx=1&sn=1b36a9f2c0921cdeac52942ec591a923', fragment='rd') # 通过下标获取协议 >>> result[0] 'https' # 协议 >>> result.scheme 'https' # url资源路径 >>> result.path '/s' # 查询参数 >>> result.query '__biz=MjM5MzgyODQxMQ==&mid=2650366919&idx=1&sn=1b36a9f2c0921cdeac52942ec591a923' # 获取主机名 >>> result.hostname 'mp.weixin.qq.com'
二、parse_qs
parse_qs 方法是将查询参数这部分内容从字符串转换成字典对象
>>> parse.parse_qs(result.query)
{'__biz': ['MjM5MzgyODQxMQ=='], 'mid': ['2650366919'], 'idx': ['1'], 'sn': ['1b36a9f2c0921cdeac52942ec591a923']}
>>>
每个参数名对应一个列表对象,这是因为在url规范中,一个参数名可以有多个值,例如: a=1&a=2,通常在实际应用场景中一般一个参数名只会对应一个值。
你可以用一行代码将列表转化为字符串
>>> {name: value[0] for name, value in parse.parse_qs(result.query).items()}
{'__biz': 'MjM5MzgyODQxMQ==', 'mid': '2650366919', 'idx': '1', 'sn': '1b36a9f2c0921cdeac52942ec591a923'}
三、urlencode
反过来,如果将一个字典对象想转换为url中的查询参数,那么就可以使用urlencode方法。
>>> d = {'__biz': 'MjM5MzgyODQxMQ==', 'mid': '2650366919', 'idx': '1'}
>>> parse.urlencode(d)
'__biz=MjM5MzgyODQxMQ%3D%3D&mid=2650366919&idx=1'
四、quote
在URL的标准规范中,url 只允许数字、字母和部分特殊符号的存在,如果有中文和某些特殊符号,就需要使用UTF-8进行编码,将这些字符转换成 %XX 的形式,例如: 【中】UTF-8编码的结果是:
>>> "中".encode() b'\xe4\xb8\xad'
那么浏览器实际上会把【中】转换成 %e4%b8%ad
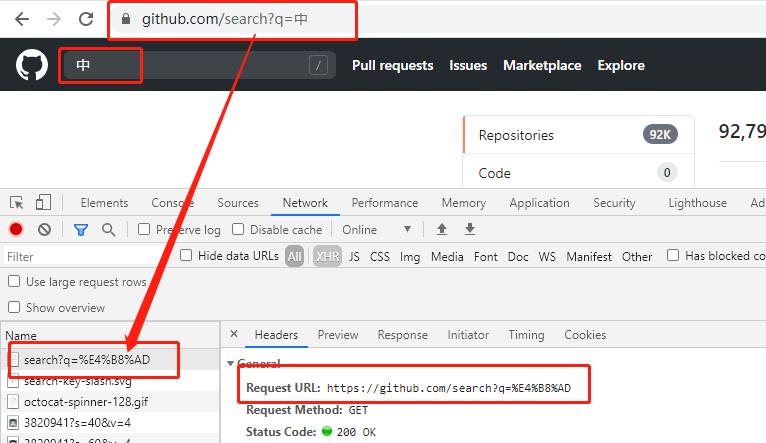
在python中,就可以用 quote 方法进行URL编码,对于特殊符号,也会进行成对应的16进制符号, 例如 【=】 就转换成了 %3D 。
>>> parse.quote("q=中")
'q%3D%E4%B8%AD'
>>>
quote_plus 可以将空格编码成“+”
>>> parse.quote_plus("a b")
'a+b'
>>> parse.quote("a b")
'a%20b'
五、unquote
unquote 是 quote 的逆向过程,称之为URL解码,解码方便开发者阅读
>>> parse.unquote("q%3D%E4%B8%AD")
'q=中'
有问题可以扫描二维码和我交流
关注公众号「Python之禅」,回复「1024」免费获取Python资源

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK