

重写 500 Lines or Less 项目 - Continuous Integration
source link: https://shuhari.dev/blog/2020/06/500lines-rewrite-ci
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

重写 500 Lines or Less 项目 - Continuous Integration
本文章是 重写 500 Lines or Less 系列的其中一篇,目标是重写 500 Lines or Less 系列的原有项目:持续集成系统(A Continuous Integration System)。本文部分借鉴了原程序的实现思路,但文章和代码都是从头编写的。相对于原文而言,本次重写在以下方面做出了比较重大的修改:
原文实现的是针对特定项目的持续集成服务器,系统的所有组件对项目内容都有充分的了解。这样的假定使得程序的实现更为简单,不需要额外配置或数据传递,但却失去了通用性:如果构建目标换成其他项目的话,该程序的很多组件都要进行较大改动。这对于现实的持续集成系统来说是不太合理的。
有鉴于此,本文试图实现一个更加通用的持续集成服务。其主要特点是“策略与实现分离”,也就是说,服务器内置多种基本组件,但对项目结构或构建方式不做硬性规定,而是通过配置来体现。服务的管理者只要修改配置,就能让它支持多种类型的项目、或者满足特定的项目需要,让它更具有灵活性,也更贴近真实的持续集成服务。
- 组件与通信机制
原文将系统分为三个独立运行的组件,分别在各自独立的进程中运行,彼此之间通过 Socket 通信。
本文的实现机制则有所不同。程序仍然有三个主要组件,但职责划分和原文差别较大;同时,我认为 Socket 通信较为底层,相关代码也会显得比较冗长,容易失去重点。为了简单起见,本文在同一机器上运行所有组件,它们之间的通信则使用 Python 内置的多进程队列(multiprocessing.Queue)。当然,这种实现的延展性较为有限:如果把各个组件分布到不同机器上,则该方法将无法工作。不过,我们可以使用一些外部队列,比如 zeromq、Redis 或 RabbitMQ 等等,代码只需稍作修改即可运行,它并不影响整体设计。
- Web 界面
好的持续集成服务通常需要提供 Web 界面(更完善的服务甚至会提供 IDE 插件),让开发者直观地看到构建是否成功,某些情况下也能对构建过程进行人为控制。遗憾的是,原文并未涉及到这个话题。本文尝试通过 Flask 实现一个基本的 Web Server,以展示构建结果。该服务不仅仅是以文本形式现实构建结果,同时还演示了如何去解析输出内容,以得到有用的、数字化的信息。比如说,对于单元测试而言,知道总共运行了多少测试、有多大比例成功或失败,都是非常有意义的信息,可以用来检视和评估开发进度,帮助团队根据现状实施更有效的项目管理————这是持续集成系统在更高层面上的意义。
如果你看过本文章系列前面几篇文章的话,会知道我通常会采用迭代式的方式描述开发过程。但本文的情况有点特别:它包含多个相对独立的组件,如果再用分步骤的写法会显得过于琐碎。因此,本文的顺序是:首先介绍项目的整体目标和设计方案,然后逐个分析各个组件的实现,不再划分开发阶段。
本文的持续集成系统会以 Python3 来实现,与此同时,要管理的目标也是一个用于演示的 Python3 项目。我们为目标项目设定如下要求:
- 项目用虚拟环境(
venv)来管理。持续集成系统需要尽可能支持多种不同类型的项目,因此项目的运行环境和持续集成系统本身的运行环境应该严格分开; - 我们有意在代码中留下一些不太好的代码风格问题,并用
pylint来检查它们; - 项目中也包含少量基于
unittest的单元测试。持续集成结果要检查测试执行的情况;
很多实际项目需要更加复杂的环境和执行步骤,但以演示目的而言,执行这些步骤已经足够让我们理解持续集成的工作原理了。
本项目使用这样的项目结构:创建一个单独的目录,比如 ~/test-ci,来存放目标项目,以及生成过程中的临时文件,这样可以方便以后清理它们。至于程序本身则放在哪里都没有关系。如果你希望使用其他目录结构的话,请在稍后的配置文件中修改相应的目录项。,这样,目录结构大致如下:
- ~/test-ci
我把示例项目的代码放在仓库的 ci/repo 目录下。为了避免弄乱源码,建议用以下命令把它拷贝到目标位置,并初始化 Git 仓库:
cp -R 500lines-rewrite/ci/repo/* ~/test-ci/repo
cd ~/test-ci/repo
git init .
git add *
git commit -m "initial commit."
如果你是在 Windows 下开发的话,也可以用文件管理器和 Git GUI 客户端完成以上步骤。
本文希望实现的是一个通用的持续集成系统。因此,服务应该做到对要构建的项目“一无所知”,而是让管理者通过配置来指定。实现配置最简单的方式是编写一个 JSON 文件:
{
"projects": [
{
"id": "project1",
"url": "$HOME/test-ci/repo",
"tasks": [
{ "type": "venv", "name": "venv", "packages-file": "requirements.txt" },
{ "type": "pylint", "pattern": "*.py" },
{ "type": "unittest", "params": "discover -s tests -p test*.py" }
]
}
],
"agents": [
{ "id": "agent1", "workDir": "$HOME/test-ci/agent1" },
{ "id": "agent2", "workDir": "$HOME/test-ci/agent2" }
]
}
你可以在源码的 ci/config.json 文件找到上述内容。
很容易看到,这个配置的主要内容包括:
- 定义了一个项目叫做
project1,其源码仓库的位置是$HOME/test-ci/repo。这里我们做了简化的假定:版本管理固定使用Git,且没有考虑用户验证的问题。支持多种版本控制系统和用户认证机制需要考虑很多其他方面的因素,我们这个演示项目就暂时不考虑了。 - 构建该项目需要三个步骤,分别是初始化虚拟环境、执行代码检查和单元测试。根据具体目标的不同,它们通常也有一些额外的参数。熟悉
Python的朋友不难猜到它们的具体用途; - 我们还定义了两个构建代理(
Build Agent),每个代理有自己单独的工作目录。构建代理的概念我们留到后面的部分再行阐述。
如果你看过原文的话,会知道它把系统实现为三个分离的组件,分别是:
- 监听器(
repo_observer) - 测试样例调度器(
dispatcher) - 测试运行器(
test_runner)
我对这个设计有一些不同的看法:
- 实际上,监听器(检测代码变更)和调度器(分配构建工作)执行需要的时间都应该是非常短暂的,并且这两者在时序上也存在着明确的依赖关系(如果没有变更,则调度器无事可做)。因此,把它们分成独立的进程似乎有点过度设计的嫌疑。只有构建工作需要比较长的时间,因此把构建任务独立出来是合理的;
- 作为通用的持续集成服务,它需要支持的不仅仅是执行测试,而应该包括其他各种相关任务,比如代码检查、编译、生成辅助文件、部署等等。因此,本文不是直接实现
Test Runner,而是把这些工作抽象为统一的概念,称为任务(Task),而测试只是其中一种任务; - 本文实现的持续集成服务还包括原文没有涉及的一个内容:展示给管理者/开发者的 Web 界面。因此,程序中还包括了 Web 服务器和相关的支持组件;
需要说明的一点是,我个人比较熟悉、也非常欣赏来自 JetBrains 公司的 TeamCity 这个持续集成工具,因此本文的部分术语也参考了它的叫法。如果你和我一样了解 TeamCity 的话,相信会对本文的实现感到亲切。
按照以上考虑,整个系统的结构设计如下:
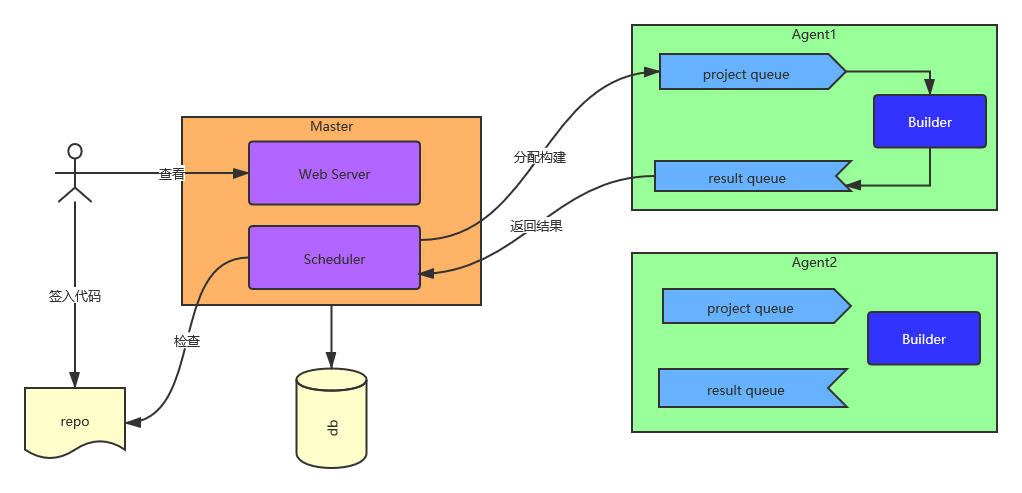
从部署角度讲,系统中主要包括两种进程:主进程(Master)和构建代理(Build Agent)。在最简单的场景下,代理可以只有一个并且和主进程合并,但在概念上应该允许同时部署多个 Agent。这是因为:
- 大型公司一般会有多个项目,并且有些项目的构建可能需要执行相当长的时间。我们知道持续集成的主要目的之一是尽快得到反馈,如果需要等待很长时间的话,反馈就失去了意义。因此,我们有必要让多个机器来承载不同的项目,避免项目堆积影响速度;
- 很多公司为了节省成本,持续集成服务使用的是比较老旧的机器,一台机器往往无法支持多个项目同时构建。但只要有多个机器可用,我们就可以让他们分担不同的项目,避免硬件性能原因造成构建失败;
- 我们处在一个多平台、多终端的时代,很多公司的产品都需要部署到不同的平台,包括 Windows、Linux、Mac、iOS、Android 等,而特定项目只有在适合自己的平台上才能编译。这在客观上也要求我们部署多个基于不同平台的构建代理,才能支持特定项目的构建工作;
- 在更高级的场景下,某些超大型项目甚至需要多个机器进行并行构建,有效节约时间(当然这需要更复杂的配置)。
主进程中又包括两个主要组件,分别是任务分派器(Scheduler)和 Web 服务(Web Server)。此外,主进程还需要记录并管理运行中的数据。我不希望给演示程序引入太多额外的复杂性,因此并未使用关系数据库或者 NoSQL,而是把运行数据保存在内存中。当然,这意味着程序结束后数据将无法保留。在真实的项目中,我们需要修改 models.py 中的代码,把它们改为真正的持久数据存储。
从运行角度理解,该系统的执行过程大致描述如下:
- 开发者在目标项目(
repo)中修改代码,并签入; Scheduler根据配置依次检查各个项目的代码库,一旦发现有新的签入,就选择一个合适的Agent,向其发送构建请求。Agent用内部队列(project queue)记录发送过来的构建请求。对每个请求,它启动一个构建线程(Builder Thraed)来执行构建。- 构建执行完毕后,线程会把输出内容放到
Agent内部的结果队列(result queue)中; Scheduler同时也会检查各个Agent的队列有无返回结果,如果有,则记录到数据库中;Web Server分析数据库中的构建结果,将内容渲染成网页内容,供用户查看。
这里存在一个设计上的权衡。单从系统结构上考虑的话,我们可以让主程序管理一个统一的结果队列,而不是每个 Agent 都维护自己的队列,这样似乎更加简单。但这样会造成 Master 和 Agent 的双向依赖:它们都要知道对方的信息,才能知道消息应该往哪里发送。我希望尽量避免形成这样的依赖,让Agent 成为单纯的工作者,不要依赖于 Master 的实现。当然,你对这种设计可以有不同的观点。
我们还需要设计一下程序运行所需的数据结构。目前,它们保存在内存中且统一由 Master 来管理,因此我们有很大的自由度;但为了贴近真实的场景,我们还是尽量按照数据库的概念来设计它们。一个项目(Project)包含多次构建的结果(Build Result),而每次构建结果又包含各个任务的执行结果(Task Result),因此它们都是一对多的关系:
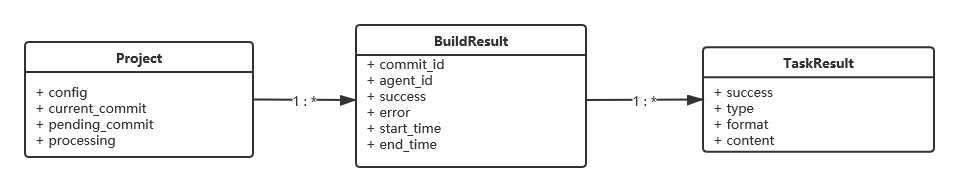
各个实体的主要字段说明如下:
- 项目:包含配置信息、当前提交序号和将要执行构建的提交序号(用于检查更新),以及是否正在构建的标志;
- 构建结果:包含提交序号、分配到的代理、是否成功、执行开始和结束的时间;
- 任务结果:包含任务类型、是否成功、输出格式和内容。
以上数据结构可以参考 models.py。
我们的服务从 main() 开始执行。它首先读取配置信息,并根据配置初始化数据库,然后启动主进程的组件:
def read_config():
config_path = os.path.join(os.path.dirname(__file__), 'config.json')
with open(config_path, 'r') as f:
return json.load(f)
def main():
config = read_config()
db = Database(config)
scheduler = Scheduler(config, db)
scheduler.start()
web_server = WebServer(db)
web_server.start()
调度器(Scheduleer)
为了避免互相阻塞,Scheduler 和 Web Server 运行在分离的线程中,因此它们都从 Thread 派生。Scheduler 也负责根据配置启动相应的 Agent(这是为了减轻手工启动进程的负担。真实环境中的 Agent 可能需要独立部署):
class Scheduler(Thread):
def __init__(self, config, db):
super().__init__()
self.config = config
self.db = db
self.agents = [self.start_agent(x) for x in config["agents"]]
def start_agent(self, config):
agent = Agent(config)
p = mp.Process(target=agent, daemon=True)
p.start()
return agent
这里有个有趣的地方:按道理,Process 初始化的 target 应该是个函数,但 Agent 本身也有复杂的逻辑,为了组织代码,我把它实现为一个类。Python 语言一个独特且优雅的优点就是:只要类实现了 __call__ 协议方法,它就可以像普通函数一样被调用。Agent 的代码我们在后续部分讲解。
def run(self):
while True:
for project in self.db.projects:
self.detect_change(project)
for agent in self.agents:
self.detect_result(agent)
time.sleep(10)
Scheduler 的重要工作就是不断检查各个项目有无变更,同时也要看看各个 Agent 有没有返回结果。有的同学可能会担心这样做效率不高,其实不然,检查代码变更或者记录返回结果正常情况下都是很轻量级且非常快速的操作,我们不必担心它们的效率问题。当然,如果你愿意的话,也可以把这段代码改为可以并发执行的。
def detect_change(self, project: Project):
if project.processing:
return
commit_id = vcs.get_last_commit_id(project.config['url'])
if commit_id != project.current_commit:
project.pending_commit = commit_id
agent = self.choose_agent(project)
agent.schedule(project)
def choose_agent(self, project: Project):
return random.choice(self.agents)
我们使用了一个辅助模块 vcs,它在内部调用了第三方库 pygit2 来处理 Git 相关的操作。这是和原文的另一个不同之处:原文采用的方法是通过 shell 调用系统的 git 程序。由于调用外部程序有时会出现一些不可控的结果,我个人更加偏好通过模块来实现,当然这是个人口味问题。因为项目的构建通常需要比较长的时间,如果某个项目正在构建的话,我们就把它标记为正在处理,只有构建完毕后才会执行新的检测。
choose_agent() 方法的职责是根据项目的具体情况选择合适的构建代理。对于一个完善的持续集成服务而言,我们可能需要考虑代理的负载、可用性、目标平台兼容性等一系列问题,但这些对 500 行的演示程序而言显得有些过于复杂了。这里我选择一个在大多情况下效果不错的简单策略:随机分配到某个目标代理(只要兼容即可)。
至于 detect_change() 则是简单的记录返回结果到数据库,这里就不再列出具体实现了,大家可以直接参考源码。
构建代理(Agent)
Agent 也是一个线程,它的主要工作就是不断检测队列中是否存在新的构建请求。如果有,则启动一个项目构建器(ProjectBuilder)来执行它:
class Agent:
def __init__(self, config):
self.config = config
self.project_queue = mp.Queue()
self.result_queue = mp.Queue()
def workDir(self) -> str:
return os.path.expandvars(self.config["workDir"])
def schedule(self, project: Project):
project.processing = True
self.project_queue.put(project)
def __call__(self, *args, **kwargs):
while True:
project = self.project_queue.get()
builder = ProjectBuilder(self, project)
builder.start()
项目的构建需要保留许多上下文数据,因此我用一个类 ProjectBuilder 来处理。它的主要执行步骤可以归纳如下:
- 创建一个临时目录,并把代码 clone 到该位置
- 依次执行各个构建任务(Task)
- 清理环境并返回结果
实现代码:
class ProjectBuilder(Thread):
...
def run(self):
self.work_dir = os.path.join(self.agent.workDir(), uuid.uuid4().hex)
try:
vcs.clone(self.project.config["url"], self.work_dir, commit_id=self.project.pending_commit)
for task_config in self.project.config["tasks"]:
self.run_task(task_config)
except Exception as e:
self.result.fail(e)
finally:
shutil.rmtree(self.work_dir)
self.result.finish()
self.agent.result_queue.put(self.result)
这里 run_task() 方法负责执行特定的任务,同时它也是系统中一个主要的扩展点。我们的演示程序支持 venv/pylint/unittest 三种任务。如果要支持新的任务类型,只要实现它们并注册到这里即可:
def run_task(self, config: dict):
task_type = config['type']
runner_type = {
'venv': run_venv,
'pylint': run_pylint,
'unittest': run_unittest,
}
runner = runner_type[task_type]
result = runner(self, config)
if result:
result.type = task_type
self.result.tasks.append(result)
我们将执行各个任务的方法设计成统一的函数结构,它需要两个参数,分别是所属的构建器和任务配置,原型如下:
def task_runner(builder: ProjectBuilder, config: dict): ...
如果考虑到扩展性,为了支持某些比较复杂的任务,我也许应该把它们设计为抽象类。事实上,一开始我确实是这么做的,但实现之后发现我们的任务都非常简单,以至于写一个类似乎有点复杂过度了,所以又改成了函数。作为例子,我们看看单元测试任务是如何执行的。如果你还记得测试文件的话,应该回忆起该任务包含一些额外的参数,以规定单元测试的具体行为:
def run_unittest(builder, config: dict) -> TaskResult:
venv_name, params = builder.venv_name, config["params"]
output = builder.run_cmd(f"{venv_name}/bin/python -m unittest {params} 2>&1")
return TaskResult('unittest', output)
ProjectBuilder 包含一个辅助方法 run_cmd 来执行外部程序,并返回输出到 stdout 的内容。这段代码相当于执行命令 venv/bin/python -m unittest discover -s tests -p test*.py 2>&1(参数细节请参考 unittest 文档)。大家应该注意到了一个小细节,就是命令最后的 2>&1 特殊语法,它会将输出到标准错误(stderr)的内容重定向到标准输出(stdout)。这是我在实现过程中发现的:unittest 会把结果输出到 stderr,如果你只是捕获 stdout 的话,那么什么内容都得不到。这也告诉我们,在实现持续集成服务的过程中,很大一部分工作是通过试验确定各种任务在执行时的行为,并作出相应的处理(当然这也是一个比较琐碎的工作)。
Web Server
Web Server 本身的工作是比较简单的。本文使用轻量级的 Flask 作为 Web 服务器:
class WebServer(Thread):
def __init__(self, db: Database):
super().__init__()
self.db = db
def run(self):
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html',
projects=self.db.projects)
app.jinja_env.globals['render_task_result'] = render_task_result
logging.getLogger('werkzeug').setLevel(logging.ERROR)
app.run()
我们提高了服务器的请求日志级别,因为这个简单的 Web 应用并没有什么需要调试的,而请求的日志信息比较多且容易打乱 Scheduler 的输出内容。另外一个要点是 render_task_result 方法:为了更好的呈现构建结果,我们需要分析构建的输出信息,而不只是简单的呈现它。
render_task_result 也是一个重要的扩展点。我们可以根据要求实现多种解析器,以支持特定任务的输出结果解析:
class ArtifactHandler:
def parse(self, text: str) -> object:
raise NotImplementedError()
def render(self, model: object) -> str:
raise NotImplementedError()
def render_task_result(result: TaskResult) -> str:
handlers = {
'pylint': PyLintHandler,
'unittest': UnitTestHandler,
}
handler = handlers[result.type]()
model = handler.parse(result.content)
return handler.render(model)
ArtifactHandler 是一个抽象类,定义所有工件(Artifact)的行为。它的实现是一个两步骤的过程:
- 把任务输出结果解析成特定的数据格式;
- 把数据格式渲染为 HTML。
作为例子,我们看看如何解析单元测试的输出。Python 的单元测试模块 unittest 输出的首行是各个测试用例的结果,每种结果表示为一个字符:. 成功,E 错误(Error),F 失败(Failure)。后面通常会带有错误和失败的详细信息。一个可能的结果示例如下:
......F...EF..............E...
基于此,单元测试解析的实现如下:
class UnitTestHandler(ArtifactHandler):
def parse(self, text: str) -> object:
result = UnitTestResult()
first_line = text.splitlines()[0]
for ch in first_line:
if ch == '.':
result.pass_count += 1
elif ch == 'E':
result.error_count += 1
elif ch == 'F':
result.fail_count += 1
return result
def render(self, model: UnitTestResult) -> str:
return f"<b>{model.pass_count}</b> Passed, <b>{model.fail_count}</b> failed, <b>{model.error_count}</b> Error."
考虑到解析复杂文本比较容易出错,为了避免要修正这些错误而反复重启程序,我也为这些代码编写了相应的单元测试。你可以在代码的 ci/tests 下面看到这些测试。
如果一切正常的话,启动程序,稍等片刻,你应该在控制台看到类似这样的内容:
Project project1 with commit f55877c1ef7d80019ad01d029b2e7e4cc0282d06 scheduled to agent1
agent1 got build result: BuildResult(project=project1, commit=f55877c1ef7d80019ad01d029b2e7e4cc0282d06)
Project project1 end build, commit=f55877c1ef7d80019ad01d029b2e7e4cc0282d06
这就表明一次构建已经完成了。现在我们打开浏览器并指向 http://localhost:5000,应该看到这样的输出:

当然这是一个非常非常基础的页面。要让它变得更为美观和丰富的话,我们可能需要一个专业的前端...(一个 500 行的程序就不要要求太多了)
你也可以尝试对 repo 中的代码稍作修改,并重新提交。Scheduler 每隔 10 秒钟就会重新检测,因此你应该很快看到新的构建信息,刷新页面即可看到新的结果。祝贺,我们已经完成了一个具备基本功能、且非常容易扩展的持续集成服务器!
如果要作为真正可用的持续集成服务器,我们的代码至少还存在两个重大问题:第一,需要把 db.py 定义的模型修改为基于真正的数据库实现;第二,要把 multiprocessing.Queue 修改为外部的独立队列,才能实现跨机器的部署。
我们也看到,实现一个持续集成服务从概念上来讲并不困难。比较麻烦的是支持各种形形色色的任务、并且要解析它们的输出结果,同时还要考虑到它们在各种环境下可能出现的错误,这是非常琐碎的工作,我们也需要为可能的异常做好准备。本文实现的服务在错误处理方面并不是特别健壮;当然,我也不希望把演示代码搞得过于复杂。如果读者愿意的话,也可以从自己的角度,看看该服务还有哪些地方可以完善。
如果大家对这个简单的项目觉得不够满足的话,也可以参考现实的项目。持续集成最经典的系统当然要算 Jenkins,但这也是一个非常复杂的项目。相信本文的读者应该大多是 Python 程序员,那么也有一些相对简单的项目可供参考,比如 Buildbot。或者你也可以浏览其他人整理的、比较完整的列表 Awesome CI,看有没有自己感兴趣的项目来学习(甚至参与!)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK